How the Miro Developer Platform leverages contract testing
 Elena
ElenaDesign-first approach at Miro
The Miro Developer Platform 2.0 was launched last year, and since then we’ve been working on improving the quality and consistency of our REST API. To achieve this, we decided to embrace a design-first approach. For us, it meant designing the API before actually implementing it, and making sure that the quality was high during the whole development process.
This meant we needed an efficient way to verify compliance between the API and its description in OAS (OpenAPI Specification) files.
In this post, I’ll share why we landed on contract testing as the solution. Contract testing is a fast, lightweight form of API testing that ensures two separate services are compatible and can communicate with each other by checking the consistency with a set of rules.
Switching from code generation
Previously, we generated OAS files from the code, using annotations on controllers and models. At the time, this allowed us to transition from writing the documentation manually to some degree of automation. However, the solution was hacky and required us to jump through a lot of hoops to generate the OAS files.
@Operation(
summary = "Get specific connector",
description = "Retrieves information for a specific connector on a board.",
responses = [
ApiResponse(
responseCode = "200",
description = "Connector retrieved",
content = [
Content(schema = Schema(implementation = ConnectorWithLinks::class))
]
)
],
operationId = "get-connector"
)
fun getConnectorById() {...}
The early version of the API was not designed according to OpenAPI standards and had problems like conflicting endpoints and overly complex models. The main components of the design-first approach were quite difficult to implement, so we decided to switch the source of truth from the code-generated OAS files to permanent, curated ones.
How do we keep it in sync?
However, switching the source of truth presented a new problem. When the OAS files were generated from the code, we could at least partially guarantee that we were serving what we were promising. For example, the endpoint description could not have been generated if it didn’t exist in the code. Now, there was no way to tell if the OAS file had the paths and schemas that actually existed.
Looking for a solution
Of course, we have end-to-end tests. Why not reuse them to verify that the API looks as expected? They cover the functionality anyway, so why not add a little schema validation to the mix?
This idea is great, but it has the same flaw as the previous situation — it’s based on trust and leaves room for human error: New endpoint, but tests are not added? New parameter added, but tests are not updated because it’s out of critical path? The whole new experimental API appeared with no new tests and no intention to write them yet?
Writing a set of tests just to verify the compliance between the API and its description in OAS seemed even more far-fetched — not only did it have the same flaws, but it would also require us to do the same work all over again.
And this is how we arrived at the idea of generating tests from the OAS file.
How can a test be generated?
Our OAS has all the necessary data to successfully generate a request and validate the schema of the response. The request body can be built from schemas and the provided example/default values. If we don’t go into the details (and we don’t just yet), the logic for one resource is pretty easy:
First, find the endpoint that creates the resource (for example, the widget).
Save the id from the response.
Re-use it in all other endpoints (get widget by id, update widget).
Find the endpoint to delete it and execute it last.
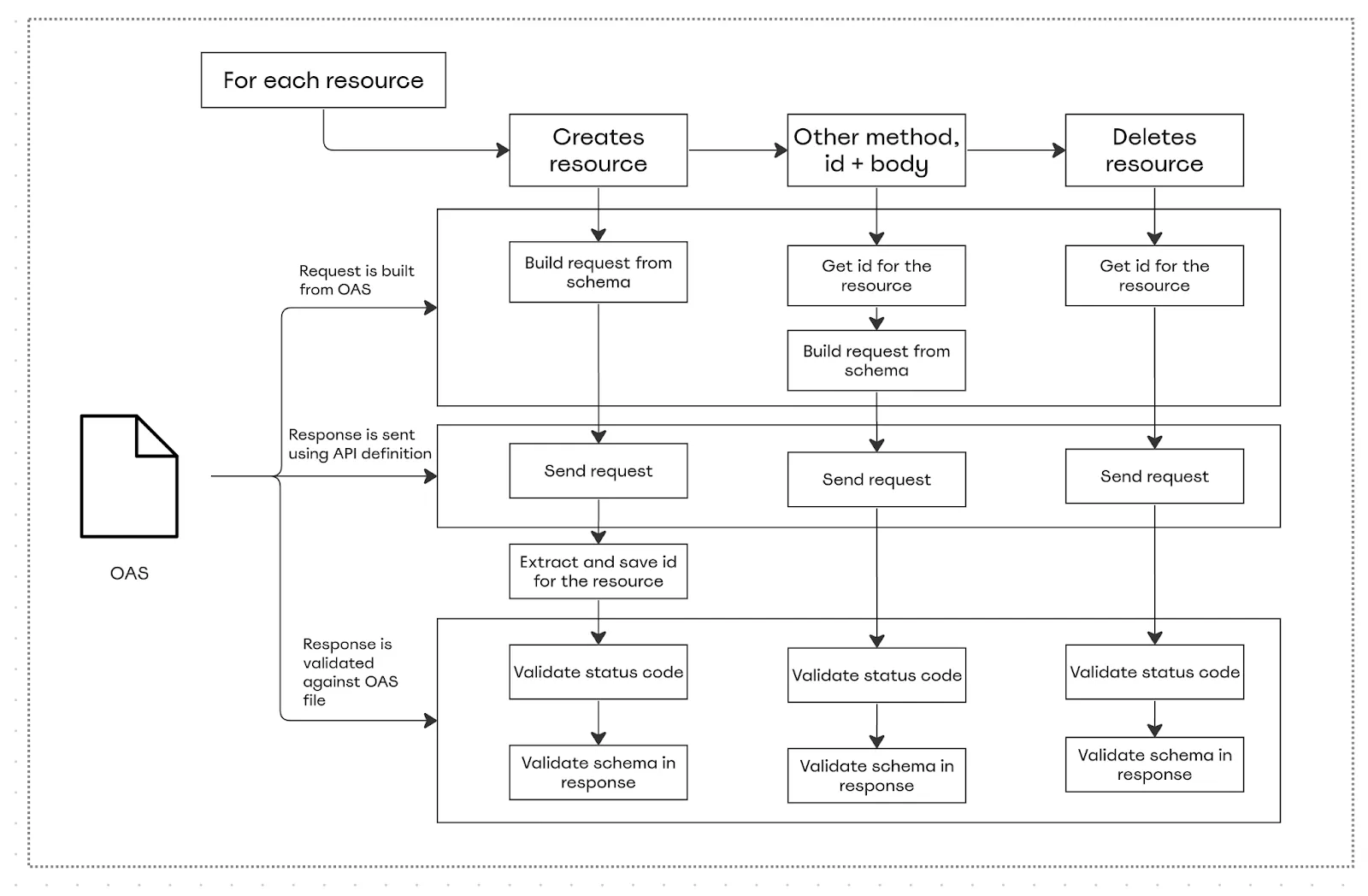
But the devil is in the details, and the most pressing questions would be: What if it’s more than one resource? How do we guarantee that, say, the widget is created before the board is deleted?
Level-method model
At this point we cared about two things: the method (POST should go first, DELETE — last) and the order of resource creation (boards before widgets). It may seem to have a simple solution.
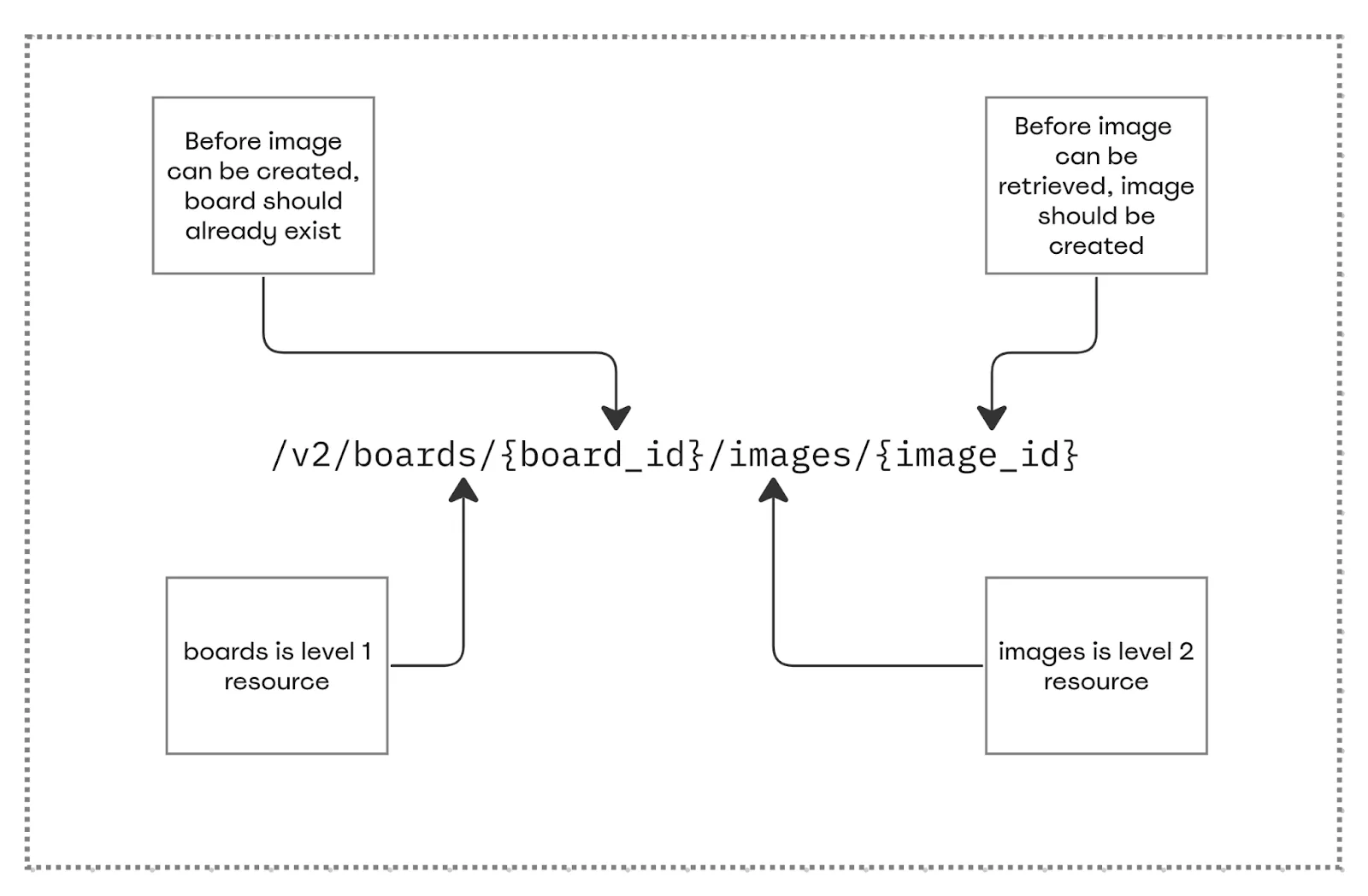
We can easily identify the endpoints that create/delete the resources by method; that’s the first point of comparison. When we look at the path, we see that some resources appear before others. By naming them resource 1 and resource 2 (3, 4 or however far the craziness can get us), we get the second point. Then we only have to sort in the form of an arrow:
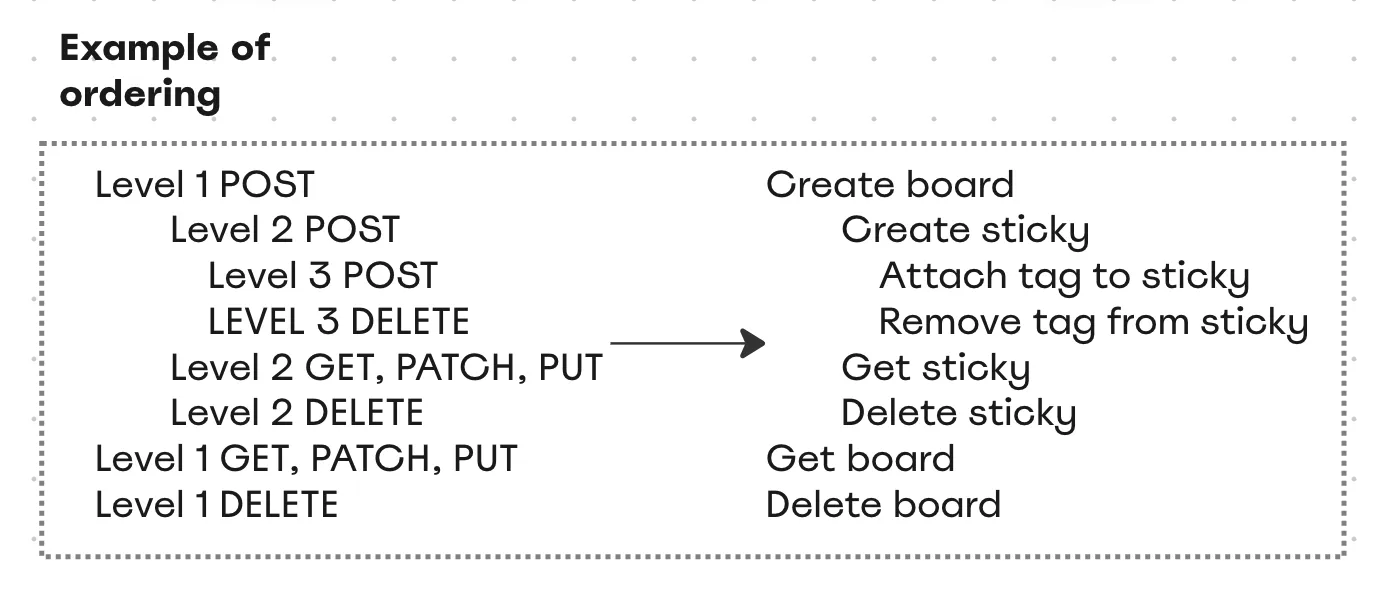
This idea was simple, easy to understand, and worked great as a proof of concept, but it introduced more problems than it solved, namely:
Representing the order in a simple manner possible with two levels of resources, worsens with three levels, and becomes not maintainable after it.
Not all POST endpoints create resources. For example, attaching a tag to the item is also a POST endpoint, but it has to happen after both items and tags are created.
Adding additional order — for example, if the endpoint has parent_item_id, it has to be created after a frame is created — seems impossible without blowing up the complexity.
We needed a more powerful way of sorting the relationships between endpoints, and that led us to a dependency graph.
Dependency graph
Who would have thought to represent dependencies with a graph, right? In any case, it seemed like a very plausible solution: A directed graph can handle relationships of any complexity. It’s very clear what should be executed first. And there’s no need to rely on strict pre-defined ordering.
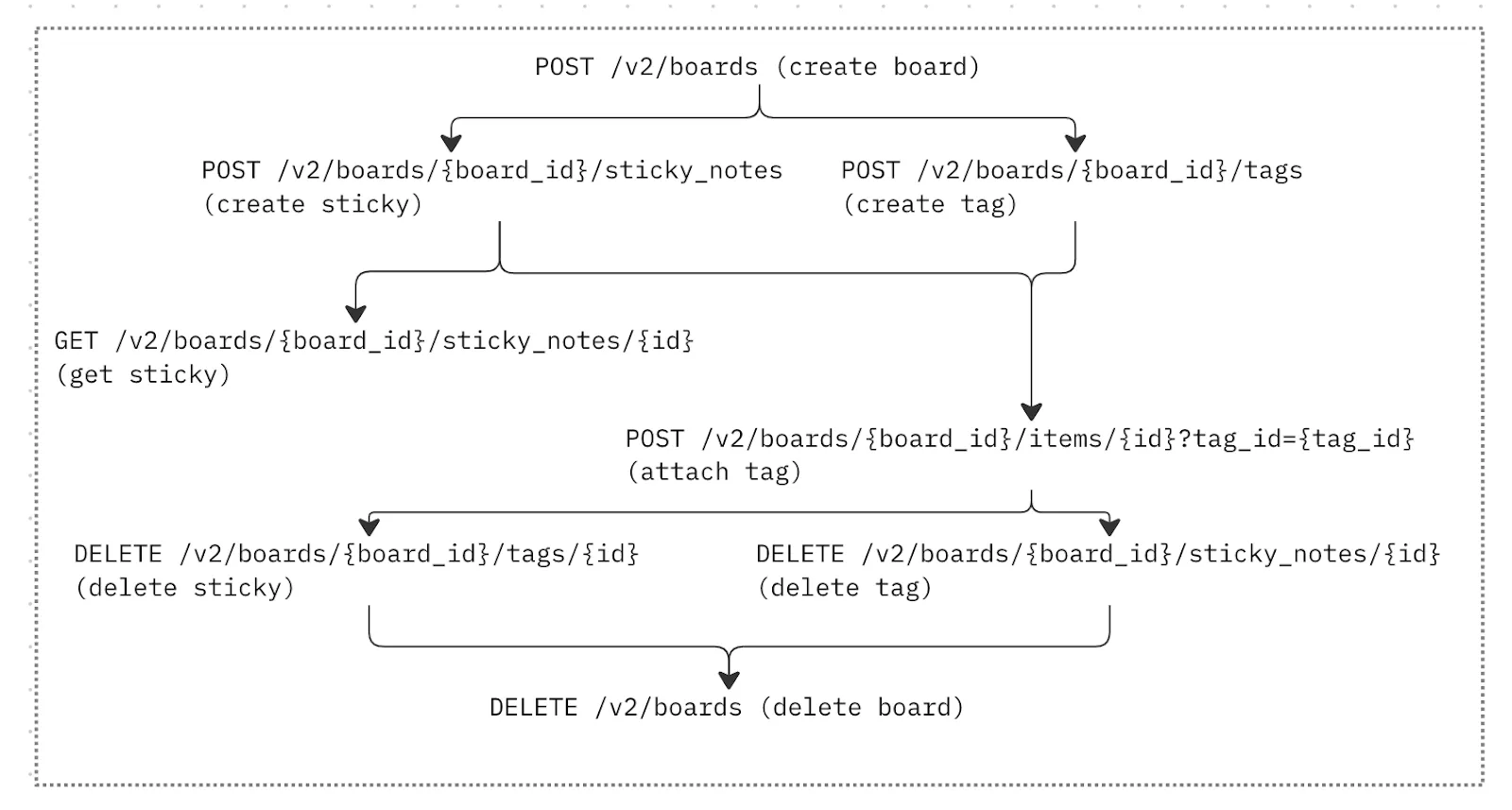
But how do we build a graph? Do we take the very first endpoint and put it in the graph, then take the next one and try to determine its relationship with the first node? That might work — and guarantee that the board is not deleted before we’re done with widgets on it. But at some point this approach would require traversing the entire graph to figure out the relationships with all other nodes. Despite the fact that we’ll never have that amount of endpoints for it to become a real performance problem, it does not help with the complexity, so we probably need another approach.
Luckily, the level-method ordering approach highlighted not just the problems, but also the way we can use components of the url to determine the relationships. So instead of trying to fit the endpoint into the graph, we’re going to build the graph around it based on what this particular endpoint needs.
Walkthrough
Let’s take a simple endpoint: add a tag to an item. By looking at the endpoint, we can see that before it can be executed, we need to have a board, an item, and a tag already created. We’re going to have a special kind of node — “creational” nodes — and will create a lot of “empty” nodes like this. They can be populated with an actual url template when we get to it, but the node needs to exist before, so it can be used as a dependency.
What are the steps to building a dependency graph for this endpoint?
Create a graph node for current operation.
If the node creates the resource, save it to the map of resources and their corresponding creation nodes.
For each required parameter or resource in the api path:
Find the node that knows how to create the required resource from the map above.
…or create an empty node that will be populated when the creation operation is parsed.
Add a dependency on it.
What if the endpoint deletes the resource entirely? Instead of adding extra complexity to the algorithm, we save them separately, in a “cleanup queue.”
Now we have a graph of all the endpoints, plus a cleanup queue with delete endpoints sorted by the level of the resource being deleted. To test all the endpoints as parameters in the test, we need to put them in a simple sorted list. The initial idea was to use a graph and modified topological search, but with the graph construction that we use, the sorting is simplified to a BFS plus polling the cleanup queue in the end.
As you may have noticed in the above example, an endpoint node can have a dependency on more than one other node, for example, both tags and items. And they, in return, can depend on multiple other nodes. The simple BFS will create duplicates at best, and unexpected ordering in the worst-case scenario. Plus, even duplicates can be detrimental: A second tag is created with the same example value provided in OAS, and this request ends with 400 because duplicated tags are not allowed.
The solution for this, however, would be simple: If some node meets a child with more than one parent, it ignores it and detaches itself from a child, leaving nodes that appear later to take care of. This is the cruel reality of child care in computer science.
Of course, there are still some limitations to what can possibly be automated. Here are some of them:
If the resource cannot be created via API (e.g. organizations for enterprise API), it has to be created before the test runs.
If the endpoint has a parameter (e.g. tag_id or parent_item_id or parent_id), you need to map it to some resource first (e.g. tag_id to tags).
Likewise, if another resource is mentioned in the request body, it has to be created (e.g. widgets for connectors) or mapped to an existing resource.
Customizations
The whole solution consists of 4 parts:
The OAS files describing the Miro API
Test generation logic
Creation of the components that can be generated automatically
The tests themselves
Plugins
The test generation logic is a separate library that only needs to change when a new feature is required for all test suites, for example, when we decide to also make requests with missing required parameters to test error responses. All custom modifications, including providing new OAS files, have to go through plugins.
Plugins offer a set of customizations to the owner of the API. For example, mapping resources to parameters, or retrying logic for some endpoints.
Other types of tests
The initial set of tests contained only positive tests that check that a successful response is returned and the response schema is exactly as it is described in the OAS file. However, there are a number of possibilities to create other types of tests, from the already mentioned missing required parameter checks, to testing the expected error responses.
Automation
The tool is as good as its automation, so the API testing tool is scheduled to run frequently and to notify the team about the results. This solution also unlocked not just publishing the documentation automatically right after the change, but also preparing OAS files, for example, removing endpoints marked as drafts.
There you have it. With OAS contract testing, we can verify compliance between the API and its description in OAS files.
Do you have ideas or a different approach to API testing? Let us know in the comments — we’re interested in what you have to say!
Are you interested in joining our team? Then check out our open positions.
Finally, don’t forget to try the Miro Developer Platform for yourself.
Subscribe to my newsletter
Read articles from Elena directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by