Understanding the Differences Between Normalization and Standardization of Data
 Akash Kumar
Akash Kumar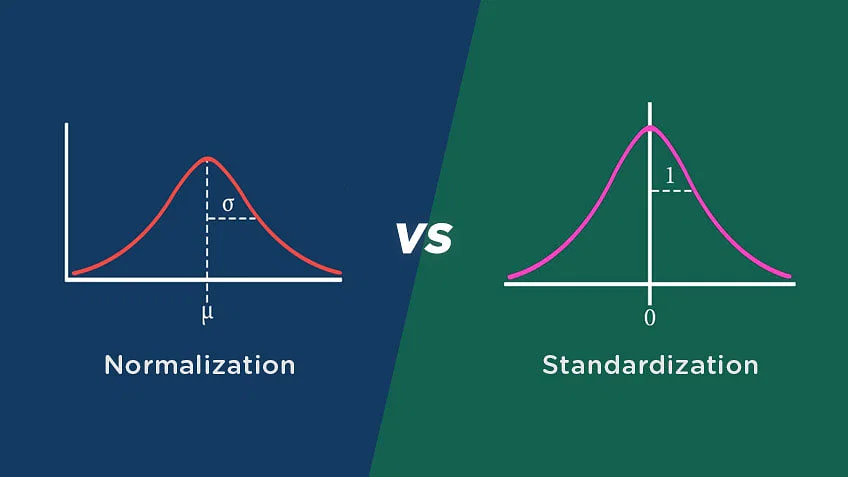
In data analysis, normalization and standardization are two common techniques used to prepare data for further analysis or modeling. The purpose of both techniques is to convert numerical data to a common scale to eliminate the effects of differences in measurement units and to facilitate the interpretation and comparison of the data. However, there are some differences between the two techniques in terms of their goals, methods, and applications.
Normlization VS Standardization
Normalization refers to the process of rescaling the data to a range of 0 to 1. This technique is used when the scale of the data varies widely, and the actual values are not as important as their relative values. Normalization ensures that each variable contributes equally to the analysis, regardless of its original scale or magnitude. This method is also useful when dealing with features of different units and scales, as it makes them more comparable.
Normalization
To normalize a dataset, we need to subtract the minimum value of the variable from each value and then divide the result by the range of the variable (i.e., the difference between the maximum and minimum values). As an example, we can normalize a dataset of ages ranging from 20 to 60 by subtracting 20 from each age, and then dividing the result by 40 (the range of the variable). This will produce a new dataset with values ranging from 0 to 1, where 0 represents the minimum value, and 1 represents the maximum value.
Standardization, on the other hand, involves transforming the data to have a mean of 0 and a standard deviation of 1. This technique is used when the scale of the data is not known, or when the data is normally distributed. For data with a wide range of values, standardization is helpful when units of measurement are not as important as their relative positions. Standardization helps to make the data more interpretable and easier to compare, by transforming it to a standard scale.
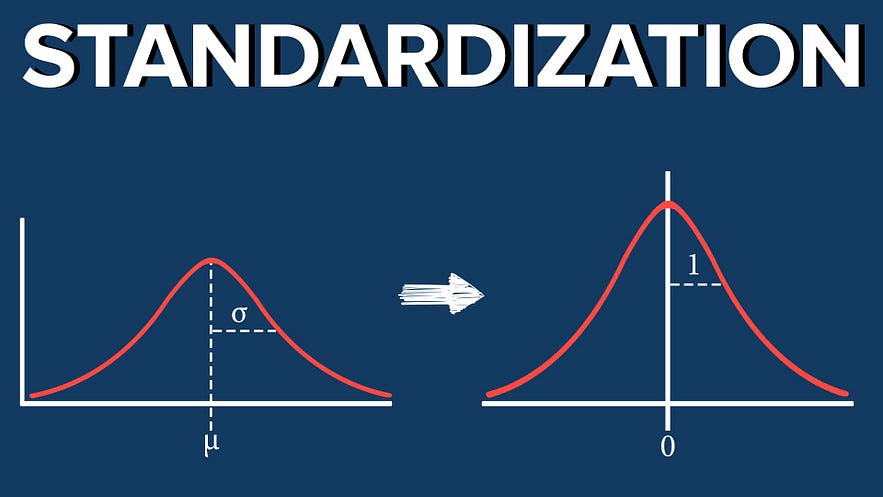
Standardization
To standardize a dataset, we need to subtract the mean of the variable from each value and then divide the result by the standard deviation of the variable. For example, if we have a dataset of heights ranging from 150 cm to 190 cm, we can standardize the data by subtracting the mean height (i.e., the average height) from each height value, and then dividing the result by the standard deviation of the heights. In this way, we will produce a new dataset with values that are meanless and have a standard deviation of 1.
Comparing normalization and standardization, we can say that normalization is used to rescale data to a specific range, while standardization is used to transform data to a standard scale. Normalization is useful when dealing with variables of different units and scales, while standardization is useful when dealing with variables that are normally distributed. Machine learning algorithms can benefit from both techniques, especially when dealing with numerical data.
In conclusion, normalization and standardization are two common techniques used in data analysis to transform data to a common scale. While they have some similarities, they also have some differences in terms of their goals, methods, and applications. The choice of which technique to use depends on the nature of the data and the specific requirements of the analysis.
Subscribe to my newsletter
Read articles from Akash Kumar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Akash Kumar
Akash Kumar
As a skilled data analyst and machine learning practitioner, I have worked on various projects in Kaggle using Python and other analytical tools. For me, working with data is not just a profession but a passion, and I enjoy exploring and discovering insights hidden in data sets. With expertise in Advanced Excel, Machine Learning, Power BI, Data Analysis, SQL, MongoDB, and Business Administration, I have a comprehensive understanding of data-driven decision-making, which enables me to deliver valuable insights and solutions to complex business problems. I hold a Bachelor's degree in Business Administration, with a focus on marketing and financial analysis, from Tula's Institute, and I am currently pursuing my Data Science course from IIT Madras, which has enhanced my technical skills in data science and machine learning. As a strong entrepreneur, I have a proven track record of delivering projects that meet or exceed expectations, and I am committed to continuous learning and growth to stay ahead in the field of data science. Thank you for taking the time to read my profile, and I look forward to connecting with like-minded professionals in the industry.