MLOps Explained: An Overview of the Paper
 Aditya Adarsh
Aditya AdarshHere is a summary of the paper:
The paper presents a comprehensive overview of MLOps, a set of engineering practices specific to machine learning projects that draw from the widely adopted DevOps principles in software engineering. MLOps is defined as "the intersection of people, process, and platform for gaining business value from machine learning". The paper describes the main principles, components, roles, and challenges of MLOps.
The main principles of MLOps are:
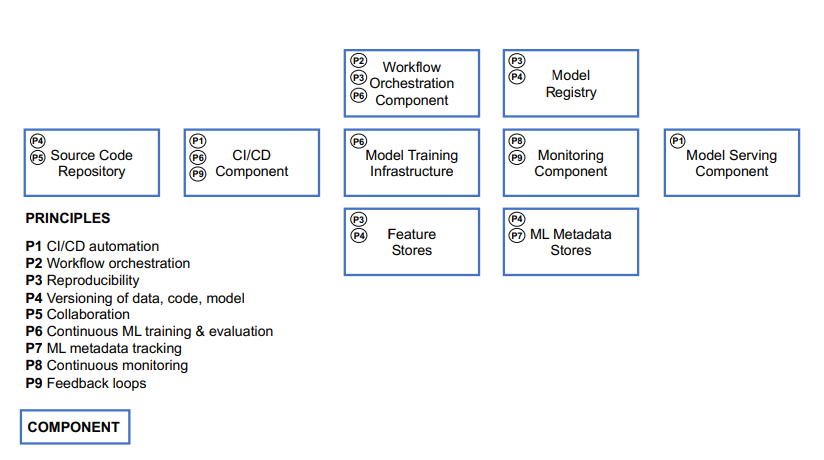
CI/CD automation: automate the integration, testing, and delivery of machine learning models and code.
Workflow orchestration: manage the dependencies and execution of complex machine learning workflows across different environments and stages.
Reproducibility: ensure the consistency and traceability of machine learning experiments, data, code, and models.
Collaboration: enable effective communication and coordination among different stakeholders involved in machine learning projects.
Continuous ML training and evaluation: train and evaluate machine learning models on new data and monitor their performance over time.
ML metadata tracking/logging: collect and store metadata about machine learning experiments, data, code, models, and deployments.
Continuous monitoring: measure and report the health, performance, and quality of machine learning models in production.
Feedback loop: collect feedback from users and business metrics and use it to improve machine learning models and workflows.
The technical components of MLOps are:
CI/CD: a set of tools and practices that automate the integration, testing, and delivery of machine learning models and code.
Source code repository: a system that stores and manages the version control of machine learning code and configuration files.
Workflow orchestration component: a system that orchestrates the execution of complex machine learning workflows across different environments and stages.
Feature store system: a system that manages the storage, processing, and serving of features for machine learning models.
Model registry system: a system that stores and manages the metadata, versions, and lineage of machine learning models.
Model serving system: a system that deploys and serves machine learning models for inference requests.
Model monitoring system: a system that monitors the health, performance, and quality of machine learning models in production.
Feedback collection system: a system that collects feedback from users and business metrics for machine learning models in production.
The roles involved in MLOps are:
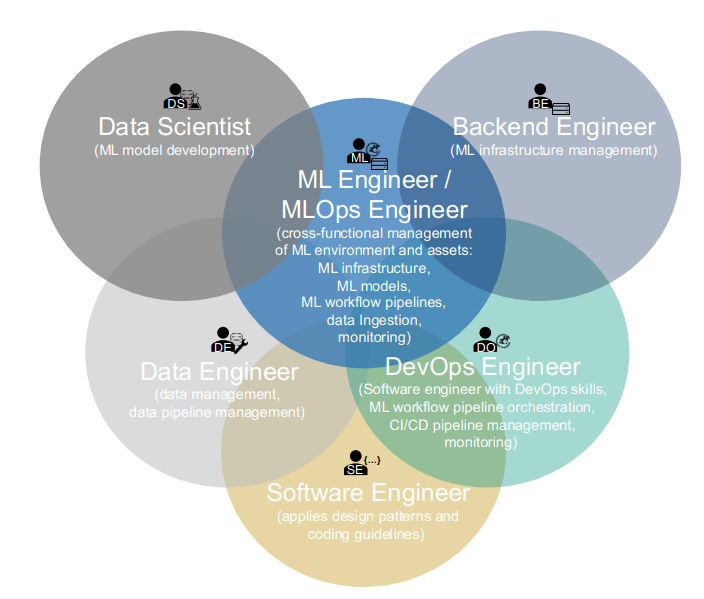
Business stakeholder: a person who defines the business objectives, requirements, and KPIs for machine learning projects.
Solution architect: a person who designs the overall architecture and solution for machine learning projects.
Data scientist: a person who develops machine learning models using data analysis, exploration, preprocessing, feature engineering, model training, evaluation, and interpretation techniques.
Data engineer: a person who handles the data acquisition, preparation, processing, storage, and serving for machine learning projects.
Software engineer: a person who develops the software components and applications that integrate with machine learning models and workflows.
DevOps engineer: a person who sets up and maintains the infrastructure, platforms, tools, and pipelines for machine learning projects.
ML/MLOps engineer: a person who specializes in applying MLOps principles and practices to machine learning projects.
The challenges of MLOps are:
Complexity: machine learning projects involve complex workflows with many dependencies, stages, environments, tools, frameworks, languages, data sources, formats, etc.
Diversity: machine learning projects require diverse skills, expertise, roles, responsibilities, communication styles, etc.
Dynamism: machine learning projects are subject to frequent changes in data, code, models, requirements, etc.
The paper proposes a reference architecture for MLOps based on a literature review and a survey of existing tools and frameworks. The architecture consists of four layers:
Data layer: where data is acquired, prepared, processed, stored, and served for machine learning projects.
Development layer: where code is written, tested, integrated, and delivered for machine learning projects.
Deployment layer: where models are registered, packaged, deployed, and served for inference requests.
Monitoring layer: where models are monitored for health, performance, and quality in production, and feedback is collected from users and business metrics.
The paper also shows a detailed map of the MLOps lifecycle with all the components, roles, and activities involved in each stage. It concludes by highlighting the benefits of MLOps, such as faster time to market, higher model quality, lower operational costs, better collaboration, and improved governance.
Finally, the paper discusses some open challenges and future directions for MLOps research and practice, such as standardization, interoperability, scalability, security, privacy, ethics, and education.
MLOps Lifecycle
Data layer: This is where data is acquired, prepared, processed, stored, and served for machine learning projects.
Data acquisition: This involves collecting data from various sources such as databases, APIs, web scraping, and sensors. The role of the data engineer is primarily involved in this activity.
Data preparation: This involves cleaning, transforming, validating, and labeling data for machine learning projects. The roles of the data engineer and data scientist are mainly involved in this activity.
Data processing: This involves applying feature engineering, feature extraction, feature selection, and feature scaling techniques to data for machine learning projects. The role of the data scientist is mainly involved in this activity.
Data storage: This involves storing data in various formats and structures such as relational databases, NoSQL databases, data lakes, data warehouses, etc. The role of the data engineer is mainly involved in this activity.
Data serving: This involves providing data to machine learning models for training and inference purposes. The role of the data engineer is mainly involved in this activity.
Development layer: This is where code is written, tested, integrated, and delivered for machine learning projects.
Code writing: This involves writing code for machine learning models and workflows using various tools, frameworks, languages, and libraries. The roles of the data scientist and software engineer are mainly involved in this activity.
Code testing: This involves testing code for machine learning models and workflows using various methods such as unit testing, integration testing, regression testing, etc. The roles of the data scientist and software engineer are mainly involved in this activity.
Code integration: This involves integrating code for machine learning models and workflows with other code components and systems using various tools and practices such as version control systems, code review systems, pull requests, etc. The roles of the data scientist, software engineer, and DevOps engineer are mainly involved in this activity.
Code delivery: This involves delivering code for machine learning models and workflows to different environments and stages using various tools and practices such as CI/CD pipelines, containers, cloud platforms, etc. The roles of the data scientist, software engineer, and DevOps engineer are mainly involved in this activity.
Deployment layer: This is where models are registered, packaged, deployed, and served for inference requests.
Model registration: This involves registering machine learning models with their metadata, versions, and lineage using a model registry system. The role of the ML/MLOps engineer is mainly involved in this activity.
Model packaging: This involves packaging machine learning models with their dependencies, configuration files, and artifacts using various tools and formats such as Docker images, MLflow models, ONNX models, etc. The role of the ML/MLOps engineer is mainly involved in this activity.
Model deployment: This involves deploying machine learning models to different environments and platforms using various tools and methods such as Kubernetes clusters, serverless functions, edge devices, etc. The role of the ML/MLOps engineer is mainly involved in this activity.
Model serving: This involves serving machine learning models for inference requests using a model serving system that handles load balancing, scaling, routing, logging, etc. The role of the ML/MLOps engineer is mainly involved in this activity.
Monitoring layer: where models are monitored for health, performance, and quality in production and feedback is collected from users and business metrics.
Model health monitoring: the activity of monitoring the availability, reliability, and resilience of machine learning models in production using various metrics, such as uptime, latency, throughput, error rate, etc. The role of ML/MLOps engineer is mainly involved in this activity.
Model performance monitoring: the activity of monitoring the accuracy, precision, recall, and other metrics of machine learning models in production using various methods, such as A/B testing, canary testing, shadow testing, etc. The role of data scientist is mainly involved in this activity.
Model quality monitoring: the activity of monitoring the fairness, robustness, explainability, and other aspects of machine learning models in production using various techniques, such as fairness indicators, adversarial examples, feature importance, etc. The role of data scientist is mainly involved in this activity.
Feedback collection: the activity of collecting feedback from users and business metrics for machine learning models in production using various sources, such as surveys, ratings, reviews, conversions, revenue, etc. The role of business stakeholder is mainly involved in this activity.
I hope this completes the explanation of the paper summary. 😊
If you want to read the full paper, you can find it here: https://arxiv.org/ftp/arxiv/papers/2205/2205.02302.pdf
Subscribe to my newsletter
Read articles from Aditya Adarsh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Aditya Adarsh
Aditya Adarsh
Data Scientist