Character Sets vs. Collations in a MySQL Database Infrastructure
 DbVisualizer
DbVisualizer
Character sets and collations are a frequent point of confusion for programmers as well as database administrators alike – in this blog, we‘ll walk you through both of them. Excited already?
What Are Character Sets and Collations?
Character sets and collations are the frequently invisible backbone backing our data – character sets define characters that are considered to be OK to be used in text, and collations help sort the data in a specific fashion applicable to languages.
Both character sets and collations are necessary for our data to be displayed correctly – in MySQL, both character sets and related collations can be observed by running a query like so (for those who wonder, in this example we‘re using DbVisualizer as our SQL client):
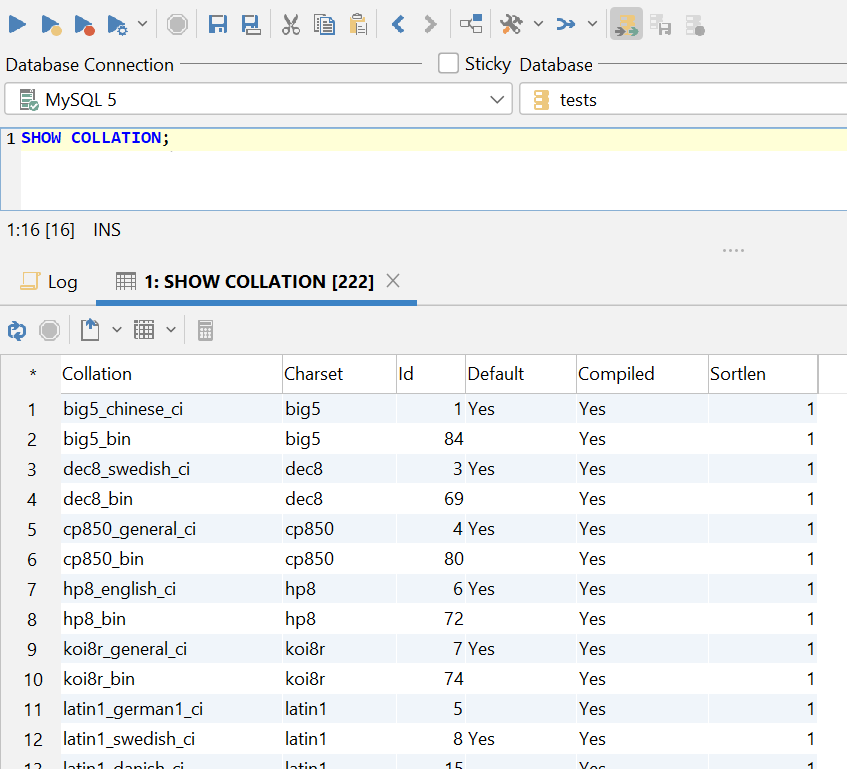
The collations available in MySQL.
As you can clearly see, there are rather a lot of collations and character sets associated with those collations – some of you might be a little confused why are there so many of those in the first place, but the answer here is relatively simple: there are so many collations because each language has specifics related to it (dialect, etc.) and each of those specifics need to come with a specific set of rules for comparing characters.
Default Character Sets and Collations
All collations in MySQL come with default character sets and vice versa – the default character set in most database management systems will be either latin1 (older versions of MySQL) or utf8 / utf8mb4 (newer versions of MySQL and the majority of other database management systems.)
latin1 character sets are a fit for data associated with Western European languages (most data within the English-speaking world.)
utf8mb4 character sets are a fit for those who want to support UTF-8 in their data (in MySQL, utf8 is not the same as utf8mb3 or utf8mb4 – we‘ll get into that later)
The big5_bin collation and their character sets are a fit for those supporting data of Chinese descent.
Collations tell the database how to sort the data – if the data we have is originating from an English-speaking part of the world, pretty much all collations will do, however, if we have Chinese, Japanese, Korean, or even Russian text, we‘re going to need to look into the character sets and collations that are being used a little deeper.
Choosing a Proper Character Set and Collation
Most database management systems will come with a query like the one we‘re running above – such queries will show us the collation and character sets associated with that collation to help us make an easier choice.
Yes, collations and character sets will most likely require research and digging into the documentation and most likely into community forums like StackOverflow as well, however, practice makes perfect.
Most people start choosing collations only after facing problems that look like the following:

Example of collation problems.
See the problem? No, not the double-commented piece of code on the first line – the fourth row from the top. See how the username is displayed by the database (we‘re running MySQL) and how it was inserted?
The main problem here is that the database doesn‘t understand the characters because the collation of the database doesn‘t come with such a character set that helps it be aware of the characters being inserted.
The main problem solved by collations and character sets is exactly that – they tell the database how to sort the data to avoid mishaps. Without character sets collations won‘t be aware of what characters to sort, and without collations, character sets won‘t be able to be displayed correctly.
To choose a proper character set and collation, consider the following questions:
What kind of data are you storing?
Where is the data derived from (approximate geographical area?)
Where is the data being displayed and what is the use case of it?
Answering the questions above will help you decide on where to go – if you‘re storing analytical data, the default character sets and collations are probably the least of your worries unless you‘re storing data derived from a specific geographical area that talks in a vastly different language than the western part of the world (think Chinese, Russian, Iranian, etc.) Finally, displaying data to a specific audience is also a point – if your audience doesn‘t speak English and instead is well-versed in Arabic languages, you will obviously adhere accordingly.
Coming back to the collations shown above, unfortunately, nor SQL clients nor database management systems will not tell you which collation is best to use with data belonging to what parts of the world. You will have to figure that out yourself, but that can be fun as well!
Help can be found in the documentation, and we suggest you combine information found there with questions answered in the database part of Stack Exchange to find the best answer to your specific situation. Answers will help you decide on when to use a specific collations and why – if you‘re lazy, you‘re in luck, because we‘ve provided answers to most of the questions concerning charsets and collations below as well.
What Collation and Character Set Should I Choose?
What collation and character set is best for general use cases?
Use whatever‘s provided by your database management system – in MySQL, the default character set is usually utf8mb4 (see answers to the questions below for its meaning), for other database management systems, the collations and character sets may differ, but if you don‘t have any specific requirements, its best to leave them intact.
How do I figure out which character set and collation to use if I need to support language X?
Have a look into the collations provided by your database management system, choose the one with the language name in it, then google around for solutions. You will find the answer fairly quickly.
What difference does a database-wide collation make?
Database-wide collations tell the database what kind of collations should be used by default when tables are created – if collations aren‘t specified upon table creation, the default collation will be used.
Is it bad to change collations when data is being used?
No – you might want to take a backup of your data before doing so though, because some collations may break the appearance of certain characters.
Why are there so many collations and character sets?
The reason why is because there are a lot of languages developers work with and a lot of dialects specific to those languages – database management systems need to be able to support most of them.
When should I change collations and character sets?
Consider changing the collations and character sets as soon as you find yourself working with data from a different part of the world than usual.
Why do utf8mb* collations exist?
These collations exist because the number after mb is a sign for how many bytes of data a specific character can hold – for example, utf8mb4 means that one character can hold 4 bytes of data.
Is utf8 the same as utf8mb*?
No – if you need to support UTF-8, use utf8mb4 as your collation instead of using utf8 (see answer above for the reason why.)
Database Maintenance and Charsets
Contrary to what you might be thinking, character sets and collations don‘t require much maintenance – they are in place as sort of support agents for database management systems for them to realize how best to sort data.
It‘s not to say that database management systems don‘t need maintenance, though: most of them do, and if you find yourself using database clients like DbVisualizer, you‘re already on a very good path – its SQL editor functionality will help you build and visualize your queries, and the tool itself will become a very good personal assistant to explore your databases from the inside.
The tool comes with robust security features such as the ability to let you set a local master password:
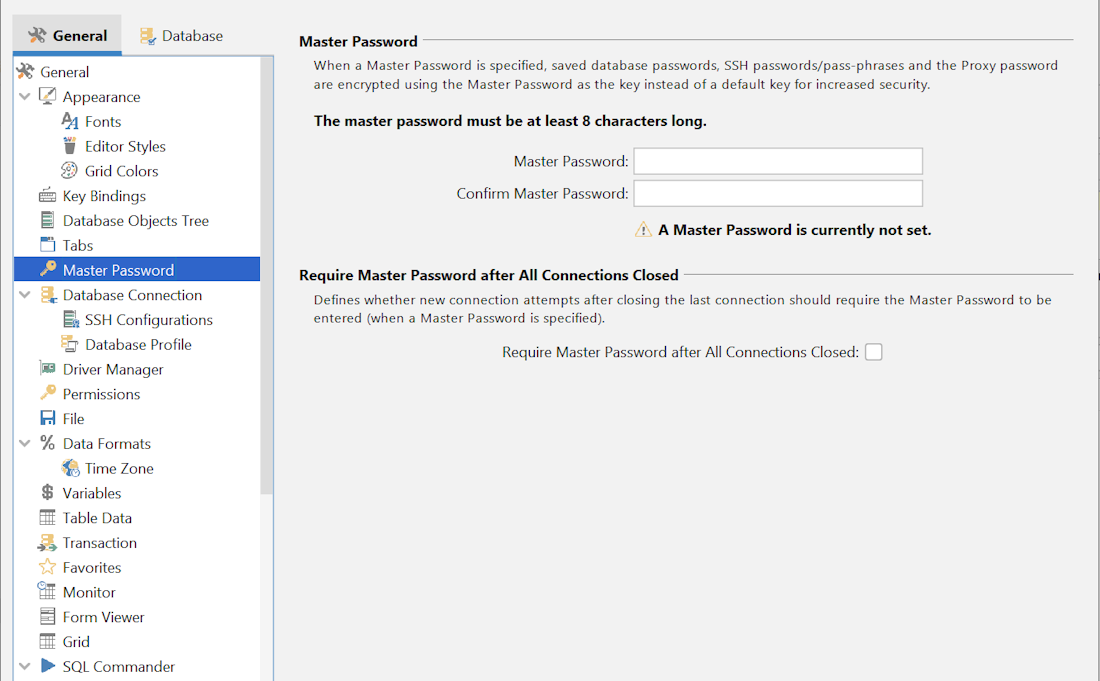
Setting a master password in DbVisualizer.
DbVisualizer provides you with the ability to help you access your data via SSH and other measures as well – did you try it yet?
The tool even lets you set the date, time, and number formats when editing data:
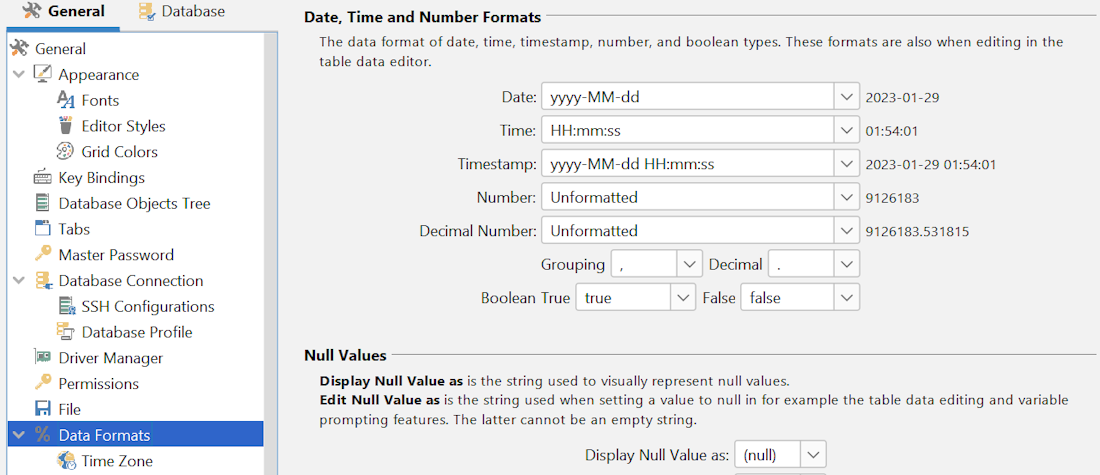
Setting the formats of date, time and numbers in DbVisualizer.
Its support for various database management systems (see image below) only adds to the fun – grab a free trial and start using it today!
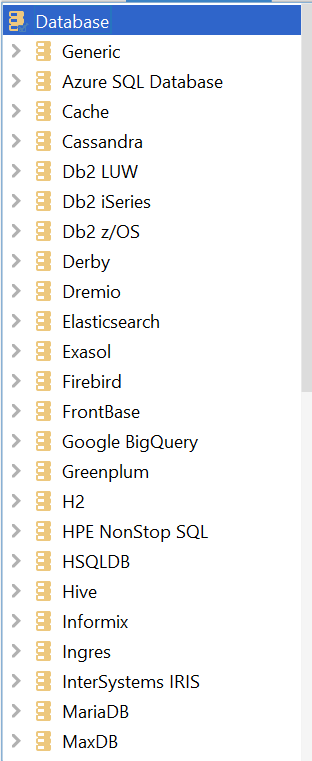
Databases supported by DbVisualizer.
Conclusion
Character sets and collations are an integral part of any database management system – in this blog we‘ve walked you through their implications in a MySQL database infrastructure, however, the concept remains the same and the core premise of them doesn‘t change no matter what kind of database management system is in use.
Explore our blog for more news around the database space, and until next time!
About the author
Lukas Vileikis is an ethical hacker and a frequent conference speaker. He runs one of the biggest & fastest data breach search engines in the world - BreachDirectory.com, frequently speaks at conferences and blogs in multiple places including his blog over at lukasvileikis.com.
Subscribe to my newsletter
Read articles from DbVisualizer directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
DbVisualizer
DbVisualizer
DbVisualizer is the database client with the highest user satisfaction. It is used for development, analytics, maintenance, and more, by database professionals all over the world. It connects to all popular databases and runs on Win, macOS & Linux.