Web Semantic Trends
 Bhargavi Sheth
Bhargavi ShethTable of contents

Abstract:
Nowadays there is an exponential rise in the amount of Information on the World Wide Web and there is a need for a much more efficient algorithm for Web Search. The traditional algorithms based on keyword matching as well as the standard statistical techniques are insufficient as the Web Pages they recommend are not highly relevant to the query. From the very early days of the World Wide Web, researchers identified a need to be able to understand the semantics of the information on the Web to enable intelligent systems to do a better job of processing the booming Web of documents. With the growth of the Semantic Web, lots of algorithms that semantically compute the most relevant Web Pages have been developed and the work is going on. In this paper, we will study and review the recent trends in the semantic web domain. The Semantic Web offers an exciting promise of a world in which computers and humans can cooperate effectively with a common understanding of the meaning of data. However, in the decade since the term has come into widespread usage, Semantic Web applications have been slow to emerge from research laboratories.
KEYWORDS: RDF, OWL, SPARQL, Data of Web, Web Semantic.
- INTRODUCTION:
The Semantic Web is an extension of the World Wide Web through standards set by the World Wide Web Consortium (W3C). The term was coined by Tim Berners-Lee for a web of data that can be processed by machines—that is, one in which much of the meaning is machine-readable. To enable the encoding of semantics with the data, technologies such as Resource Description Framework (RDF) and Web Ontology Language (OWL) are used. These technologies are used to formally represent metadata. For example, ontology can describe concepts, relationships between entities, and categories of things. These embedded semantics offer significant advantages such as reasoning over data and operating with heterogeneous data sources. According to the W3C, "The Semantic Web provides a common framework that allows data to be shared and reused across application, enterprise, and community boundaries.
- Semantic web layered architecture :
The term "Semantic Web" is often used more specifically to refer to the formats and technologies that enable it. The collection, structuring and recovery of linked data are enabled by technologies that provide a formal description of concepts, terms, and relationships within a given knowledge domain. These technologies are specified as W3C standards and include:
• ResourceDescriptionFramework (R DF), a general method for describing information
• RDF Schema (RDFS)
• Simple Knowledge Organization System (SKOS)
• SPARQL, an RDF query language
• Notation3 (N3), designed with human readability in mind
• N-Triples, a format for storing and transmitting data
• Turtle (Terse RDF Triple Language)
• Web Ontology Language (OWL), a family of knowledge representation languages
• Rule Interchange Format (RIF), a framework of web rule language dialects supporting rule interchange on the Web.
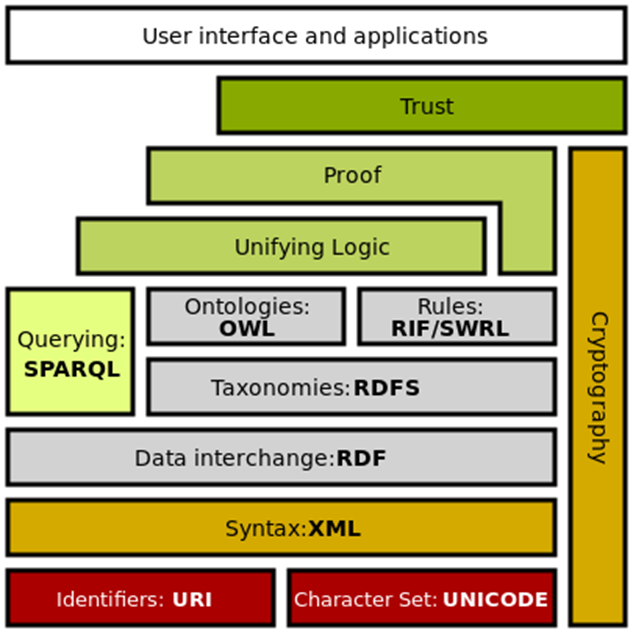
The Semantic Web Stack illustrates the architecture of the Semantic Web. The functions and relationships of the components can be summarized as follows
• XML provides an elemental syntax for content structure within documents, yet associates no semantics with the meaning of the content contained within. XML is not at present a necessary component of Semantic Web technologies in most cases, as alternative syntaxes exist, such as Turtle. Turtle is a de facto standard, but has not been through a formal standardization process.
• XML Schema is a language for providing and restricting the structure and content of elements contained within XML documents.
• RDF is a simple language for expressing data models, which refer to objects ("web resources") and their relationships. An RDF-based model can be represented in a variety of syntaxes, e.g., RDF/XML, N3, Turtle, and RDFa. RDF is a fundamental standard of the Semantic Web.
• RDF Schema extends RDF and is a vocabulary for describing properties and classes of RDF-based resources, with semantics for generalized hierarchies of such properties and classes.
• OWL adds more vocabulary for describing properties and classes: among others, relations between classes (e.g. disjointness), cardinality (e.g. "exactly one"), equality, richer typing of properties, characteristics of properties (e.g. symmetry), and enumerated classes.
• SPARQL is a protocol and query language for semantic web data sources. SPARQL allows users to write queries against what can loosely be called "key-value" data or, more specifically, data that follow the RDF specification of the W3C. Thus, the entire database is a set of "subject-predicate-object" triples. This is analogous to some NoSQL databases' usage of the term "document-key-value", such as MongoDB.
• RIF is the W3C Rule Interchange Format. It's an XML language for expressing Web rules that computers can execute. RIF provides multiple versions, called dialects. It includes a RIF Basic Logic Dialect (RIF-BLD) and RIF Production Rules Dialect (RIF PRD).
2.1 Query forms:
in the case of queries that read data from the database, the SPARQL language specifies four different query variations for different purposes.
SELECT query Used to extract raw values from a SPARQL endpoint, the results are returned in a table format.
CONSTRUCT query Used to extract information from the SPARQL endpoint and transform the results into valid RDF.
ASK query Used to provide a simple True/False result for a query on a SPARQL endpoint.
DESCRIBE query Used to extract an RDF graph from the SPARQL endpoint, the content of which is left to the endpoint to decide, based on what the maintainer deems as useful information.
Each of these query forms takes a WHERE block to restrict the query, although, in the case of the DESCRIBE query, the WHERE is optional. SPARQL specifies a language for updating the database with several new query forms.
2.2 N triples :
N-Triples is a format for storing and transmitting data. It is a line-based, plain text serialization format for RDF (Resource Description Framework) graphs and a subset of the Turtle (Terse RDF Triple Language) format. N-Triples should not be confused with Notation 3 which is a superset of Turtle.
2.3 Web ontology :
The Web Ontology Language (OWL) is a family of knowledge representation languages for authoring ontologies. Ontologies are a formal way to describe taxonomies and classification networks, essentially defining the structure of knowledge for various domains: the nouns representing classes of objects and the verbs representing relations between the objects. “The Adventures of Tom Sawyer” was written by Mark Twain. could be expressed in RDF by a statement such as:
<rdf: Description
rdf: about=www.famouswriters.org/twain/m ark>
<s:hasName>Mark Twain</s:hasName>
<s:has written rdf:resource= www.books.org/ISBN0001047\>
</rdf: Description>
This could be expressed in RDFS as:
<rdf:Property rdf:ID=“HasWritten”
<rdfs:domain rdf:resource=“#author”>
<rdfs:range rdf:resource=“#book”>
<\rdf:Property>
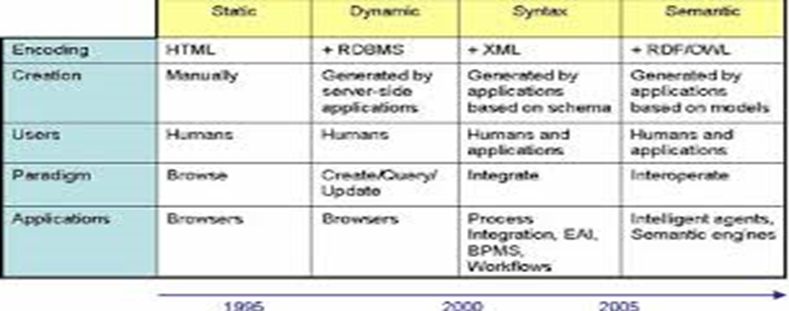
Evolution of the Technology adapted from
2.4 Today Vs Future :
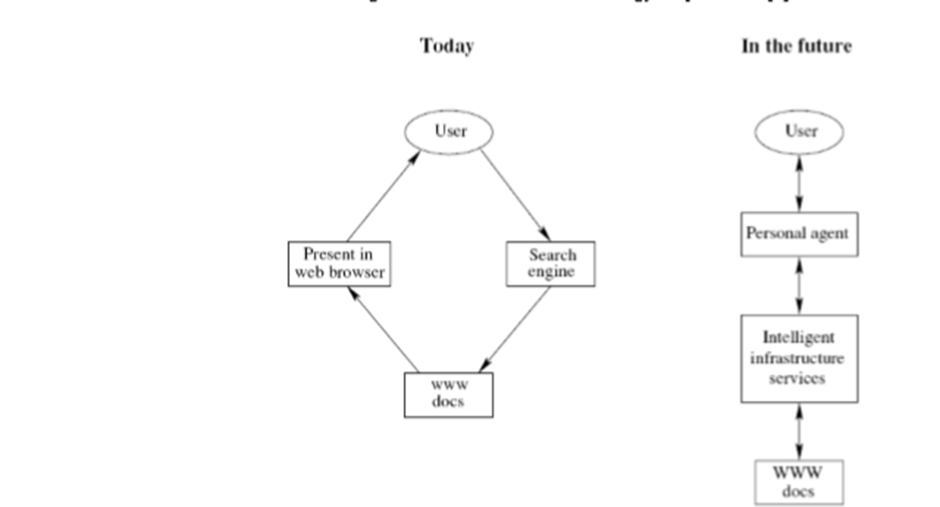
Tim Berners-Lee coined the concept of a “Semantic Web”, where the web can be considered more a global database that computer systems could understand rather than a series of separate web pages. In turn, this could effectively allow deeper integrations between different computer systems and allow for greater decentralization of data. The data here is not just from large corporations—it can be your data or my data, data that we control and manage ourselves through our websites
Application:
Semantic Web in Artificial Intelligence:
Takahira Yamaguchi‘s Group (doing Research on Semantic Web, combining the web with AI). In the semantic web, Software can be made to understand the meaning of web pages by adding headings called metadata ‘to web pages. Here, the research has been pursued not in the Internet field, but independently of the Internet, in the field of artificial intelligence. They are developing a system where the answer can be calculated using data and Ontologies to give replies automatically. In addition, they combined the semantic web and robots. At present the internet is used mainly for searching, but as the next stage of processing, there‘s a lot of routine work; for example; when certified accountants do a variety of accounting processes. So, there has been a major trend in this direction.
Semantic Web and Social Network:
We apply Semantic Web technology to the aggregation of the electronic data sets that we collect about the social networks of researchers working on the realization of the Semantic Web. We analyze these data using the methods of network analysis and make contributions to the field of scientific metrics by measuring the impact of social networks on the success (or failure) of researchers. The Semantic Web would function with highly formal ontologies with minimal ambiguity and thus a minimal need for human interpretation, we now encounter the limitations of increasing the formality of knowledge in the global, dynamic environment of the Web.
Real-life applications:
pen Graph, created by Facebook, is a popular format for holding specific types of structured data. Facebook uses this to generate link previews from page metadata. Website developers want additional control over what is displayed based on how it is described in the metadata. Since its creation, other social media sites have also adopted Open Graph for generating link previews. Microdata, RDFa, and JSON-LD, however, are a bit different as, by themselves, they only represent different formats of storing data on a web page. Computers can parse these standardized structures. However, unless it knows the type of data being represented, it will not understand the data. What is missing here is a shared vocabulary so that two different computer systems can understand each other.
Trends:
i. Answer Engines: The Knowledge Graph (or any entity graph) is based on internal, verified and validated structured data that facilitate the existence of answer engines.
ii. Machine Readable: The Semantic Web, in the form of structured markup embedded in HTML pages, provides machine-readable information to search engine crawlers on specific topics/subjects.
iii. Enhanced SERP Displays & Lift: Search Engines exploit semantic technology to create a better user experience. Google‘s rich snippets, Bing Tiles and Yahoo SearchMonkey results are all ―enhanced displays‖ that make SERPs more visually engaging to the audience — which, among other things, leads to a higher clickthrough rate (CTR). The carousel and knowledge graph results are also examples of enhanced displays that create a better user experience. [12]
iv. Validation Of Web Pages: By extracting pertinent structured data, search engines can verify that your pages are, in fact, about the topic you are describing on those pages. This verification adds trust to your web pages.
v. Social Network Adoption: Search engines like Google can leverage semantic search to drive the adoption of their Google Plus social network for businesses.
vi. Google+ Authorship Rich Snippet: Google+ social network adoption is further driven for personal use by individuals due to the authorship-rich snippet.
vii. Internal Structured Data: Internal structured data (verified and validated via trusted sources) can be leveraged for many things, such as prediction or recommendation. Google is a master at using this kind of Big- Data. But remember, the law of all data when utilizing it for results: GIGO (Garbage In, Garbage Out).
viii. The Future Of Search: Internal axiomatic facts, along with context or knowledge base partitions can allow computers (and search engines) to derive new information and can be leveraged along with viable reasoning mechanisms to create the all-intelligent Star Trek computer of the future. At a minimum, search engines like Google are already deriving basic associations by traversing a Semantic network or Knowledge Graph.
ix. Schema.org Ontology: When search engines leverage something like a Schema.org ontology (or any vocabulary or representation of concepts within a computer), those concepts are essentially language-independent.
x. Understanding User Intent: Search engines use Semantic Sear
Scope of Web Semantic :
the web is slowly gaining power and collaborating with other areas of research like bioinformatics, eCommerce, e-Government and social web. Its most significant use is seen in the field of Bioinformatics A fast-developing trend in biomedical network analysis is about combining multiple biomedical-associated data, which can be highly heterogeneous into coherent bio-molecular interaction networks to enable integrated network analysis. Applications like genomic ontologies, semantic web services, automated catalog alignment, ontology matching, blogs and social networks are constantly increasing, driven by companies like Google, Amazon, YouTube, Face book and LinkedIn. The need for combining information in a meaningful way creates the potential and demand for research on the Semantic Web.
Conclusion :
The rate at which data gets generated is increasing day by day with semantics in it. Apart from the increasing amount of semantically annotated information on the Web, a lot more structured data is becoming available. This includes information from scientists and governments publishing data on the Web and the ever-increasing amount of information available about each of us, individually and as societies—in the form of our social interactions, location and health data, activities, and interests. Working with this data, and understanding its diverse and often contradicting nature, to provide really meaningful services and to improve the quality of our lives, is something that researchers in both industry and academia are beginning to tackle. Statistical and machine-learning methods become more powerful and computational resources continue to improve. So some of the semantic knowledge that researchers had to construct manually they can now learn automatically, tremendously increasing the scale of the use of semantics in understanding and processing Web data. Similarly, our very understanding of the nature of the semantics that intelligent systems produce and leverage is changing, and with it, our vision for the future of the Semantic Web.
Subscribe to my newsletter
Read articles from Bhargavi Sheth directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Bhargavi Sheth
Bhargavi Sheth
I am curious Learner. On the way to become Er. Bhargavi Sheth, Want to share My knowledge and skills to industry & society.Ever ready to learn new skills to upgrade myself and society. Aspiring Web Development skills to solve the problem of industries & Society. " HAVE THE COURAGE TO FOLLOW MY HEART , DREAMS & INTUITIONS" !!