Demystifying Big Data Analytics with Apache Spark : Part-3
 Renjitha K
Renjitha K
When it comes to dealing with mountains of data, Apache Spark has emerged as a powerful tool for processing and analyzing large-scale datasets. But what makes Spark even more appealing to many data professionals is its integration with good old, Structured Query Language (SQL).
SQL, you ask? Yes, you heard it right! Apache Spark SQL brings the familiar world of SQL to the big data landscape, allowing us to leverage our SQL skills and experience to tackle complex data analysis tasks.
But what exactly is the role of SQL in Apache Spark, and why should we care?
Spark SQL Advantages
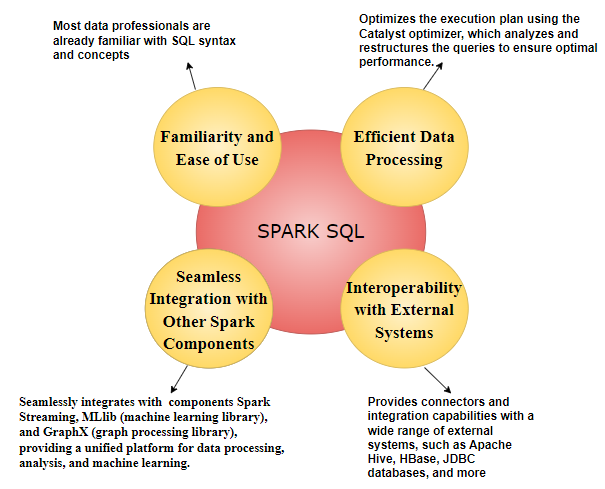
Architecture and Key Components
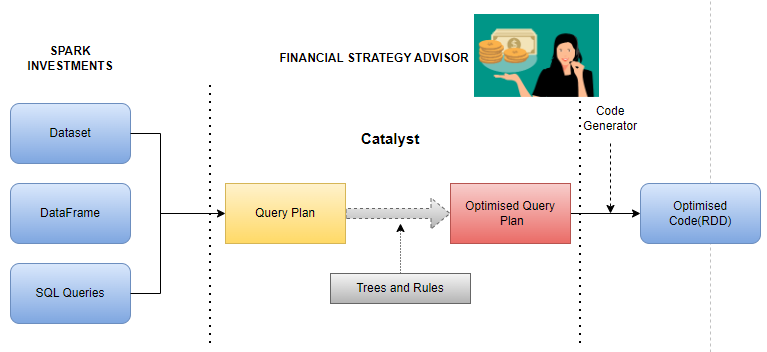
Let's imagine an investment bank called "Spark Investments", having valuable financial information waiting to be discovered and analyzed. Now, imagine that they have a financial strategy advisor named Spark SQL, who is a wizard and is going to help you make informed decisions. But how does Spark SQL work its magic? Let's delve into its architecture and understand the key components that make it such a powerful tool for data processing and analysis.
1. Catalyst Optimizer: Financial Strategy Advisor
At the heart of Spark SQL lies the Catalyst Optimizer, a magical wizard that takes your SQL queries and transforms them into an optimized execution plan. Catalyst combines query transformations, rule-based optimizations, and cost-based optimizations to create an efficient plan for data processing.
It optimizes your queries by performing tasks such as predicate pushdown, join reordering, and constant folding. It analyzes your query's structure, data statistics, and available resources to ensure the most efficient execution path. It ensures that Spark Investments analysts receive the most efficient execution plan, allowing them to make informed investment decisions swiftly.
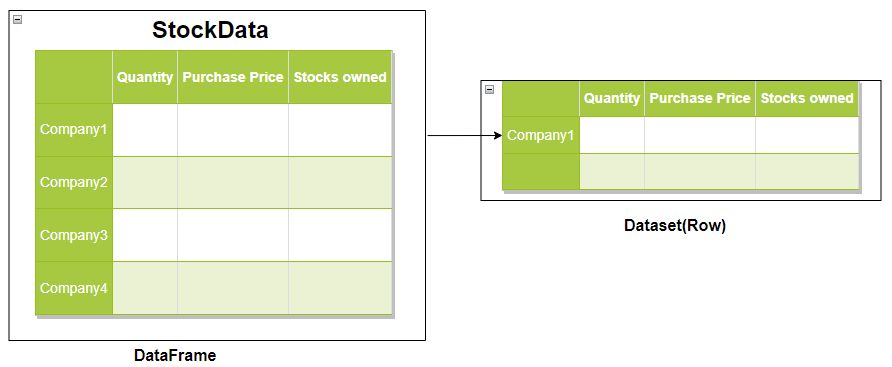
2. DataFrames and Datasets: Organized Financial Reports
Spark Investments utilizes DataFrames and Datasets to organize its financial reports, much like a meticulously maintained library of financial information. DataFrames act as tables, containing structured data like stock prices, market indices, and historical performance. Datasets, on the other hand, represent specific financial instruments or portfolios, enabling Spark Investments to work with strongly typed, object-oriented data representations.
3. Unified Processing Engine: Scalable Risk Analysis
By leveraging Spark's distributed computing capabilities, Spark Investments' risk analysis tasks can be performed in parallel, effectively reducing processing time. This means that complex computations and risk modeling can be executed efficiently, even when dealing with massive datasets.
With the aid of Spark's distributed cluster, risk analysts at Spark Investments can effortlessly run intricate SQL queries. This allows them to delve into historical trading data, simulate risk scenarios, and calculate essential risk metrics with exceptional speed. It's like having a team of experts collaborating simultaneously on various aspects of risk analysis, leading to swift and accurate decision-making processes.
4. External Data Sources: Enriching Market Insights
To gain a comprehensive view of the market, Spark Investments integrates external data sources seamlessly. They connect Spark SQL with external systems like stock exchanges, market data providers, and financial APIs. This allows them to access real-time market data, news feeds, and economic indicators, expanding their library of financial information.
Spark Investments can blend internal and external data seamlessly, creating a holistic view of the investment landscape.
Enough of the theory,
Creating Data Frames
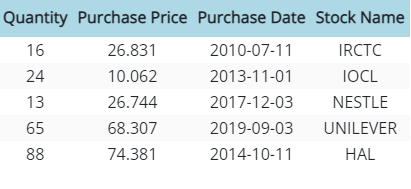
Now let's understand how to create DataFrames in Apache Spark, load data from various sources such as JSON and perform basic operations like filtering, selecting, and aggregating data. We will showcase the flexibility and ease of use that DataFrames offer, enabling analysts to handle large volumes of structured data with ease. Let's say we have the following data in JSON format
If you need to understand how to set up the workspace and get started with Apache Spark follow my previous blogs listed down*:*
https://renjithak.hashnode.dev/demystifying-big-data-analytics-with-apache-spark-part-1
https://renjithak.hashnode.dev/demystifying-big-data-analytics-with-apache-spark-part-2
Once you have a setup, Add spark-sql dependency into your build.gradle or pom.xml file
compileOnly group: 'org.apache.spark', name: 'spark-sql_2.13', version: '3.3.2'
Let us create a basic SparkSession, which is the entry point into all functionality in Spark, we can create DataFrames from an existing RDD, from a Hive table, or from spark data sources.
import static org.apache.spark.sql.functions.col;
//Create spark session
SparkSession spark = SparkSession
.builder()
.appName("Spark SQL")
.master("local[*]")
.getOrCreate();
//Read json data into dataset<rows>
Dataset<Row> df = spark.read()
.option("multiline","true")
.json("src/main/resources/StockPurchaseData.json");
// Displays the content of the DataFrame to console
df.show();
// Displays the content of Stock Name column to console
df.select("Stock Name").show();
log.info("No:of rows:{}",df.count());
// Select Quantity greater than 20
df.filter(col("Quantity").gt(20)).show();
spark.close();
Note: Spark also supports untyped transformations offering flexibility and ease of use by letting Spark handle the data types automatically.
The above code will give you similar results:

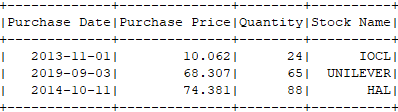
We can do a lot more interesting operations using Spark SQL, which I will be covering in the next part of this series, until then you can also refer to below official documentation.
Reference: https://spark.apache.org/docs/latest/sql-ref-functions.html#scalar-functions
Github Repo: https://github.com/renjitha-blog/apache-spark
See you in the next part, Happy learning :)
Subscribe to my newsletter
Read articles from Renjitha K directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Renjitha K
Renjitha K
Electronics engineer turned into Sofware Developer🤞On a mission to make Tech concepts easier to the world, Let's see how that works out 😋