The Google File System - Case Study
 Samuel Sorial
Samuel Sorial
Introduction
The Google file system's main goal is to support their applications' workload. Which affected their design decisions, they implemented what they actually need, rather than the de-facto distributed file system.
There are 4 main different decisions that they made in their design:
Failures are the default, not the exception. This means that the system is running assuming that some parts are down and won't come back alive again.
Files are huge, for a company like Google, it's more common to have GBs files rather than KBs files.
Access & Update Patterns: Files are read sequentially, not randomly. Also, it's more popular to update files by appending them.
Co-designing the application with the file system API gives huge flexibility to the design.
Note: Google doesn't use GFS anymore, as they invented another file system that they are using in their cloud.
Design
Assumptions
The system is running on many commodity machines, which means that they fail, so they must detect and handle failures correctly. They store huge files and sometimes small files, but it's optimized for bigger ones.
Reads happen in two ways, large amounts of sequential data, and some random small data. It's optimized for the bigger ones, and it's left for the application developers to optimize their fetches of small data, by sorting and batching instead of going back and forth.
Write workload is typically huge data written to the end of the file, once a file is written, it's usually not edited. So, updating data randomly in given offsets is supported but not optimized.
As the main usage of it will be in the producer-consumer pattern, it's important to support synchronization ways to append files with the least amount of work.
Bandwidth is more important than latency, as the applications that process huge data don't pay attention to latency, instead, they look for high throughput of data.
Interface
While it share many operations with the standard API of file systems like POSIX, it had two additional important operations. Snapshot creates a copy of a file or directory in a low cost, and append that helps the clients to append concurrently to the same file without worrying about concurrency problems. It's very useful in the context of pub-sub applications, and multi-way merge results apps.
Architecture
The cluster contains a single master and multiple chunkservers that are accessed by multiple clients. Each chunk server is a low-cost Linux machine, and it's possible to run both chunkserver and client on the same machine but pay attention to the flaky code of applications that may increase the chances of the server being down.
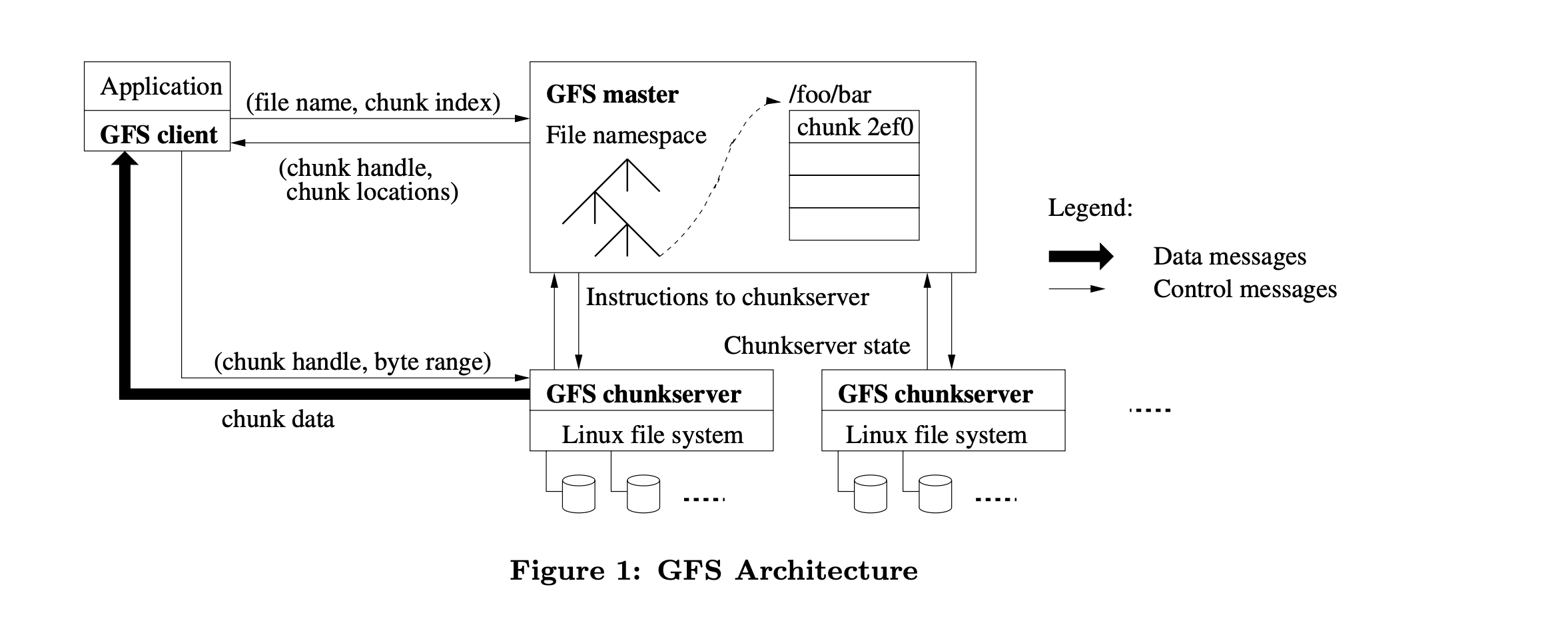
Each file is divided into many fixed-size chunks, each chunk is identified by a unique 64-bit chunk handle that got assigned to it by the master in the creation of this chunk. Chunks are replicated among different chunkservers to keep them reliable, it's replicated into 3 by default but users can change the replication settings.
The master contains only meta-data about chunks, it also controls operations like chunk lease management, garbage collection of orphaned chunks, chunk migration between servers, and most importantly communication with chunk servers with HeartBeats to give instructions and collect stats.
The cache is not used widely in GFS, as the file sizes are huge, and it's not efficient to keep caching huge files. It plays an important role in simplifying the design by eliminating the hassle of keeping track of cache coherence. However, sometimes client uses a cache to prevent multiple calls to master in order to know where the chunk is located, and also the underlying Linux buffer cache is already caching some of the highly accessed data in the server.
Key Points of Architecture
Single master: It simplifies the design, and enables the master to make decisions using global knowledge. But it can become a bottleneck, so it was decided to minimize the interaction between it and the client. The client never reads from a master, it only asks the master for the location of a specific chunk, and this data is cached in the client.
Chunk size: Having a 64 MB chunk size may have been problematic if it was not paired with lazy allocation, as it reduces fragmentation. Also, it reduces the client interactions with the master, reduces network usage because the client can utilize a single TCP connection to retrieve a bigger amount of data, lastly, it keeps the size of metadata in the master low. Conversely, small files become problematic, as the chunk servers storing some small files consisting of single chunks may become hot spots rapidly. So in this case it's better to have a higher replication factor for small files that may become hot spots.
Metadata in master
The master node stores: chunks and files namespaces, the mapping of files to chunk handles, and chunk handles mapping to chunk servers that contain it. It's important to keep the namespaces and files to chunk handles persistent on disk, so it was decided to add them in the operation log along with the in-memory data structures. Keeping those data in memory can be limiting, but as it only stores 64 bytes per 64MB chunk, it was an acceptable choice.
The master doesn't keep a persistent log of chunk locations, it's more reasonable to ask each chunk server about which chunks it contains in the master node restart. Making the chunk server single point of truth about which chunks it contains because it's the only one that can determine if it has a specific chunk or not.
Keeping an operation log is critical to preserve important data changes like the creation of chunks, or appending. It's also playing a huge part in keeping data consistent even on failures, by flushing logs to disk before responding to the client, with adding another layer of replication for the log, data losses become less. Checkpoints are made during execution, it's algorithm is designed to keep the master serving while the checkpoint is being taken.
Consistency Model
GFS has a somehow relaxed consistency model that aims to serve the needs of the applications that use it. It handles namespace and chunk creation atomically as there is only one master node, with an operation log that flushes data to disk to preserve them in case of failures. There are 3 different states for file regions that exist in GFS after mutation:
Consistent: This means that reading the same region from all replicas will give the same data.
Defined: It's consistent and gives the whole data that was written in the latest successful mutation.
Inconsistent: Mutation failed to change data over the different replicas, so it becomes undefined for a while until the master resolves it.
GFS applications accommodate this relaxed model by implementing some techniques to keep sure it fits their needs such as using append instead of overwrite, checkpointing, and writing self-validating records with checksums inside it if needed. Record append is at-least-once, which means that it may duplicate data on some replicas, if it's not accepted in the application level, adding unique ids to regions appended can help applications to detect such duplications.
System Interactions
Leases and Mutations
For each chunk handle, the master chooses a server that is responsible for organizing data mutations on this chunk, it's called primary. It grants it a lease with expiration after 60 seconds, after that, it chooses another one or gives the primary additional time if it has requested that piggybacking heartbeat request. It's important to note that the primary knows the expiration of the lease, and it refuses any mutations after that expiry. So if the master is dead, and the client is already changing something, it will stop at the expiration. The master can then choose another primary when it comes back.
Mutation steps:
The client asks the master for the primary chunk to be modified.
The master replies with the primary and secondaries holding replicas.
Client forward data (without mutation operation) to nearest node.
The client sends the operations it needs to primary.
Primary decides the order of operations and sends it to other replicas.
Replicas respond to primary if it's successfully applied the same operations in the same order.
Primary replies to clients with success.
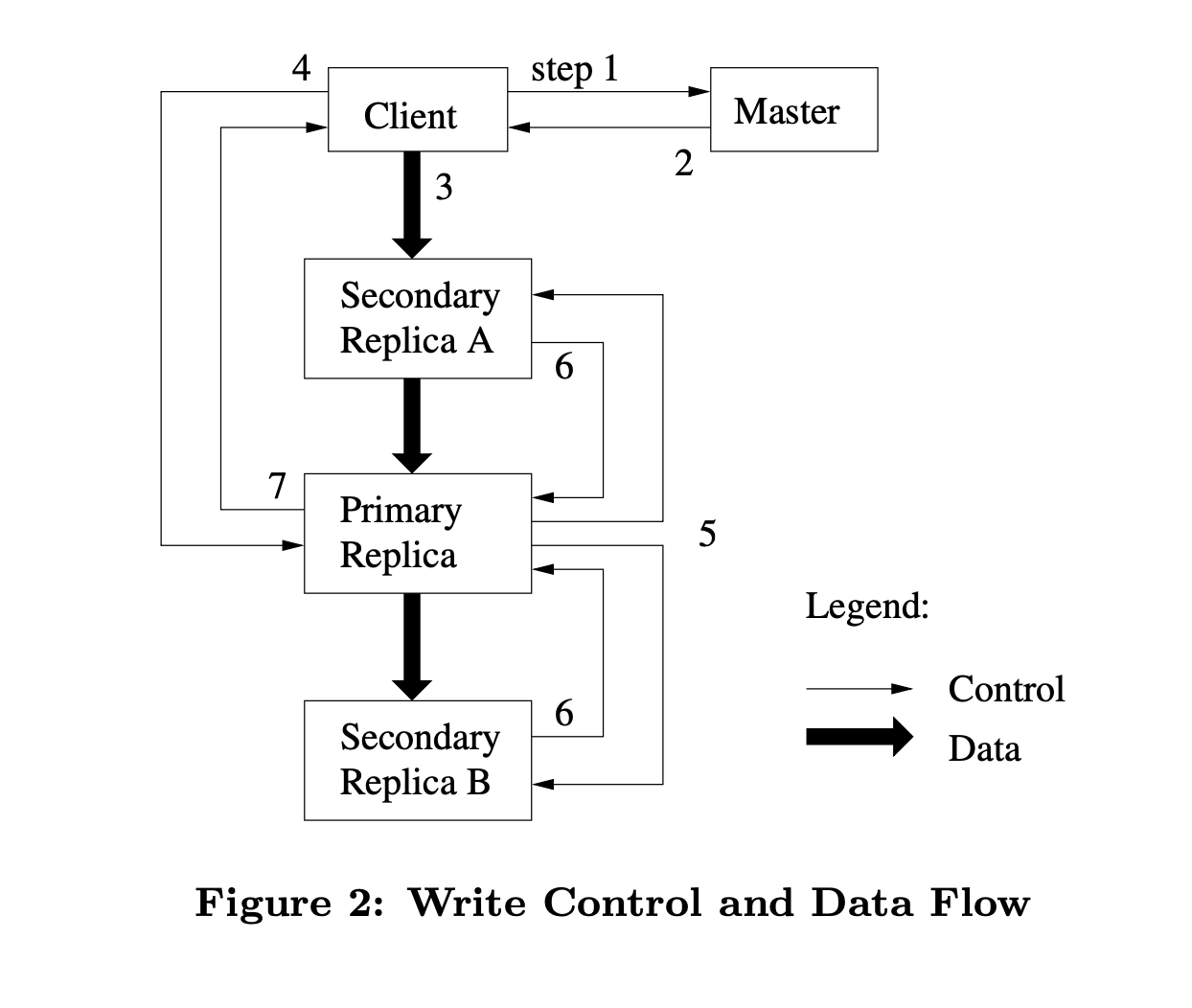
Data flow
Decoupling data flow from control flow is an intelligent decision to maximize the utilization of the network. It starts by choosing the nearest node to push data into it, which starts pipelining data to other nodes from the first byte it receives, making the best usage of TCP connections. Later when data is fully received on all nodes, the client can start sending commands to specify what operations it needs to be done with this data.
Master Operations
Namespace Management
In order to support snapshotting, the master needs to utilize locks to prevent having incorrect data. Hence, it's important to design lock granularity carefully to reduce the waiting time for such operations. For example, appending to a file requires taking read locks on all directory paths that contain this file, and a write on that specific one. By following this scheme, it allows different locks to be taken on files in the same directory. Also, it prevents deadlocks from happening as locks are taken in a consistent order, from top to bottom, and lexicographically ordered on the file level.
Replica Placement
Spreading data in different replicas is not enough to ensure that it's available and makes the best utilization of the network, it's also important to pick replicas such that data is replicated within different racks. This ensures that if something happens to a specific rack, data is not lost. It also has the advantage that reading data can make us of having it replicated on different racks, but it also has the drawback that mutation flow is passing through different racks, which is acceptable in this case.
Garbage Collection
When a file is deleted, the master logs the deletion but renames the file to a hidden name that includes the deletion timestamp. The file isn't physically removed until a regular scan of the file system namespace, which happens every three days (configurable). During this period, the file can be read under its new name or even undeleted. When finally removed, its in-memory metadata is erased, disconnecting it from all its chunks.
In a similar way, the master scans for orphaned chunks (those not associated with any file) and erases their metadata. Each chunk server reports a subset of its chunks during regular HeartBeat messages exchange with the master, which in turn instructs the chunk server which chunks to delete based on its metadata records.
This garbage collection approach simplifies storage reclamation in a large-scale distributed system, especially where component failures are common. It allows for the efficient cleanup of unnecessary replicas and merges storage reclamation into regular background activities, making it more reliable and cost-effective. This approach also provides a safety net against accidental irreversible deletion.
However, the delay in storage reclamation can be a disadvantage when fine-tuning usage in tight storage situations or when applications frequently create and delete temporary files. To address this, GFS allows for expedited storage reclamation if a deleted file is explicitly deleted again. It also offers users the ability to apply different replication and reclamation policies to different parts of the namespace.
Stale Replica Detection
chunk replicas can become stale if a chunkserver fails and misses updates to the chunk during its downtime. To manage this, the master maintains a chunk version number to differentiate between up-to-date and stale replicas.
Whenever the master grants a new lease on a chunk, it increases the chunk's version number and notifies the up-to-date replicas. Both the master and these replicas record the new version number in their persistent state before any client is informed, hence before any writing to the chunk can commence. If a replica is unavailable at this time, its version number remains unchanged. The master identifies stale replicas when the chunkserver restarts and reports its chunk and version numbers. If the master notices a version number higher than its record, it assumes its previous attempt to grant the lease failed, and considers the higher version as up-to-date.
The master removes stale replicas during its regular garbage collection, effectively treating them as non-existent when responding to client requests for chunk information. As an additional precaution, the master includes the chunk version number when informing clients about which chunkserver holds a lease on a chunk, or when it instructs a chunkserver to read the chunk from another chunkserver during a cloning operation. The client or chunkserver verifies this version number during operations, ensuring that it always accesses up-to-date data.
References:
This case study is created after careful reading of the GFS paper written by Google engineers, if you think there's anything wrong please contact me.
- Ghemawat, S., Gobioff, H., & Leung, S. T. (2003). The Google File System. In Proceedings of the nineteenth ACM symposium on Operating systems principles - SOSP '03 (pp. 29-43). ACM Press. https://doi.org/10.1145/945445.945450
Subscribe to my newsletter
Read articles from Samuel Sorial directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Samuel Sorial
Samuel Sorial
A software engineer who is enthusiast about back-end engineering and system design with a flexible mindset. I love playing with frameworks and moving between the languages just like an artist playing