Assessing model's performance-Classification Algorithms
 Rhythm Rawat
Rhythm RawatClassification models are a type of machine learning algorithm that is used to predict a categorical outcome variable based on one or more predictor variables. These models are commonly used in a variety of applications such as fraud detection, spam filtering, image recognition, and many others. However, to assess the performance of classification models, several performance metrics are used. In this blog, we'll cover some of the most commonly used performance metrics for classification models.
Accuracy
Accuracy is a classification metric that measures the proportion of correctly classified instances. It is calculated as follows:

where TP is the number of true positives, TN is the number of true negatives, FP is the number of false positives, and FN is the number of false negatives.
Accuracy is a simple and easy-to-understand metric that works well when the classes are balanced. However, when the classes are imbalanced, accuracy may not be a suitable metric, as it can be misleading.
Precision
Precision is a classification metric that measures the proportion of correctly classified positive instances. It is calculated as follows:
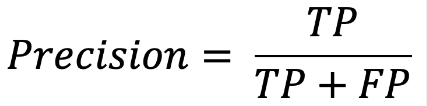
where TP is the number of true positives and FP is the number of false positives.
Precision is a useful metric when the cost of false positives is high, as it measures the model's ability to correctly identify positive instances.
Recall (Sensitivity)
Recall (also known as sensitivity) is a classification metric that measures the proportion of true positive instances that are correctly classified. It is calculated as follows:

where TP is the number of true positives and FN is the number of false negatives.
Recall is a useful metric when the cost of false negatives is high, as it measures the model's ability to correctly identify all positive instances.
Specificity
Specificity is a classification metric that measures the proportion of true negative instances that are correctly classified. It is calculated as follows:

where TN is the number of true negatives and FP is the number of false positives.
Specificity is a useful metric when the cost of false positives is high, as it measures the model's ability to correctly identify all negative instances.
F1-score
F1-score is a classification metric that is a harmonic mean of precision and recall. It is calculated as follows:
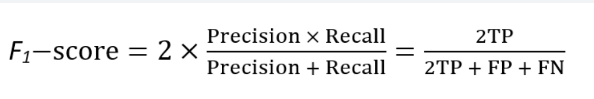
F1-score is a useful metric when the classes are imbalanced, as it balances the trade-off between precision and recall.
Confusion matrix
A confusion matrix is a table that summarizes the performance of a classification model by comparing the predicted and actual classes for a set of test data. It is a useful tool for evaluating the performance of a binary classifier, where the predicted class can be either positive or negative, and the actual class is either true or false.
A confusion matrix is usually represented in a 2x2 table, as shown below:

The four cells of the confusion matrix represent the following:
True Positive (TP): The number of instances where the model predicted positive and the actual class is positive.
False Positive (FP): The number of instances where the model predicted positive but the actual class is negative.
False Negative (FN): The number of instances where the model predicted negative but the actual class is positive.
True Negative (TN): The number of instances where the model predicted negative and the actual class is negative.
Using the confusion matrix, we can calculate several metrics to evaluate the performance of a classification model, such as accuracy, precision, recall, and specificity, as mentioned in the previous section.
Conclusion
In conclusion, performance metrics are an essential component in evaluating the effectiveness of machine learning models. They provide a quantitative measure of how well a model is performing and can guide us in making improvements to the model. For regression models, metrics such as mean absolute error, mean squared error, and R-squared are commonly used. On the other hand, for classification models, metrics such as accuracy, precision, recall, specificity, and the confusion matrix are used. Hope you got value out of this article. Subscribe to the newletter to get more such blogs on your feed
Thanks :)
Subscribe to my newsletter
Read articles from Rhythm Rawat directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Rhythm Rawat
Rhythm Rawat
Machine learning enthusiast with a strong emphasis on computer vision and deep learning. Skilled in using well-known machine learning frameworks like TensorFlow , scikit-learn and PyTorch for effective model development. Familiarity with transfer learning and fine-tuning pre-trained models to achieve better results with limited data. Proficient in Python, Machine Learning, SQL, and Flask.