Unlocking the Power of Data: Mastering Machine Learning Imputation Techniques with Mathematical Precision (PART 2):
 Naveen Kumar
Naveen KumarINTRODUCTION
In Part 2 of our blog series on missing data imputation techniques, we will explore the K-Nearest Neighbors (KNN) imputation method. KNN imputation is a powerful approach for handling missing values by leveraging the concept of similarity between data points.
In this blog post, we will delve into the workings of several distance metrics and KNN imputation and its practical implementation using the scikit-learn library in Python. We will explore the underlying principles of KNN imputation, including the calculation of distances between data points and the determination of nearest neighbors.
TYPES OF DISTANCE METRICS
The most commonly used metrics for distance calculation in data points are as follows:
Euclidean Distance
Manhattan Distance (City Block Distance)
Chebyshev distance
Minkowski Distance
Cosine Similarity
EUCLIDEAN DISTANCE
Euclidean distance, also known as the Euclidean norm or Euclidean metric, is a measure of the straight-line distance between two points in a two-dimensional space.
It is named after the ancient Greek mathematician Euclid.
FORMULA :
Euclidean distance between two points (x1, y1) and (x2, y2) is given by:
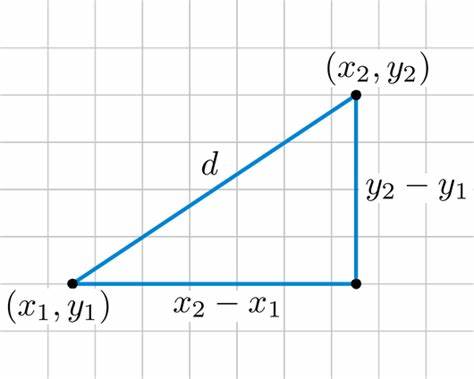
$$distance= sqrt((x2 - x1)^2 + (y2 - y1)^2)$$
EXAMPLE :
Consider two data points A(2, 3) and B(5, 7). The Euclidean distance between them is :
d=sqrt((5 - 2)^2 + (7 - 3)^2) = sqrt(9 + 16)
d= sqrt(25)
d = 5
MANHATTAN DISTANCE
Manhattan distance, also known as the city block distance or taxicab distance, is a measure of the distance between two points in a two-dimensional space that is calculated by summing the absolute differences between their coordinates along each dimension.
FORMULA :
Manhattan distance between two points (x1, y1) and (x2, y2) is given by:
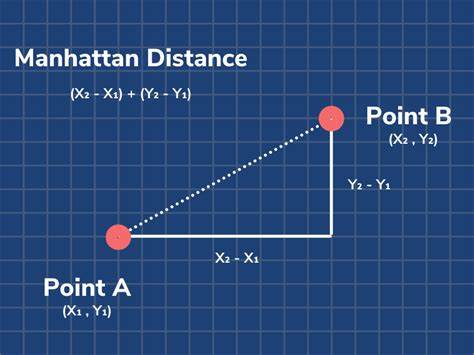
$$distance=|x2 - x1| + |y2 - y1|$$
EXAMPLE :
Consider two data points A(2, 3) and B(5, 7). The Manhattan distance between them is:
d=|5 - 2| + |7 - 3|
d= 3 + 4
d= 7
CHEBYSHEV DISTANCE
Chebyshev distance, also known as chessboard distance or the infinity norm is a measure of the distance between two points in a two-dimensional space.
It is named after the Russian mathematician Pafnuty Chebyshev.
FORMULA :
The Chebyshev distance between two points (x1, y1) and (x2, y2) is given by:
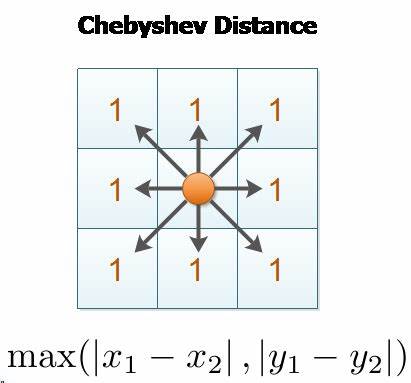
$$distance=max(|x2 - x1|, |y2 - y1|)$$
EXAMPLE :
Consider two data points A(2, 3) and B(5, 7). The Chebyshev distance between them is:
d=max(|5 - 2|, |7 - 3|)
d= max(3, 4)
d= 4
MINKOWSKI DISTANCE
The Minkowski distance is a generalized distance metric that includes Euclidean distance, Manhattan distance, and Chebyshev distance as special cases, depending on the value of the parameter 'p'.
FORMULA :
The formula for Minkowski distance of order p between two points (x1, y1) and (x2, y2) is given by:

$$distance=((|x2 - x1|^p + |y2 - y1|^p)^(1/p))$$
When p = 2, the Minkowski distance reduces to the Euclidean distance.
When p = 1, the Minkowski distance reduces to the Manhattan distance.
When p = infinity (∞), the Minkowski distance reduces to the Chebyshev distance.
COSINE SIMILARITY
Cosine similarity is a measure that calculates the cosine of the angle between two non-zero vectors, providing a value between -1 and 1 to represent the similarity or dissimilarity of the vectors.
FORMULA :
Cosine similarity between two vectors x and y is given by :
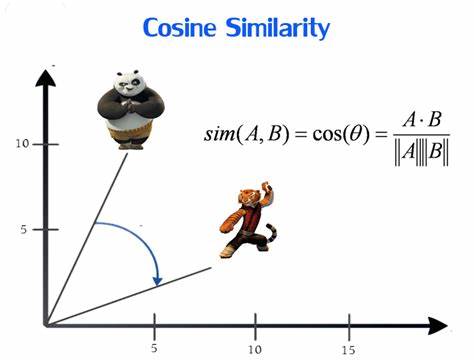
$$cos(θ)=(x . y) / (||x|| * ||y||)$$
Where
$$||x|| = sqrt(x1^2 + x2^2 + ... + xn^2) \ \ \ \ \ \ \ \ \ ||y|| = sqrt(y1^2 + y2^2 + ... + yn^2)$$
EXAMPLE :
Consider two vectors x = [2, 3] and y = [5, 7]. The cosine similarity between them is:
x.y=(2*5)+(3*7)
= 31/ (sqrt(2^2 + 3^2) * sqrt(5^2 + 7^2))
= (10 + 21) / (sqrt(13) * sqrt(74))
= 31 / (sqrt(13) * sqrt(74))
= 31/sqrt(962)
=0.99
Here, we explore some distance metrics which are related to KNN algorithm. Now, let's dive into KNN-Imputation.
KNN-IMPUTATION
KNN Imputation is a data imputation technique that leverages the concept of proximity to estimate missing values in a dataset. It operates under the assumption that similar data points tend to have similar attribute values. KNN Imputation replaces missing values with estimates based on the values of their K nearest neighbors.
FORMULA :
To impute the value
imputed=sqrt(weight*squared_distance_from_present_corrdinates)
Here, weight is given by
weight= Total number of coordinates / Number of present coordinates
STEPS :
Choose the first column with the missing value to fill in the data.
Select the values in a row.
Choose the number of neighbors you want to work with. It is denoted by K.
Calculate Euclidean distance from all other data points corresponding to each other in the row.
Select the smallest K neighbors. Repeat the process until all the missing values in corresponding columns get imputed.
EXAMPLE :
Let's consider the example data
| A | B | C | D |
| 1 | 1 | 1 | 5 |
| 2 | 2 | 2 | 4 |
| 8 | None | 3 | 3 |
| None | 4 | 4 | 2 |
| 5 | None | 5 | 1 |
In this data there are 3 missing values i.e. [row 3][column A], [row2][column B] and [row4][column B]. Use K neighbors (K=3)
Solution :
We will apply 'euclidean_distance' metrics to impute the data
Step1 :
Choosing the column with the first missing value here COLUMN A
By applying the weight formula for column A and (x-y)^2 for all other rows except row 3.
| A | B | C | D |
| weight(A) | (row[3]-row[i])^2 | (row[3]-row[i])^2 | (row[3]-row[i])^2 |
| 3/3=1 | (4-1)^2 =9 | (4-1)^2 =9 | (2-5)^2=9 |
| 3/3=1 | (4-2)^2=4 | (4-2)^2=4 | (2-4)^2=4 |
| 3/2=1.5 | - (bcz contains None) | (4-3)^2=1 | (2-3)^2=1 |
| locked row | - | - | - |
| 3/2=1.5 | - (bcz contains None) | (4-5)^2=1 | (2-1)^2=1 |
Step 2:
Now, Apply a formula for each row
Formula:
imputed=sqrt(weight*squared_distance_from_present_corrdinates)
For row[0]:
imputed_row[0]=sqrt(weight(A)*(B+C+D))
imputed_row[0]=sqrt(1*(9+9+9))=sqrt(27)
imputed_row[0]=5.19 ___________________(1)
For row[1]:
imputed_row[1]=sqrt(weight(A)*(B+C+D))
imputed_row[1]=sqrt(1*(4+4+4))=sqrt(12)
imputed_row[1]=3.46 ____________________(2)
For row[2]:
imputed_row[2]=sqrt(weight(A)*(B+C+D))
imputed_row[2]=sqrt(1.5*(1+1))=sqrt(3)
imputed_row[2]=1.73 _____________________(3)
For row[4]:
imputed_row[4]=sqrt(weight(A)*(B+C+D))
imputed_row[4]=sqrt(1.5*(1+1))=sqrt(3)
imputed_row[4]=1.73 _____________________(4)
Step 3:
Given k=3
choosing 3 nearest neighbors from (1),(2),(3),(4)
The 3 nearest neighbors are rows 1,2,4
From table row[1]=2,row[2]=8,row[4]=5
Average=(2+8+5)/3
Imputed value
Average=5.0
Repeat these steps for [row2][column B] and [row4][column B]
Finally, we get imputed values
Imputed table
| A | B | C | D |
| 1 | 1 | 1 | 5 |
| 2 | 2 | 2 | 4 |
| 8 | 2.3 | 3 | 3 |
| 5 | 4 | 4 | 2 |
| 5 | 2.3 | 5 | 1 |
Below is the code for the above example.
CODE :
import pandas as pd
from sklearn.impute import KNNImputer
# Create the sample dataset with missing values
df = pd.DataFrame({'A': [1,2,8,None,5],
'B': [1,2,None,4,None],
'C': [1,2,3,4,5],
'D': [5,4,3,2,1]})
# Instantiate the KNNImputer with k=3 (3 nearest neighbors)
imputer = KNNImputer(n_neighbors=3)
# Perform the imputation
df_imputed = pd.DataFrame(imputer.fit_transform(df), columns=df.columns)
# Print the imputed dataset
print(df_imputed)
OUTPUT :
A B C D
0 1.0 1.000000 1.0 5.0
1 2.0 2.000000 2.0 4.0
2 8.0 2.333333 3.0 3.0
3 5.0 4.000000 4.0 2.0
4 5.0 2.333333 5.0 1.0
NOTE: Default metrics in kNN imputation is 'nan_euclidean' we can change metrics based on our data.
For example, we can use 'nan_manhattan', 'nan_cosine', 'nan_minkowski' etc...
Summary of the scenarios where each distance metric is commonly used
| Distance Metric | Scenario |
| Euclidean Distance | Used when dealing with continuous numerical features. |
| Manhattan Distance | Suitable for measuring distance in grid-like structures or when dealing with categorical or ordinal features. |
| Chebyshev Distance | Ideal for scenarios where you want to measure the maximum difference between any pair of feature values. |
| Minkowski Distance | Generalization of both Euclidean and Manhattan distances. The parameter p can be adjusted to prioritize specific features or distance characteristics. |
| Cosine Similarity | Well-suited for measuring the similarity between documents or text-based data, as it focuses on the angle between feature vectors rather than their magnitudes. It's also used in collaborative filtering and recommendation systems. |
NOTE: Remember that these guidelines are not rigid rules, and the choice of distance metric should be based on the specific characteristics of your data and the requirements of your problem.
CONCLUSION
In conclusion, distance metrics and KNN imputation are essential concepts in machine learning. Distance metrics quantify similarity or dissimilarity between data points, and popular ones include Euclidean distance, Manhattan distance, and cosine similarity. KNN imputation is a technique for filling in missing values by utilizing information from similar instances.
These concepts have applications in various domains like healthcare, finance, and customer analytics. Understanding distance metrics and KNN imputation can enhance data preprocessing, feature selection, and model building.
In summary, distance metrics and KNN imputation are valuable tools for handling missing data and improving decision-making in data analysis.
We hope this blog post has provided you with valuable insights into distance metrics and KNN imputation.
Let's see it in the next blog. Stay tuned!!!
Thank you!!!
Subscribe to my newsletter
Read articles from Naveen Kumar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by