Word Embeddings
 Amit Vikram Raj
Amit Vikram Raj
What is Word Embedding?
-
In NLP, a word embedding is a representation of a word. The embedding is used in text analysis. Typically, the representation is a real-valued vector that encodes the meaning of the word in such a way that words that are closer in the vector space are expected to be similar in meaning.
Word embeddings can be obtained using language modeling and feature learning techniques, where words or phrases from the vocabulary are mapped to vectors of real numbers.
Word embeddings is a technique used to convert words into features where the loss of context b/w diff. words are minimal.
Word Embedding Algorithms - machinelearningmastery.com
Word embedding methods learn a real-valued vector representation for a predefined fixed-sized vocabulary from a corpus of text.
The learning process is either joined with the neural network model on some task, such as document classification or is an unsupervised process using document statistics.
3 techniques that can be used to learn a word embedding from text data:
- Embedding Layers
- Word2Vec
- GloVe
What is Medical Word Embedding & Why do we need custom word emebeddings?
General word embeddings might not perform well enough on all the domains. We need to build domain-specific embeddings to get better outcomes.
Eg: Pre-Trained Embeddings for Biomedical Words and Sentences
We need domain-specific word embeddings because a general word emebedding trained on general text data might not capture the context of words w.r.to our domain specific corpous of text.

Word2Vec
Word2Vec - Wikipedia
- Word2vec is a technique for NLP. The word2vec algorithm uses a neural network model to learn word associations from a large corpus of text. Once trained, such a model can detect synonymous words or suggest additional words for a partial sentence. As the name implies, word2vec represents each distinct word as a vector. The vectors are chosen carefully such that they capture the semantic and syntactic qualities of words; as such, a simple mathematical function (cosine similarity) can indicate the level of semantic similarity between the words represented by those vectors.
NLP: thinkinfi.com
There are two main NLP techniques:
- Syntax Analysis
- Semantic Analysis
Syntax Analysis: It is also known as syntactic analysis. Syntax is the arrangement or positioning of words to make sentences grammatically correct or sensible. There are many different techniques to do Syntax Analysis such as:
- Tokenization, POS tagging (Parts of speech tagging), Dependency Parsing, Stemming & Lemmatization, Stop word removal, TF-IDF, N-Grams
Semantic Analysis: Semantic Analysis is used to identify the meaning of the text. Semantic Analysis uses various NLP algorithms and techniques to understand meaning and structure of a sentence (or meaning of a word based on context).
For example meaning of “apple” is completely different in below two sentences:
- iPhone is a product of Apple
I eat apple every day.
You can understand topic of a text by doing Semantic Analysis of NLP.
For example an article containing words mobile, battery, touch screen, charging etc. can be labelled as “Mobile Phone”. Like above there are so many techniques and tasks involve in Semantic Analysis like:
- Named Entity Recognition (NER), Keyword Extraction, Topic Modelling, Word Relationship Extraction, Word Embedding, Text Similarity Matching, Word sense disambiguation
Word2Vec: thinkinfi.com
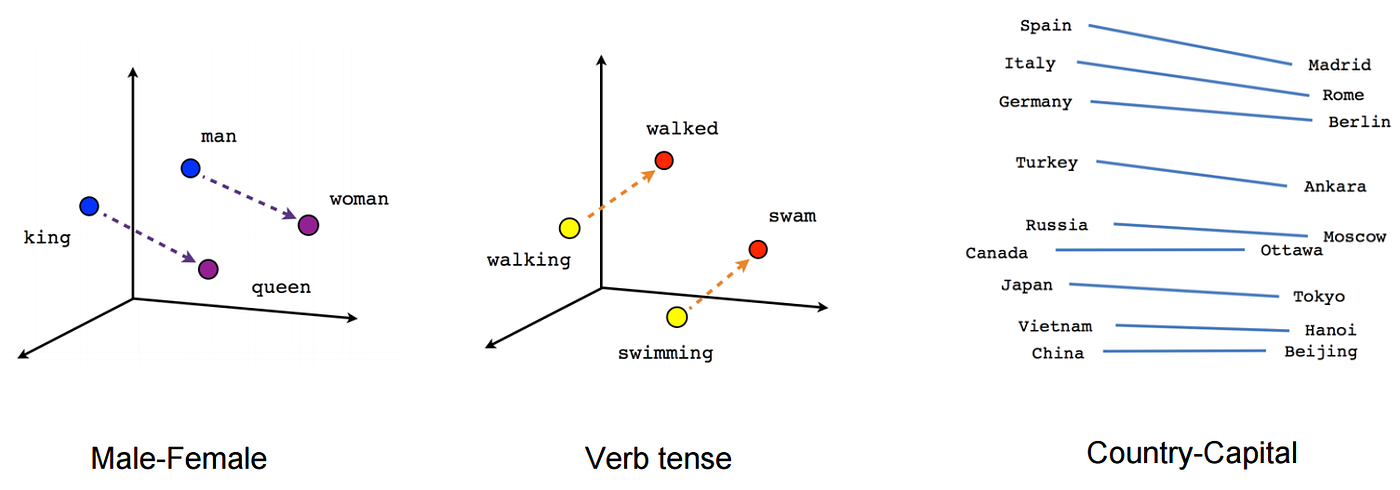
The main objective of Word2Vec is to generate vector representations of words that carry semantic meanings for further NLP tasks. Each word vector can have several hundred dimensions and each unique word in the corpus is assigned a vector in the space. For example, the word “man” can be represented as a vector of 4 dimensions
[-1, 0.01, 0.03, 0.09]and “woman” can have a vector of[1, 0.02, 0.02, 0.01].To implement Word2Vec, there are two flavors which are —
Continuous Bag-Of-Words(CBOW): The CBOW model learns the embedding by predicting the current word based on its context words(surrounding words).
Continuous Skip-gram(SG): The continuous skip-gram model learns by predicting the context/surrounding words given a current word. The opposite of CBOW.
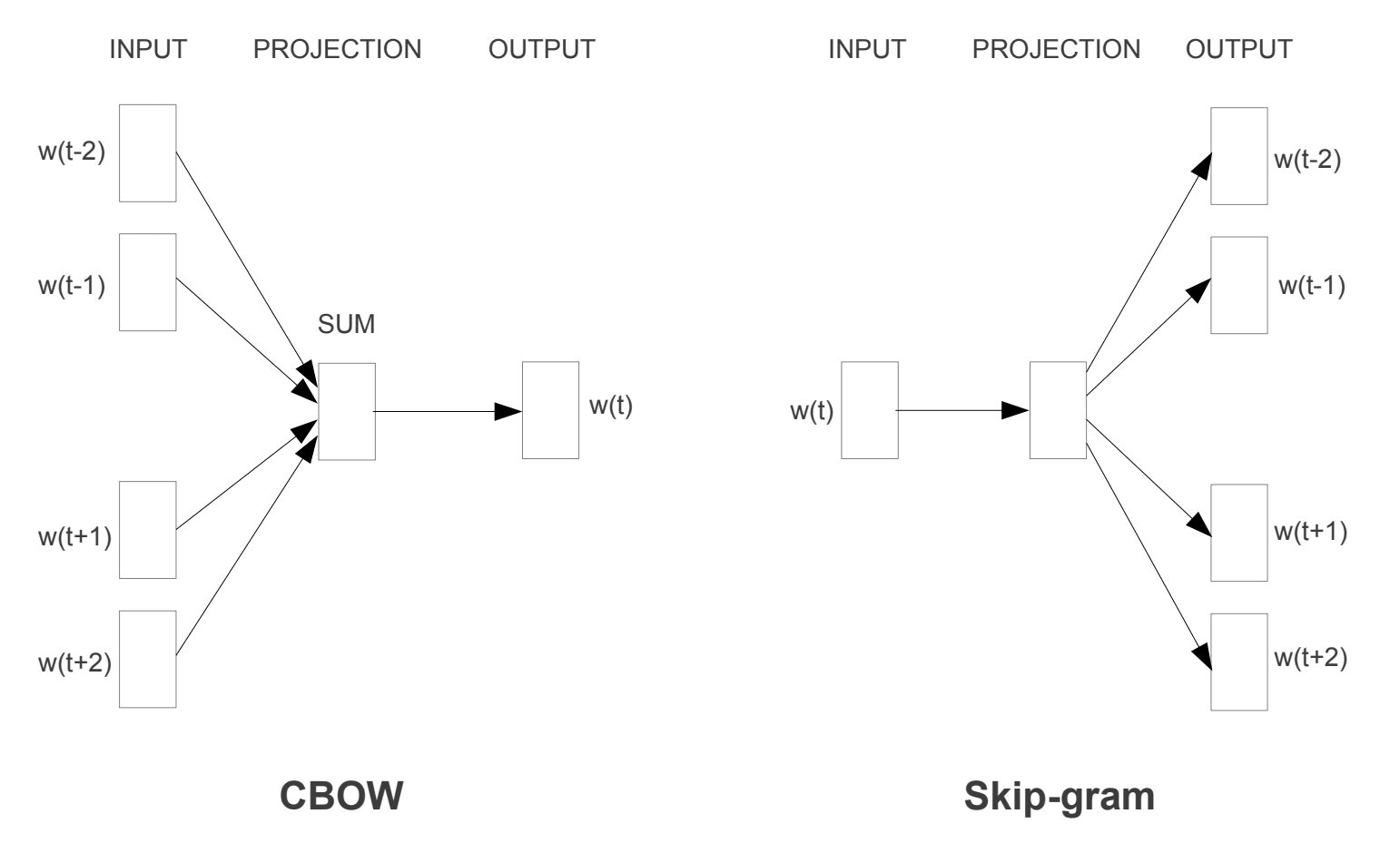
Continuous Bag of Words (CBOW):
It attempts to guess the output (target word) from its neighboring words (context words). You can think of it like fill in the blank task, where you need to guess word in place of blank by observing nearby words.

Continuous Skip-gram (SG):
It guesses the context words from a target word. This is completely opposite task than CBOW. Where you have to guess which set of words can be nearby of a given word with a fixed window size. For below example skip gram model predicts word surrounding word with window size 4 for given word “jump”


 |
Links
Continuous Bag of Words (CBOW) – Single Word Model – How It Works
Continuous Bag of Words (CBOW) – Multi Word Model – How It Works
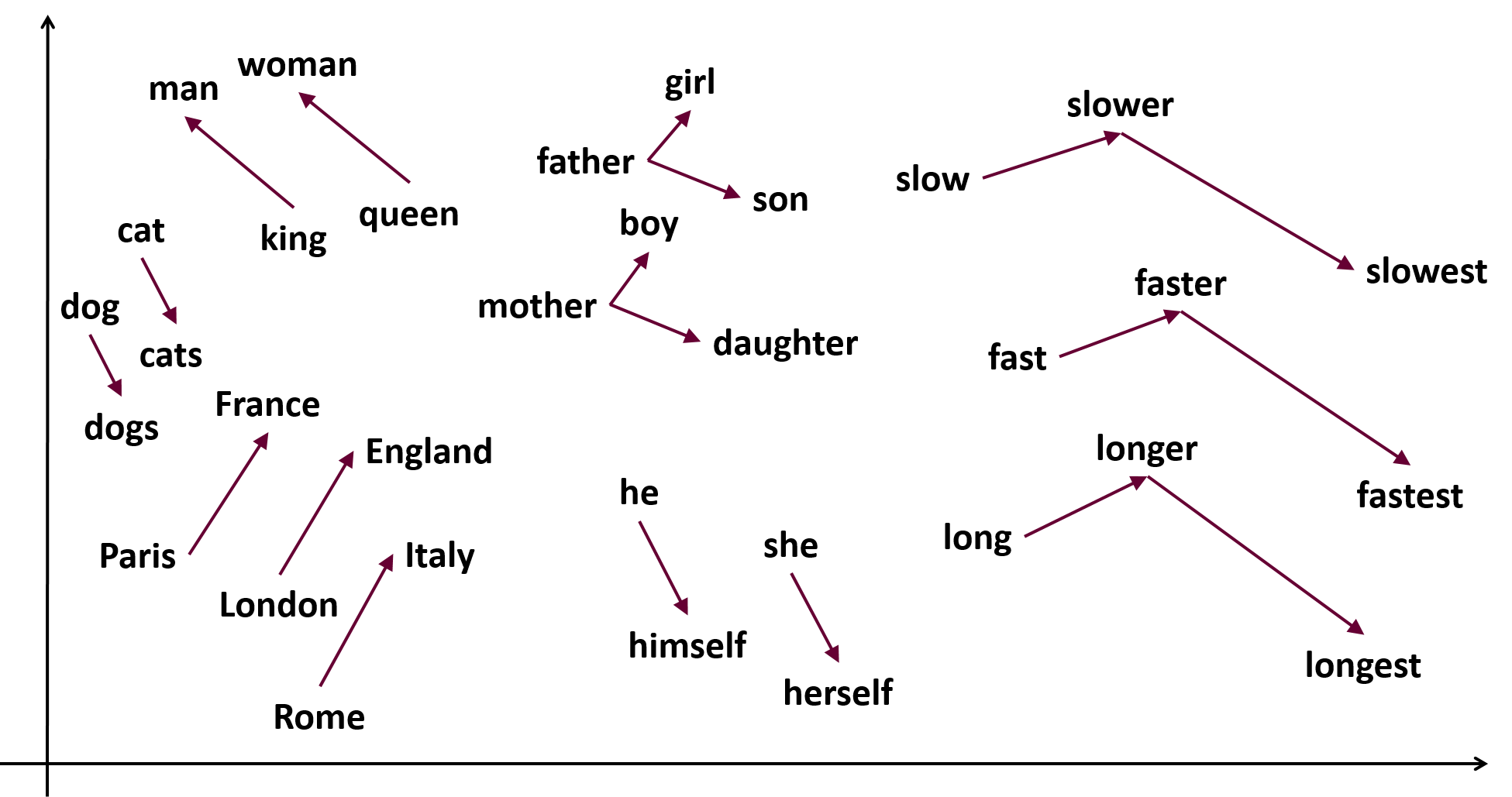
Idea Behind Word2Vec
- The basic idea is that similar meaning words in a given corpous of text appear next to each other.
Fast-text Model
FastText is a modified version of word2vec (i.e.. Skip-Gram and CBOW). The only difference between fastText vs word2vec is it’s pooling strategies (what are the input, output, and dictionary of the model).
FastText differs in the sense that word vectors a.k.a word2vec treats every single word as the smallest unit whose vector representation is to be found but FastText assumes a word to be formed by a n-grams of character, for example, sunny is composed of
[sun, sunn,sunny],[sunny,unny,nny]etc, wherencould range from 1 to the length of the word.Advantages:
It is helpful to find the vector representation for rare words. Since rare words could still be broken into character n-grams, they could share these n-grams with the common words. For example, for a model trained on a news dataset, the medical terms, eg: diseases, can be the rare words.
It can give the vector representations for the words not present in the dictionary (OOV words) since these can also be broken down into character n-grams. word2vec and glove both fail to provide any vector representations for words not in the dictionary/training data.
- For example, for a word like
stupedofantabulouslyfantastic, which might never have been in any corpus, gensim might return any two of the following solutions – (a) a zero vector or (b) a random vector with low magnitude. But FastText can produce vectors better than random by breaking the above word in chunks and using the vectors for those chunks to create a final vector for the word. In this particular case, the final vector might be closer to the vectors of fantastic and fantabulous.
- For example, for a word like
- Character n-grams embeddings tend to perform superior to word2vec and glove on smaller datasets.


Subscribe to my newsletter
Read articles from Amit Vikram Raj directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Amit Vikram Raj
Amit Vikram Raj
I'm into NLP & ML Engineering. Connect me over LinkedIn! Peace.