Tackling Imbalanced Data in Machine Learning: Techniques for Accurate Predictions
 Saumya Gupta
Saumya Gupta
Introduction
Imagine you have a bag of different coloured balls - red, blue, and green. Now, imagine that you have 10 red balls, 5 blue balls, and only 1 green ball. This means that you have more red balls than blue balls and much fewer green balls. We call this an imbalanced collection of balls.
Similarly, when we talk about imbalanced data in machine learning, we mean that the amount of data for one class (like the red balls) is much higher than the other classes (like the blue and green balls). For example, let's say we want to train a machine learning model to identify pictures of dogs and cats. If we have 1000 pictures of dogs and only 10 pictures of cats, we have an imbalanced dataset.
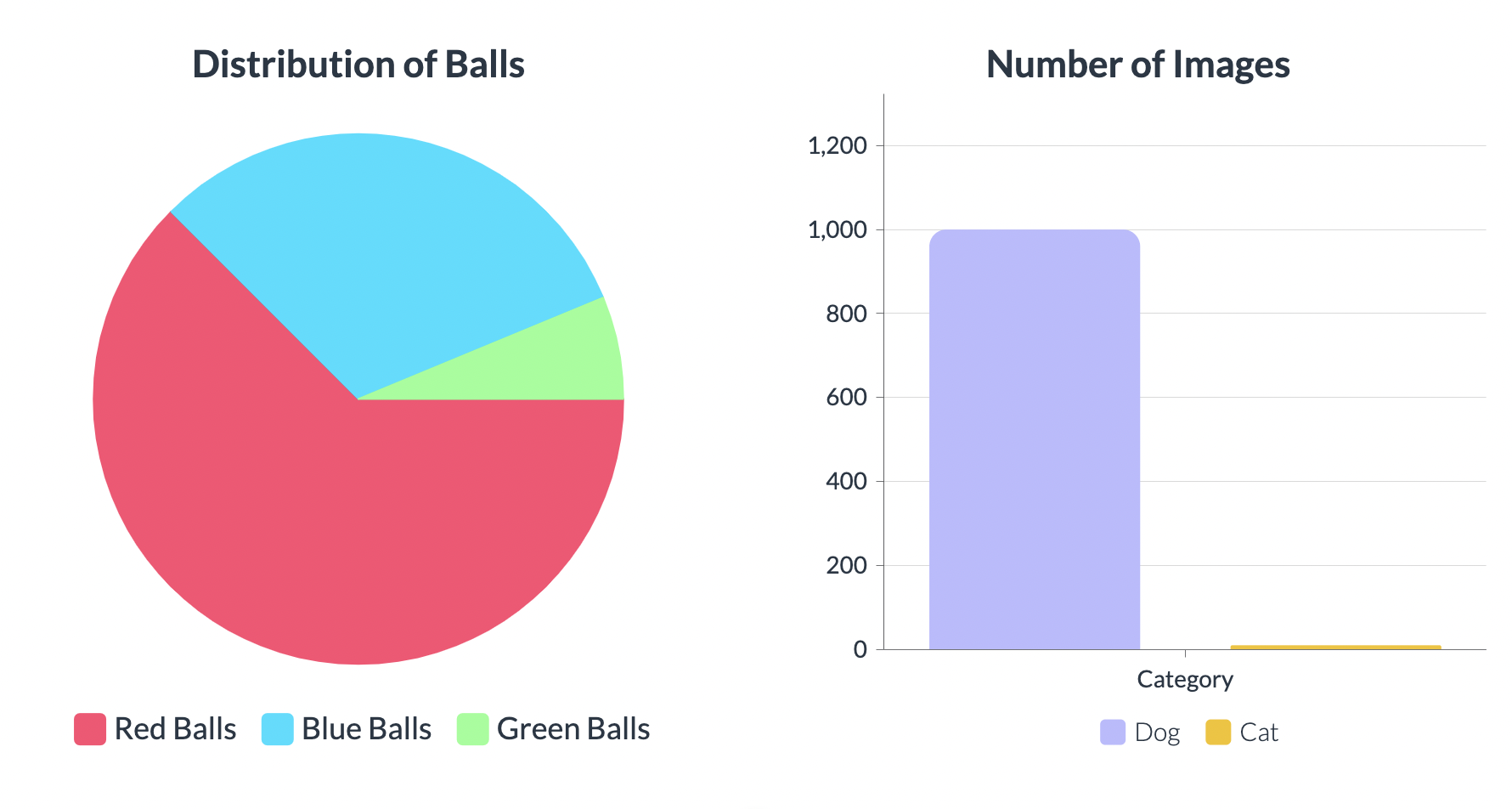
This is a problem in machine learning because the machine learning model may not learn to recognize the underrepresented class well. In the example of the dogs and cats pictures, the machine learning model may learn to recognize dogs well but not be able to recognize cats as accurately. This is because the model is biased towards the overrepresented class of dogs. Imbalanced data can cause problems in many different types of machine learning problems, such as fraud detection, medical diagnosis, and customer churn prediction.
In this blog post, we will explore different techniques for handling imbalanced data in machine learning and discuss common strategies such as undersampling and oversampling, as well as hybrid approaches. We will also examine evaluation metrics that are used to determine the performance of the model on imbalanced data. By the end of this post, you will have a better understanding of how to handle imbalanced data in your own machine learning projects and ensure accurate predictions for all classes, not just the overrepresented ones.
Understanding the Challenges of Imbalanced Data
Imbalanced data is a situation where the number of observations in one class is significantly higher or lower than the number of observations in other classes. In other words, the data is not distributed equally among all classes, resulting in one or more classes being underrepresented or overrepresented. For instance, consider a credit card fraud detection model, where the percentage of fraudulent transactions is relatively low compared to non-fraudulent transactions. This would result in imbalanced data, with a small number of fraud cases and a large number of non-fraud cases.
There are several reasons why imbalanced data exists. In some cases, the imbalance occurs naturally in the data, such as in the case of medical diagnosis where some rare diseases occur less frequently than others. In other cases, the data may be collected in a biased manner, where the sampling method or data collection process is not representative of the entire population. For instance, consider a survey on customer satisfaction where only happy customers respond, and unhappy customers are less likely to respond, resulting in imbalanced data.
Imbalanced data poses several challenges for machine learning models. One of the main challenges is that the models tend to be biased towards the overrepresented class. This happens because the models learn to optimize the overall accuracy, and since the overrepresented class has more data, the model focuses on it more. This can result in poor performance on the underrepresented class, which is often the class of interest. In addition, the evaluation of models on imbalanced data is tricky, as traditional evaluation metrics such as accuracy can be misleading. Therefore, specialized evaluation metrics such as precision, recall, and F1 score are used to evaluate models on imbalanced data.
Common Strategies for Handling Imbalanced Data
As we have learned in the previous sections, imbalanced data can pose significant challenges in machine learning, leading to poor performance and biased results. In this section, we will explore various techniques for handling imbalanced data, such as undersampling, oversampling, and hybrid approaches.
Reducing the Majority: Undersampling Methods
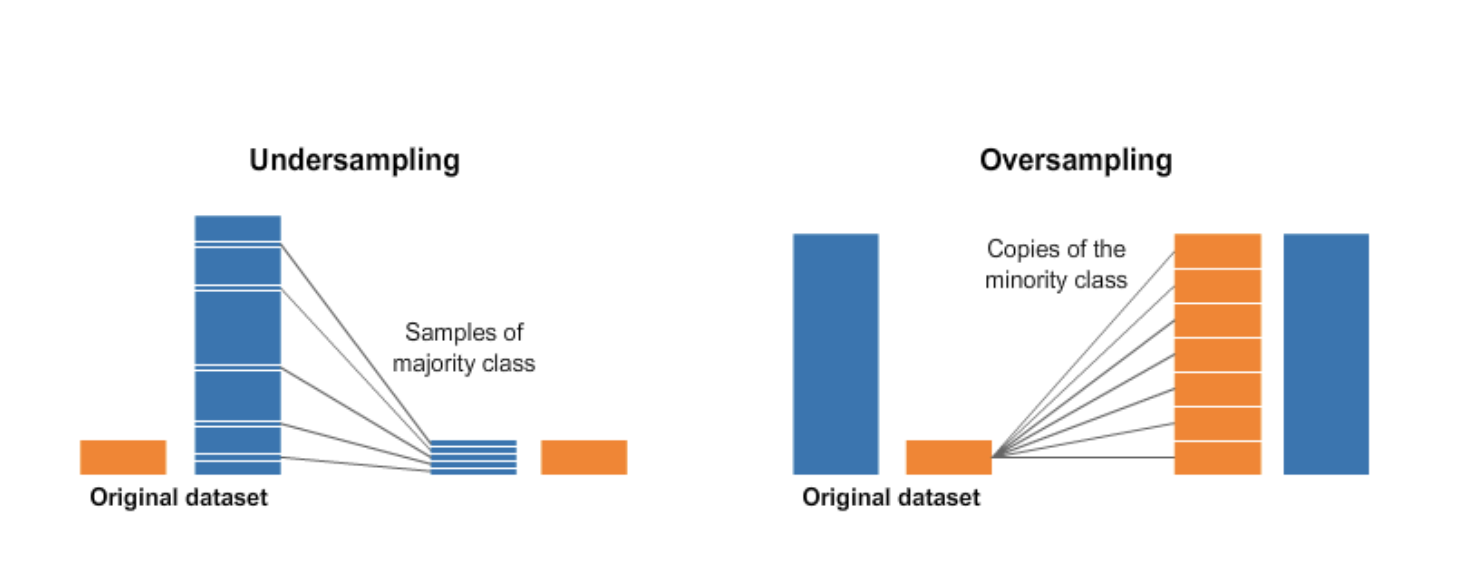
Undersampling is a technique for handling imbalanced data that involves reducing the number of instances in the majority class. By reducing the size of the majority class, undersampling can help to balance the distribution of the classes and improve the accuracy of a machine learning model. There are several undersampling techniques that are commonly used:
Random Undersampling: This technique involves randomly selecting a subset of instances from the majority class. For example, if we have 100 instances in the majority class and 20 in the minority class, we might randomly select 20 instances from the majority class to create a balanced dataset. The advantage of random undersampling is that it is simple to implement and can be effective for small datasets. However, it can also result in the loss of important information and may not work well for large datasets.
NearMiss Undersampling: This technique involves selecting instances from the majority class that are closest to the minority class. For example, if we have two clusters in the majority class and one in the minority class, we might select instances from the majority class cluster that is closest to the minority class. The advantage of NearMiss is that it can be effective for large datasets and can preserve important information. However, it may not work well if the clusters in the majority class overlap with the minority class.
Tomek Links Undersampling: This technique involves removing instances that are located at the boundary between the majority and minority classes. For example, if we have two instances that are closest to each other, one from the majority class and one from the minority class, we might remove the instance from the majority class to create a balanced dataset. The advantage of Tomek Links is that it can improve the performance of machine learning models that are sensitive to noisy data. However, it may also result in the loss of important information and may not work well for large datasets.
Cluster Centroids Undersampling: This technique involves generating artificial instances for the majority class by clustering the instances in the majority class and then creating new instances at the centroids of the clusters. For example, if we have two clusters in the majority class, we might create two new instances at the centroids of the clusters to create a balanced dataset. The advantage of Cluster Centroids is that it can preserve important information and can be effective for large datasets. However, it may also result in the loss of important information if the clusters in the majority class are not well-defined.
In summary, undersampling techniques can be effective for handling imbalanced data, particularly for small to medium-sized datasets. However, they can also result in the loss of important information and may not work well for large datasets. It is important to evaluate the performance of different undersampling techniques on a specific dataset to determine which technique works best.
Boosting the Minority: Oversampling Methods
Oversampling is a technique used to handle imbalanced data by creating synthetic samples of the minority class to balance the class distribution. The main advantage of oversampling includes an increase in the size of the dataset, preservation of the original distribution of the data, and potential improvement in the performance of the machine learning model. Oversampling also ensures that no information is lost by removing samples, as in undersampling.
Random oversampling: In this technique, the minority class samples are randomly duplicated until the class distribution is balanced. Random oversampling is easy to implement and computationally efficient, but it can lead to overfitting and poor generalization performance on new data.
SMOTE (Synthetic Minority Over-sampling Technique): As mentioned earlier, SMOTE creates synthetic samples by selecting similar minority samples and introducing random perturbations. This technique can effectively balance the class distribution, and it is less prone to overfitting than random oversampling. To balance the class distribution, we can use oversampling techniques such as SMOTE. In SMOTE, new synthetic samples are created by selecting similar minority samples and introducing random perturbations. For instance, we can randomly select a fraudulent transaction and create a new synthetic sample by selecting one of its k nearest neighbours and perturbing its features within a certain range. This process is repeated until the minority class is over-sampled to a desired level.
However, the disadvantages of oversampling are that it can increase the risk of overfitting the model, as it creates exact replicas of existing data. This can lead to poor generalization performance on new data. Oversampling can also be computationally expensive and time-consuming, especially when dealing with large datasets. Another issue is that it can generate noisy samples that do not accurately reflect the underlying distribution of the minority class.
The Best of Both Worlds: Hybrid Approaches
Hybrid approaches are a combination of two or more undersampling and oversampling techniques, which aim to maximize the benefits of both approaches and mitigate their drawbacks. Here are a few examples of hybrid approaches:
SMOTE + Random Oversampling: In this approach, we first use SMOTE to oversample the minority class. Then, we apply Random Oversampling to further increase the size of the minority class.
NearMiss + SMOTE: In this approach, we first use NearMiss to undersample the majority class. Then, we apply SMOTE to oversample the minority class.
Random Undersampling + Cluster Centroids: In this approach, we first use Random Undersampling to reduce the size of the majority class. Then, we apply Cluster Centroids to find the representative points of the majority class and generate synthetic minority samples.
SMOTE + Tomek Links + Random Undersampling: In this approach, we first remove Tomek Links to eliminate noisy and ambiguous samples from the dataset. Then, we apply SMOTE to oversample the minority class. Finally, we use Random Undersampling to reduce the size of the majority class.
SMOTE + Cluster Centroids: In this approach, we first use SMOTE to oversample the minority class. Then, we apply Cluster Centroids to find the representative points of the majority class and generate synthetic minority samples.
The advantage of hybrid approaches is that they can address the shortcomings of both undersampling and oversampling techniques, and improve the performance of machine learning models. However, hybrid approaches can be more computationally expensive and require more hyperparameter tuning than individual techniques. It's important to experiment with different hybrid approaches to find the one that works best for a given dataset and problem.
Popular Libraries for Handling Imbalanced Data in Python
Python has several popular libraries that can be used for handling imbalanced data in machine learning. Some of these libraries are:
imbalanced-learn: This library provides various techniques for resampling, under-sampling, over-sampling and combination of these methods to handle class imbalance. It can be easily integrated with other libraries like scikit-learn.
scikit-learn: Scikit-learn is a widely used machine learning library that offers several algorithms for classification, regression, clustering, and dimensionality reduction. It also provides a few methods for handling imbalanced data such as Random Under-Sampling, Random Over-Sampling, and SMOTE.
Keras: Keras is a popular deep learning library that provides a high-level neural networks API. It also offers several techniques for handling imbalanced data like class_weight, sample_weight, and data augmentation.
Code examples for implementing different techniques can be found in the official documentation of these libraries, online tutorials and GitHub repositories.
Evaluation Metrics for Imbalanced Data
In order to determine the effectiveness of the techniques used for handling imbalanced data, it is important to use appropriate evaluation metrics. Standard evaluation metrics such as accuracy, precision, and recall can be misleading when dealing with imbalanced datasets as they tend to focus on overall performance rather than the performance on minority class examples. Here are some evaluation metrics that can be used for imbalanced datasets:
Confusion Matrix: A confusion matrix is a table that summarizes the number of correct and incorrect predictions for each class in a classification problem. It can be used to calculate metrics such as precision, recall, and F1 score.
ROC Curve: The receiver operating characteristic (ROC) curve is a plot of the true positive rate against the false positive rate at various threshold settings. It is a useful tool for visualizing the performance of a binary classifier.
Precision-Recall Curve: The precision-recall curve is a plot of precision versus recall at different threshold settings. It is useful when the positive class is rare or when the cost of false negatives is higher than the cost of false positives.
Area Under the Curve (AUC): The area under the ROC curve (AUC) is a useful metric for summarizing the performance of a binary classifier. AUC represents the probability that a classifier will rank a randomly chosen positive instance higher than a randomly chosen negative instance.
F1 Score: The F1 score is the harmonic mean of precision and recall. It is a useful metric when both precision and recall are important, but it can be biased towards the majority class.
Choosing the appropriate evaluation metric depends on the specific problem and the goals of the project. It is important to select a metric that is appropriate for the imbalanced dataset and to interpret the results carefully.

Conclusion
In conclusion, balancing imbalanced data is a critical factor in creating effective machine learning models. In this blog post, we have discussed several strategies to handle imbalanced data, such as undersampling, oversampling, and hybrid approaches. We have also highlighted the importance of evaluation metrics and introduced some popular Python libraries to implement these techniques.
Using these techniques can significantly improve the model's performance and decision-making abilities, but it is important to be aware of the potential drawbacks, such as overfitting and increased computation time. By carefully selecting the appropriate approach based on the dataset, we can create more accurate and reliable machine learning models.
I welcome your feedback and suggestions for further improvements to my blog post. I hope that you found this post helpful and informative. Please follow my blog to stay updated on the latest developments in machine learning and data science. Your support and engagement mean a lot to me, and I look forward to continuing to provide valuable content.
Subscribe to my newsletter
Read articles from Saumya Gupta directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by