Mastering SQL Server Query Optimization: Key Concepts, Terms, and Tips for Lightning-Fast Performance
 Shiladitya Mukerji
Shiladitya Mukerji
Introduction
Are your SQL Server queries running slowly? Don't worry, you're not alone. Performance issues are a common problem that developers face when working with SQL Server. Fortunately, there are several quick and easy tips you can use to optimize your queries and improve performance. In this blog, we'll explore some of the most common performance bottlenecks, and provide practical solutions for optimizing your queries.
Before we get started on how to speed up queries, I will have to introduce you to some terms and concepts.
Data Pages and Binary Trees
To understand how to optimize your queries, it's important to understand how data is stored in SQL Server. SQL Server stores data in 8KB data pages, which are organized into a binary tree structure. Each level of the tree is called a node, and each node contains pointers to the child nodes. This structure makes it easy to quickly search for and retrieve data. I will explain these concepts in greater detail in the next section.
Clustered and Non-Clustered Index
SQL Server supports two types of indexes: clustered and non-clustered. A clustered index determines the physical order of data in a table, while a non-clustered index provides a separate structure for fast access to data. Clustered indexes are especially useful for tables that are frequently sorted or filtered, while non-clustered indexes are better for columns that are frequently searched or joined.
Clustered Index Binary Tree
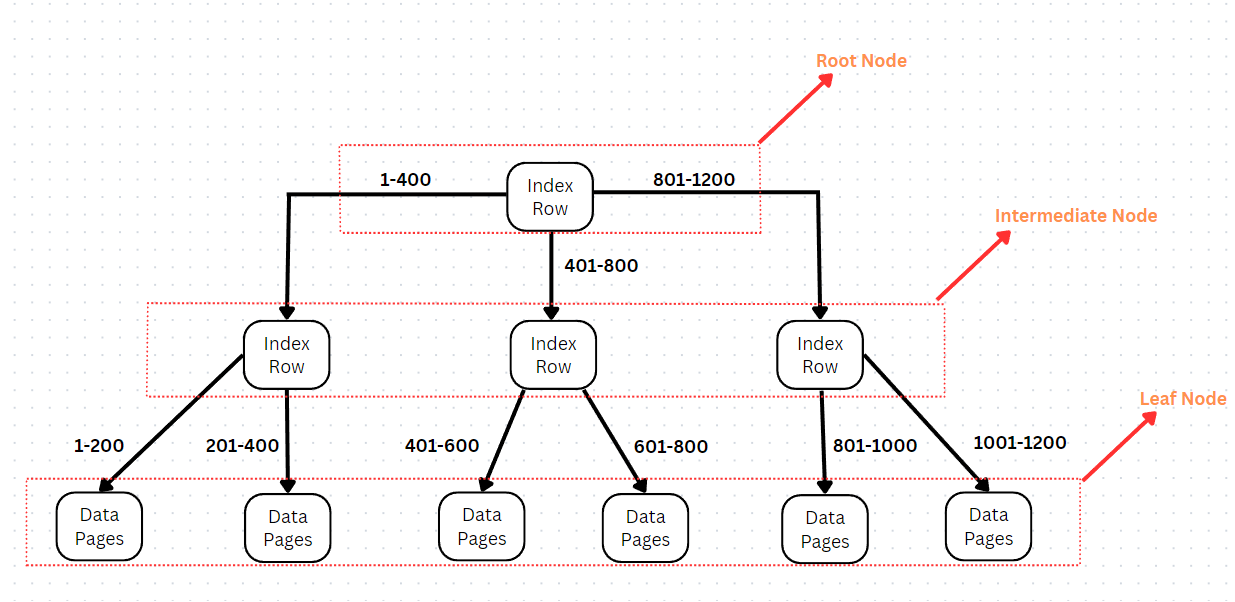
The diagram above shows the binary tree structure of a clustered index. The clustered index physically alters the structure of the table. One table can only have one clustered index. The top layer is called the root node. The last layer which contains the data pages is referred to as the leaf nodes. All the layers that come between these two layers are known as the intermediate nodes. The root node and the intermediate nodes point to the data pages, this makes the task of interacting with data extremely efficient. This example contains rows numbered 1 - 1200 in the form of data stored in the data pages. Now if you want to access the row number 1124 then you would take the following path.
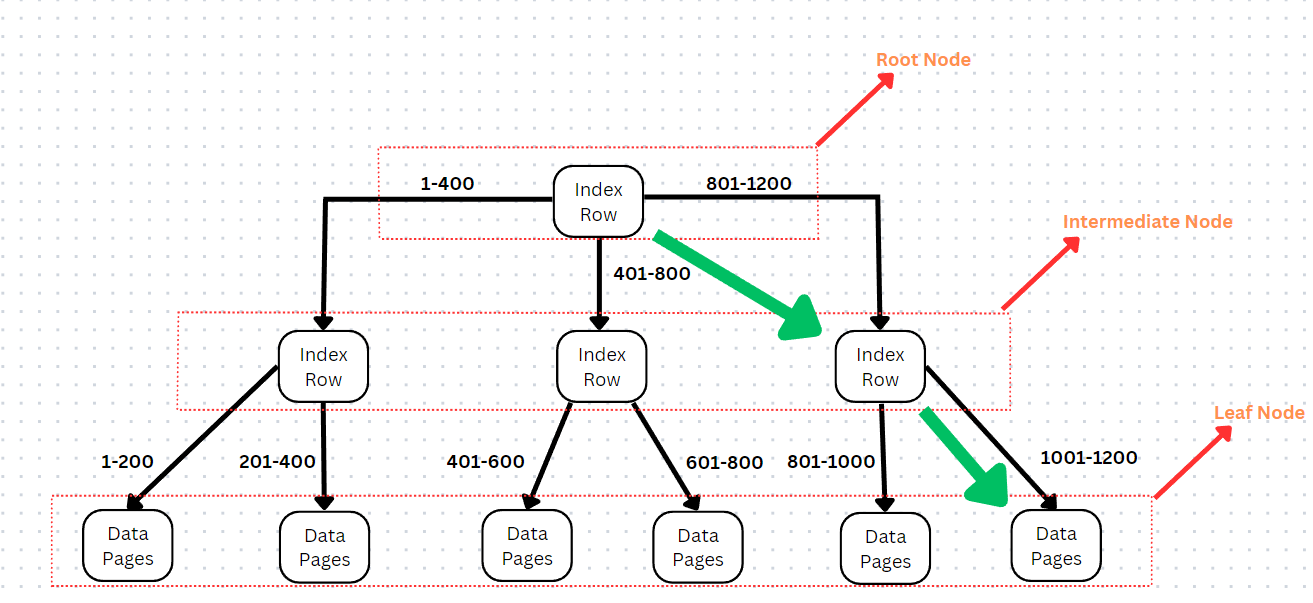
To break it down, the right limb of the root node leads to the values between 801-1200, similarly the right limb of the 3rd intermediate node contains values between 1001-1200. That is how you can retrieve row number 1124 by following the path highlighted in green.
Non-clustered Index Binary Tree
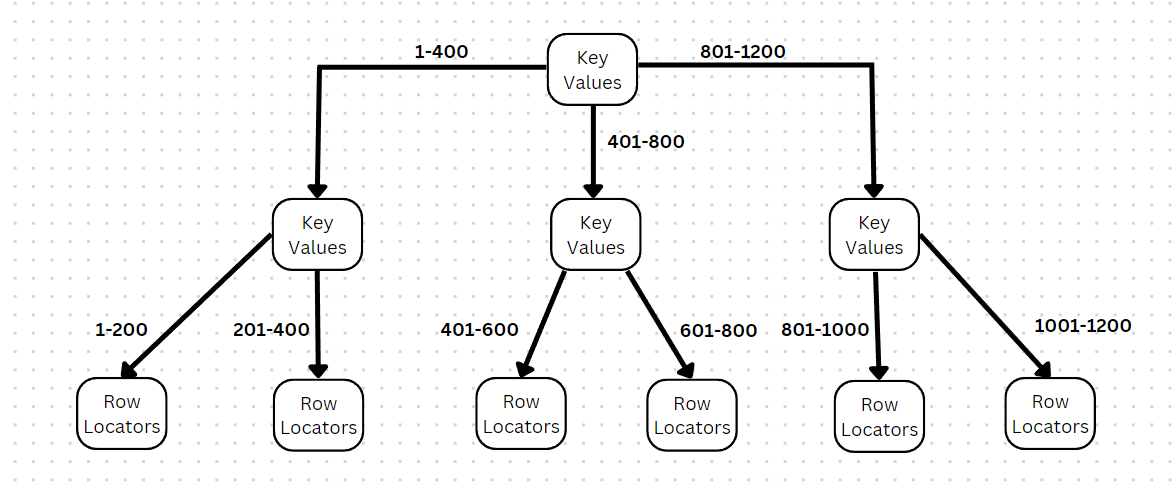
The above diagram represents the binary tree of a non-clustered index. Unlike the clustered index binary tree this does not physically alter the structure of the table. It is created as a separate structure that points to the actual row in the table and hence you can see that the last layer of the tree is referred to as row locators. This makes it possible for a table to have more than one non-clustered indexes.
Heap Table
A heap table is a table that doesn't have a clustered index but it may have one or more non-clustered indexes. Because data is not stored in any particular order, queries that require data to be sorted or filtered can be slower. In general, it's a good idea to avoid heap tables whenever possible.
Table Scan
A table scan occurs when SQL Server reads every row in a table to retrieve data and is used when a table has no kind of indexing at all. Table scans can be slow and inefficient, especially for large tables but can be the right choice for a table with a small amount of data. To avoid table scans, it's important to use indexes whenever possible.
But in case you are not using an index then table scan would get the job done in the following way. For example, if you have a table called "Customers" with columns "CustomerID", "FirstName", "LastName", and "City", and you want to find all customers who live in "Seattle", but there is no index on the "City" column, SQL Server will have to perform a table scan to find all the matching rows. This can be slow and inefficient, especially for large tables.
-- Query using a table scan
SELECT *
FROM Customers
WHERE City = 'Seattle'
Index Scan and Index Seek
An index scan occurs when SQL Server reads every row in an index to retrieve data that matches the query conditions. Index scans can be faster than table scans, but they can still be slow and inefficient for large indexes.
For example, if you have an index on the "LastName" column of the "Customers" table and you want to find all customers whose last name starts with "S", SQL Server may use an index scan to read through all the pages of the "LastName" index to find all the matching rows. This can be more efficient than a table scan because the index pages are usually smaller than the data pages, but it can still be slower than an index seek.
-- Query using an index scan
SELECT *
FROM Customers
WHERE LastName LIKE 'S%'
An index seek, on the other hand, occurs when SQL Server uses an index to locate a specific row or set of rows that match the query conditions. Index seeks are much faster than scans, and should be used whenever possible.
For example, if you have an index on the "City" column of the "Customers" table, SQL Server can use an index seek to find all customers who live in "Seattle" by quickly locating the rows that match the search criteria. This is much faster than a table scan and can significantly improve query performance.
-- Query using an index seek
SELECT *
FROM Customers
WHERE City = 'Seattle'
-- Assume that there is an index on the "City" column
-- SQL Server can use the index to quickly locate the rows that match the search criteria
Tips for Improving Query Performance
Use Indexes - Indexes can significantly improve query performance by allowing SQL Server to locate and retrieve data more efficiently. For example, suppose you have a table called "Customers" with columns "ID", "Name", and "Email". To improve the performance of a query that filters by email address, create a non-clustered index on the "Email" column:
CREATE NONCLUSTERED INDEX EmailIndex ON Customers(Email); SELECT * FROM Customers WHERE Email = 'example@email.com';Avoid Table Scans - Table scans can be slow and inefficient, especially for large tables. To avoid table scans, use indexes whenever possible. For example, suppose you have a table called "Orders" with columns "ID", "CustomerID", and "OrderDate". To improve the performance of a query that filters by customer ID, create a non-clustered index on the "CustomerID" column:
CREATE NONCLUSTERED INDEX CustomerIDIndex ON Orders(CustomerID); SELECT * FROM Orders WHERE CustomerID = 1234;Use WHERE Clauses - Using WHERE clauses to filter data can significantly improve query performance by reducing the amount of data that needs to be processed. For example, suppose you have a table called "Products" with columns "ID", "Name", "CategoryID", and "Price". To improve the performance of a query that filters by category ID and price, use a WHERE clause:
SELECT * FROM Products WHERE CategoryID = 5 AND Price > 50;Avoid Wildcard Characters - Using wildcard characters such as '%' and '_' in LIKE statements can significantly reduce query performance. For example, suppose you have a table called "Employees" with columns "ID", "Name", and "Email". To improve the performance of a query that searches for employees whose email addresses contain the word "example", use the following statement instead of using a wildcard:
SELECT * FROM Employees WHERE Email LIKE 'example%@%';Minimize Joins - Joining tables can be slow and resource-intensive, especially for large tables. To improve query performance, minimize the number of joins in your queries whenever possible. For example, suppose you have two tables called "Orders" and "Customers". To improve the performance of a query that lists all orders and their corresponding customer names, use a subquery instead of a join:
SELECT ID, OrderDate, (SELECT Name FROM Customers WHERE ID = Orders.CustomerID) AS CustomerName
FROM Orders;
Conclusion
By following these tips and best practices, you can significantly improve the performance of your SQL Server queries. Use indexes whenever possible, avoid table scans, use WHERE clauses to filter data, avoid wildcard characters and minimize joins. With these techniques, you'll be well on your way to achieving lightning-fast query performance in SQL Server.
Subscribe to my newsletter
Read articles from Shiladitya Mukerji directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Shiladitya Mukerji
Shiladitya Mukerji
A Software engineer with an absolute desire for pursuit of quality and fulfilling ambitions. Someone with a passion for learning and sharing.