Data Encoding a normalization techniques in machine learning
 Akash Kumar
Akash Kumar
Data encoding is an essential aspect of machine learning that involves converting data into a format that can be easily understood by algorithms. To identify patterns and make predictions, machine learning models use data encoding to convert raw data into numerical representations.

In this article, we will discuss the different methods of data encoding used in machine learning and their advantages and disadvantages.
One-Hot Encoding: One-hot encoding is a technique used to transform categorical data into numerical data. In one-hot encoding, each categorical variable is converted into a binary vector, where each category is represented by a single binary digit. For example, suppose we have the variable “color” with three categories (red, green, and blue). Using one-hot encoding, each category is converted into a binary vector, with red being represented as [1, 0, 0], green as [0, 1, 0], and blue as [0, 0, 1]. This method is commonly used in deep learning and neural networks.
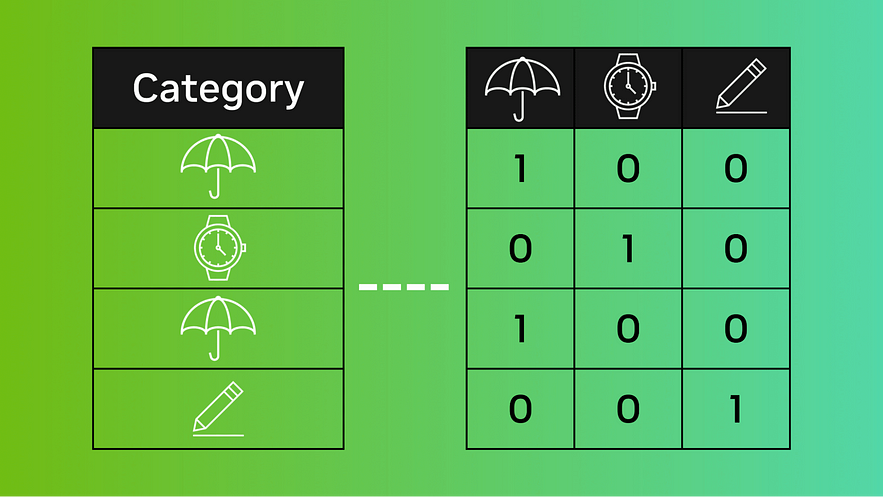
Advantages:
One-hot encoding can handle multiple categories in an unbiased manner towards any particular category.
It is a simple and efficient method of transforming categorical data into numerical data.
Disadvantages:
One-hot encoding can lead to a high-dimensional dataset, which can cause issues with storage and computational resources.
It can also create sparsity in the dataset, making machine learning algorithms difficult to identify patterns.
Label Encoding: Label encoding is another method for transforming categorical data into numerical data. Label encoding assigns each category a unique integer value. For example, suppose we have a categorical variable “color” with three categories (red, green, and blue). In that case, the label encoding process would assign integer values 1 to red, 2 to green, and 3 to blue.
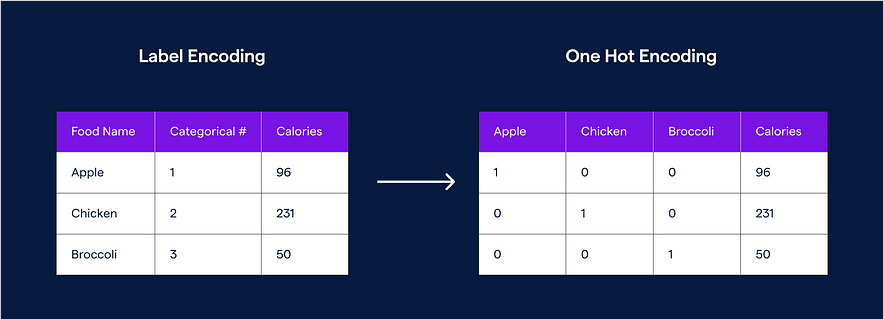
Advantages:
For converting categorical data to numerical, label encoding is an efficient and simple method.
It can handle large categorical datasets without creating high-dimensional datasets.
Disadvantages:
Label encoding can create order bias, where the integer values assigned to each category can influence the machine learning algorithm’s output.
It can also create difficulties when comparing categories, as the integer values do not necessarily represent the actual relationship between the categories.
Binary Encoding: Binary encoding transforms categorical data into binary values. Binary encoding assigns binary codes to each category, each representing a power of two. For example, suppose we have a categorical variable “color” with three categories (red, green, and blue). In that case, the binary encoding process would assign the binary code 001 to red, 010 to green, and 100 to blue.

Advantages:
Binary encoding can handle large categorical datasets without creating high-dimensional datasets.
It can create a compact representation of categorical data, making it efficient for storage and computation.
Disadvantages:
Binary encoding can cause difficulties interpreting the relationship between categories.
It can also create bias towards certain categories, as the binary code assigned to each category can influence the machine learning algorithm’s output.
Conclusion: Data encoding is an important step in machine learning that involves converting raw data into a numerical format algorithms can understand. Three of the most common methods of data encoding are one-hot encoding, label encoding, and binary encoding. The choice of method depends on the specific requirements of the machine learning problem, as each method has its advantages and disadvantages.
Subscribe to my newsletter
Read articles from Akash Kumar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Akash Kumar
Akash Kumar
As a skilled data analyst and machine learning practitioner, I have worked on various projects in Kaggle using Python and other analytical tools. For me, working with data is not just a profession but a passion, and I enjoy exploring and discovering insights hidden in data sets. With expertise in Advanced Excel, Machine Learning, Power BI, Data Analysis, SQL, MongoDB, and Business Administration, I have a comprehensive understanding of data-driven decision-making, which enables me to deliver valuable insights and solutions to complex business problems. I hold a Bachelor's degree in Business Administration, with a focus on marketing and financial analysis, from Tula's Institute, and I am currently pursuing my Data Science course from IIT Madras, which has enhanced my technical skills in data science and machine learning. As a strong entrepreneur, I have a proven track record of delivering projects that meet or exceed expectations, and I am committed to continuous learning and growth to stay ahead in the field of data science. Thank you for taking the time to read my profile, and I look forward to connecting with like-minded professionals in the industry.