Orchestration? Maybe! (Project Beat~lytica Part 3)
 Warui Wanjiru
Warui Wanjiru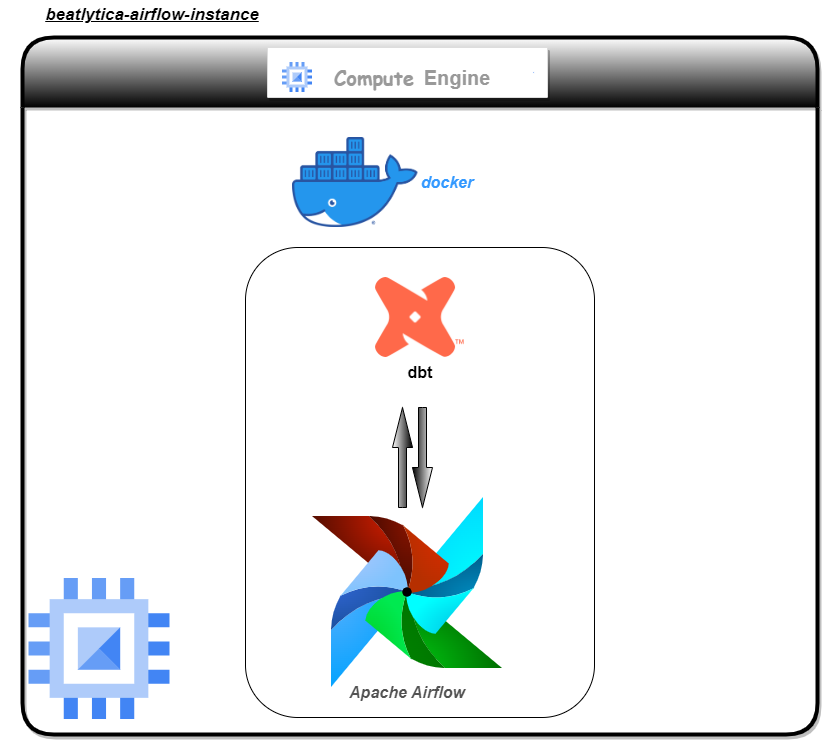
Welcome to the third instalment of the Beatlytica series.
I'm sorry to have kept you waiting for the juice this week. It's been a little hectic, but we're moving. In the last instalment, we discussed the implementation of the consumer of messages from Kafka topics, which was a Spark cluster with a single master node. You can find out more about that here.
In today's blog, I am going to focus on the pipeline orchestration from the GCS bucket where the Spark cluster is storing the data, to how it is transformed and restored while waiting for visualization. What tools am I going to use, you may ask? The answer to that is in the following paragraphs. I hope you enjoy it.
To begin with, the Spark cluster was loading raw data into a Google Cloud Storage bucket, or what I previously referred to as a GCS bucket. Raw data in this sense means that the data is unstructured and did not exactly suit the way I wanted to visualize it. This brought about a problem, but what do they say about problems? They provide opportunities for solutions (you guessed right!).
To solve this problem, I decided to employ a tool by the name of dbt. DBT, short for "Data Build Tool," is an open-source command-line tool that helps data analysts and engineers transform and manage data within their data warehouses. DBT provides a framework for building and maintaining modular, reusable SQL code that can be tested and deployed in a repeatable manner.
With DBT, analysts and engineers can define SQL-based transformations as "models," which can then be combined into a DAG (Directed Acyclic Graph) of dependent transformations. This makes it easy to build complex data pipelines that can be version-controlled and automated.
Some key features of DBT include:
Modular, testable code: DBT allows users to define transformations as discrete, testable units of SQL code.
Incremental processing: DBT supports incremental processing, which means that only the data that has changed since the last run needs to be processed.
Automated documentation: DBT can automatically generate documentation for each transformation in a project, making it easy to understand the logic behind the data transformations.
Version control: DBT integrates with Git, allowing for version control of SQL code.
Integration with popular data warehouses: DBT can be used with a variety of popular data warehouses, including Snowflake, BigQuery, Redshift, and more.
I hope this gives you a clue as to what DBT is. I used this tool to define the schema of the raw data and to transform the raw data to fit the predefined schema using SQL.
The next tool was Apache Airflow. Apache Airflow is an open-source platform for creating, scheduling and monitoring complex data pipelines. It provides a way to programmatically author, schedule, and monitor workflows or data pipelines, allowing users to build and manage complex data processing pipelines in a way that is efficient, scalable, and maintainable.
At its core, Airflow is built around the idea of "Directed Acyclic Graphs" (DAGs), which represent a collection of tasks and their dependencies. Users can define tasks as Python functions or as predefined operators, such as "BashOperator" or "PythonOperator." These tasks can be arranged into DAGs, which can be scheduled to run at specific intervals or in response to certain events. Airflow also provides a web-based UI for monitoring pipeline progress and visualizing pipeline dependencies, making it easy to debug and troubleshoot complex workflows.
Some key features of Apache Airflow include:
Dynamic task generation: Airflow allows for dynamic task generation, which means that tasks can be added or removed from a DAG at runtime.
Extensible architecture: Airflow's modular architecture allows users to easily extend the platform with their own custom operators, sensors, and plugins.
Built-in operators: Airflow comes with a large library of built-in operators for common tasks, such as transferring data between databases, sending emails, or running Python scripts.
Integration with popular data warehouses: Airflow integrates with popular data warehouses like BigQuery, Redshift, and Snowflake, making it easy to orchestrate data processing pipelines across multiple platforms.
Using a Python script to tie these tools together and make them work together, I created a DAG from the Python script to define the DAGs and the necessary task dependencies. This whole architecture was then bundled into a Docker container and run on a Google Cloud Compute Instance.
So why the title "Orchestration?" Maybe! " Watch out for part 3b, or rather, part 4 of this instalment.
Have a joyous weekend!
Subscribe to my newsletter
Read articles from Warui Wanjiru directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Warui Wanjiru
Warui Wanjiru
I am a passionate and highly motivated Junior Data Engineer, driven by my curiosity and eagerness to explore the vast world of data. With a solid foundation in data analytics, programming, and database management, I thrive on the challenge of extracting, cleaning, transforming, and visualizing data to uncover valuable insights. My journey in the realm of data engineering has exposed me to various programming languages and tools, including Python, SQL, and Tableau. However, I don't stop there—I am constantly seeking new knowledge and skills to stay ahead of the curve. Currently, I am immersing myself in the world of Rust, harnessing its speed and efficiency prowess. Embracing this new language allows me to tackle complex data engineering tasks with even greater efficiency and effectiveness. What truly sets me apart is my genuine enthusiasm for learning and taking on new challenges. I thrive in dynamic environments that push me to think creatively and find innovative solutions. With a solid understanding of data structures and algorithms, I relish the opportunity to dive into complex datasets, unearthing patterns and unlocking actionable insights. Above all, I am dedicated to making a real impact through data engineering. I believe in the power of data to drive transformative change and improve decision-making processes. By harnessing the power of data, I strive to empower organizations to make informed choices and achieve tangible results. Let's embark on this exciting journey together, where I can contribute my authentic enthusiasm, my thirst for knowledge, and my unwavering commitment to delivering exceptional data solutions.