Simple KServe Inference Logger
 Shreehari Vaasistha L
Shreehari Vaasistha L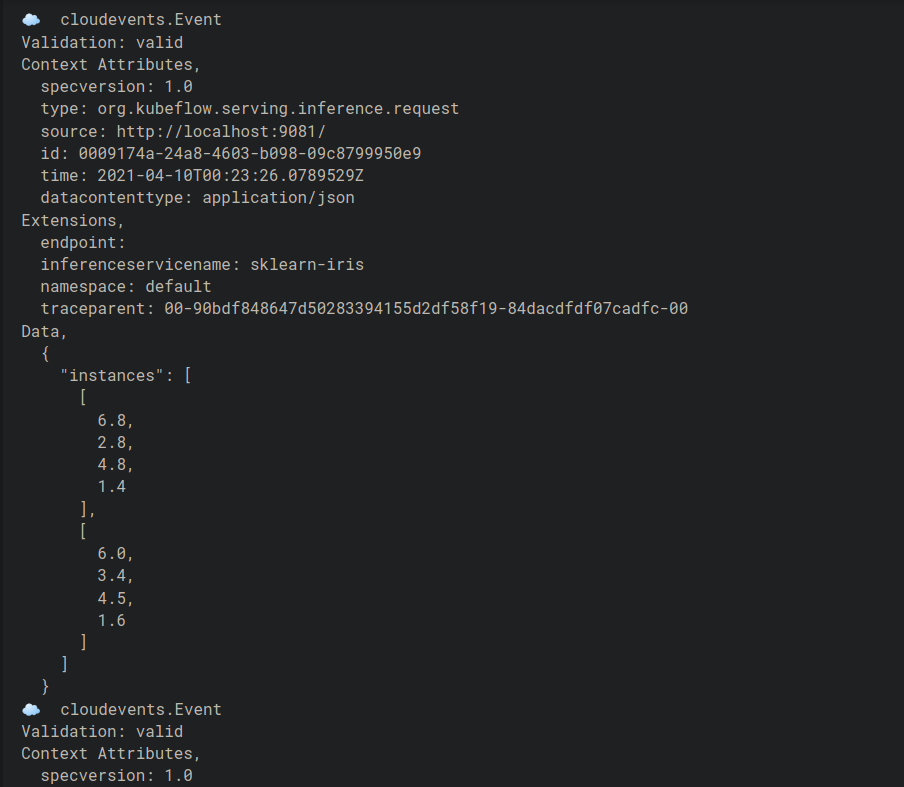
If you're serving machine learning models on KServe, you know how important it is to log the prediction input and output. Logging helps you debug issues, analyze performance, and troubleshoot errors. Fortunately, KServe makes it easy to create a simple service called message-dumper that receives the data in form of an HTTP POST request from KServe for each request and response (individually). KServe includes a unique identifier (UUID) to know for which request the prediction response was returned. In this blog post, we'll show you how to set up message-dumper and create an inference service with logger enabled.
How to Set Up Message Dumper
Follow these simple steps to set up message-dumper:
- Create a file named message-dumper.yaml and paste the following contents in it:
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: message-dumper
spec:
template:
spec:
containers:
- image: gcr.io/knative-releases/knative.dev/eventing-contrib/cmd/event_display
- Create the service now on Kubernetes:
kubectl create -f message-dumper.yaml
Create an Inference Service with Logger Enabled
Follow these simple steps to create an inference service with logger enabled:
- Create a YAML file called sklearn-basic-logger.yaml with the following contents:
apiVersion: serving.kserve.io/v1beta1
kind: InferenceService
metadata:
name: sklearn-iris
spec:
predictor:
logger:
mode: all
url: http://message-dumper.default/
sklearn:
storageUri: gs://kfserving-examples/models/sklearn/1.0/model
Note that the logger section is crucial to enable logging in to your inference service. Here is the code for reference:
logger:
mode: all
url: http://message-dumper.default/
You can add the URL of your external service which handles the data. Here, as an example, we are adding the URL of a Kubernetes service called message-dumper, which we created in the above.
- Create the service:
kubectl create -f sklearn-basic-logger.yaml
How to Test the Inference Service
Now that you have set up message-dumper and created an inference service with logger enabled, it's time to test the service. Here's how:
Make an HTTP request to the inference service.
Check the logs of the message-dumper pod. You should be able to see the request and response logs.
Conclusion
Logging is an essential part of running machine learning models on Production. With the help of message-dumper and inference service with logger enabled, you can easily log the prediction input and output without compromising on the latency. This helps you keep track of your models' performance and troubleshoot issues. I hope this blog post has helped set up logging for your KServe inference service.
Subscribe to my newsletter
Read articles from Shreehari Vaasistha L directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by