Understanding the Evolution of Observability: A Historical Overview
 Vishruth Harithsa
Vishruth Harithsa
In this glorious age, when layoffs outnumber births by a wide margin. Due to the worldwide economic downturn, many people risk losing their jobs. As a result of a domino effect that began with COVID-19, we now observe this behaviour. Work-from-home policies paved the way for workers to adjust to a new normal, and as a result, they had more time on their hands to be creative and develop new ideas. Naturally, these endeavours were connected to cutting-edge movements.
AI is currently the most popular topic among online users. Consequently, greater automation has begun, prompting employers to reevaluate the need for some positions and raise questions about the value of their employee’s compensation.
Despite these shifts, observability and security are two fields that have not only been unaffected by the rise of the cloud but are expanding rapidly as a direct result. For this series titled “The Road to Observability,” let’s discuss the origins of observability and its subsequent development in this article.
How it all started?
It all started with Telemetry:
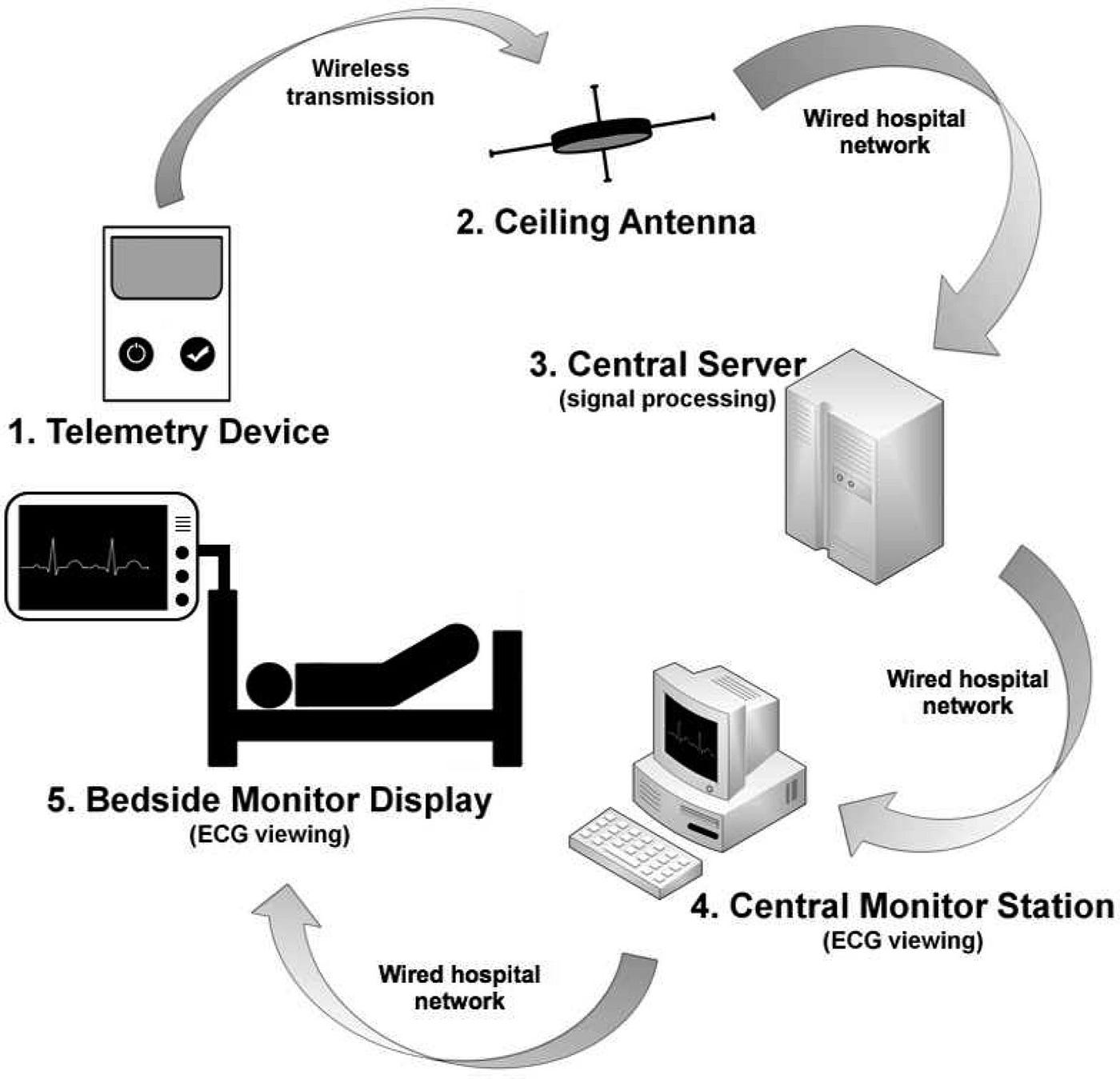
Early 20th-century rocket development and space flight used telemetry. Telemetry was used to track rockets and weapons to study the universe during the Cold War.
Sputnik 1, the first artificial satellite launched into orbit in 1957, was the first space exploration mission to utilise telemetry. Sputnik 1 relayed telemetry data to Earth, allowing its location and space conditions to be followed.
Telemetry is used in military aircraft, missiles, and aerial vehicles. Telemetry data is used to monitor systems and make decisions.
Wireless communications, satellite networks, and the Internet of Things have helped telemetry increase (Internet of Things). Telemetry monitors and controls equipment, systems, and processes in numerous fields. This encompasses aerospace, defence, automotive, industrial automation, and the Internet of Things (IoT).
Since now you understand why telemetry is used, you can also understand where this term came from. It was derived from the Greek in which tele means remote, and metron means to measure.
Observability?
The ability to infer the internal state of a system from measurements of its outputs is known as observability. The concept of observability has its origins in the early days of computer science and control systems engineering.
Mathematical models and techniques for understanding and regulating complex systems, such aeroplanes and manufacturing processes, were created by control systems engineers in the 1950s and 1960s. These methods, collectively referred to as “control theory,” are predicated on the concept of using sensor data to deduce the internal state of a system and acting accordingly.
The 1960s saw the emergence of new methodologies in computer science for studying the dynamics of complex systems like computer networks and distributed software. These methods were developed on the premise that monitoring data may be used to infer the internal state of a system and aid in problem diagnosis and resolution.
For the first time in the late 1990s, the term “observability” was used to the realm of distributed systems and computer networks. Etsy’s John Allspaw and Paul Hammond popularised the term “observability” in the area of IT operations in 2003. Its meaning has since expanded to encompass the ability to infer the underlying state of complex systems from their observed behaviour.
As a means of monitoring, troubleshooting, and diagnosing issues in large, complex systems, observability has found widespread usage in the context of distributed systems, cloud computing, and microservices in recent years. New tools and approaches, such as distributed tracing, metrics, and logging, have been developed in the field of observability to make it easier to watch and comprehend the internal state of systems.
How telemetry aids in determining infrastructure observability for businesses?
Finding observability in complicated systems has been greatly aided by telemetry. Telemetry allows engineers and operators to check in on the health, performance, and position of a system from a central place by collecting and transmitting data from distant sources. This enables them to draw conclusions about the underlying system state and respond accordingly.
Distributed systems, cloud computing, and microservice architectures are all examples of complex systems that might benefit from telemetry data for analysis and problem solving. Telemetric data can be mined for useful insights about how to best run a business or improve upon existing practises.
Organizations can also use telemetry data to set up automated alerts and notifications when specific events occur, such as abnormal changes in system behaviour.
Through the use of telemetry, observability can also be attained through the deployment of monitoring tools and techniques such distributed tracing, metrics, and logging. Using these instruments, telemetry data can be gathered and analysed, and the internal workings of systems can be observed and understood with greater ease.
Telemetry’s ability to collect and transmit data from remote sources, which may be utilised to monitor and comprehend the internal state of a system, has been crucial in the search for observability in complex systems.
Tools and Trends of Observability
Several methods and developments are in use right now to make complicated systems more observable. The following are examples of some of the most well-liked resources and developments:
Distributed tracing is a method for following a request as it travels across a network. It reveals the entire journey of a request, from the request to the response, and helps you comprehend the interplay between the many components of a system.
Metrics are a tool to evaluate the efficiency and functionality of a system. Metrics can be used to check on the state of a system, zero in on any potential slowdowns, and keep tabs on any relevant KPIs (KPIs).
The term “logging” refers to the process of collecting and archiving system logs. In addition to helping with problem diagnosis and resolution, log data can shed light on how a system is being utilised.
APM, or Application Performance Management, is a system for keeping tabs on and adjusting how well your apps are running. Individual request performance may be monitored, bottlenecks can be located, and issues can be diagnosed with the help of APM tools.
Synthetic monitoring is a method for simulating user interactions with a web application in order to verify its availability and performance. It may be used to track how well your web apps are doing, detect problems as they occur, and fix them quickly.
This is where anomaly detection comes in; it’s a method for picking out out-of-the-ordinary occurrences in your data. This can be put to use in order to monitor your system for any potential faults and alert you as soon as a problem is found.
It’s no surprise that containerization and Kubernetes are gaining traction in the observability community; by streamlining the deployment and management of complicated systems, they’re reducing the associated friction. Kubernetes enables you to easily and quickly automate application deployment, scaling, and management, as well as the administration of the underlying infrastructure.
AI-based observability: AI-based observability solutions are growing in popularity because they enable businesses to automatically detect and diagnose problems, identify abnormalities, and anticipate emerging issues and trends.
By providing a means to collect and evaluate data and gain insight into a system’s internal state, these developments and technologies are together easing the path to observability in complex systems.
Conclusion
Before, observability was mostly used to the aerospace and defence industries; now, it’s employed in distributed systems, cloud computing, and microservices. Companies can optimise their operations, boost their performance, and maintain system stability by employing the observability technique, which has become increasingly important as the amount of data provided by these systems grows.
This complex systems gave rise to enterprise cloud which we will discuss in my next article. If you want to know about the basics of Cloud Computing here is an article that helps you understand.
Subscribe to my newsletter
Read articles from Vishruth Harithsa directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Vishruth Harithsa
Vishruth Harithsa
Expert in all things computer-related, from software design to project management, with nearly a decade of relevant experience. Working for Dynatrace as a system monitor and observability enthusiast. Also active on podcasts and YouTube, where he provides advice on technology and professional development. When I'm not at work, the one thing I enjoy the most is spending time with my best friend and my computer.