Airbnb Clone: The Base Model. Part 3 (Data Persistence)
 Chiagoziem El-Gibbor
Chiagoziem El-Gibbor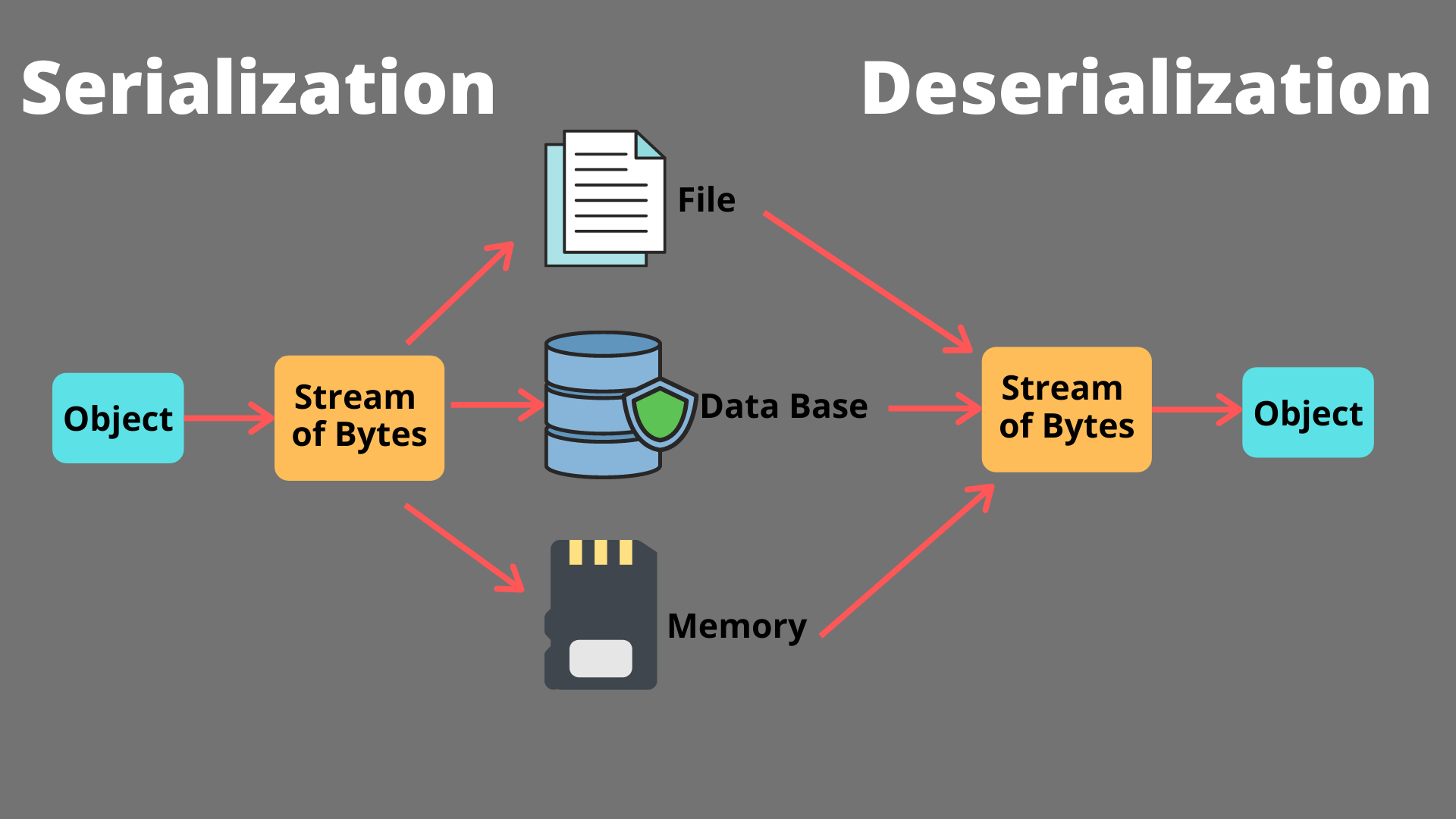
Welcome to the third episode of this series. If this is your first time visiting this blog, I highly recommend you consider reviewing Part 1 and Part 2 of this series before delving into this article for a better understanding of the project and what we've accomplished thus far, because this current article is built on the precedent ones.
Without further ado, let's talk a little about data persistence.
In the previous article, we implemented a simple piece of data serialization and deserialization that has this flow: <class 'MyBase'> -> save_to_dict() -> <class 'dict'> -> <class 'MyBase'>. An instance of MyBase is first converted to a dictionary representation using the save_to_dict() method, which serializes our instance to a dictionary object type. and we can create a new instance of MyBase from this dictionary representation by passing it as keyword arguments to the __init__() method of MyBase which creates a new MyBase object with the same attributes and values as the original object that was serialized.
But anytime we close or end our program, these data are lost; they are not restored when we relaunch the program. This highlights the limitation of this approach in that the data is not persistent.
The word "persistence" means "the continuance of an effect after its cause is removed." Then, the term "data persistence" means "it continues to exist even after the application or program has ended."
The very first thing you might think of is writing or saving this dictionary representation to a file, but that might not be relevant or solve our problem either because data written directly into a file in Python is stored as a string, and Python doesn't know how to "easily" convert a string to a dictionary. then Incompatibility: using this file with another program in Python or across other languages and platforms will be hard.
To solve this, we will convert the dictionary representation to a JSON string before saving it to a file. JSON is a standard data interchange format that provides a standard representation of a data structure that is both human-readable and easily convertible to other programming languages and platforms. This format is completely human-readable, and all programming languages have a JSON reader and writer. After this implementation, the flow of our serialization-deserialization will now be in this format: <class 'MyBase'> -> save_to_dict() -> <class 'dict'> -> JSON dump -> <class 'str'> -> FILE -> <class 'str'> -> JSON load -> <class 'dict'> -> <class 'MyBase'>. First, when an instance of MyBase is created, it will be passed into save_to_dict() method that converts this instance or object to a Python dictionary representation. The dictionary representation will then be passed into the Python JSON module, which uses the Json.dump() function to convert the dictionary representation to a JSON string, which is subsequently written into a file. We then use json.load() function from the same Python JSON module to read this JSON string from the file and convert it back to a Python dictionary. Finally, we can now pass the dictionary representation into our class constructor to regenerate a new instance of MyBase with the same attributes and values as the original object that was serialized.
I just hope and believe that I've successfully broken down this flow and process of achieving persistent data storage.
Now we will be writing the class that will handle this implementation (serialization of instances to a JSON string, into a JSON file, and from the JSON file back to an instance of a class).
Please I won't be treating the arrangement of files or modules (package model structure) in this article. For this reason, you should be well informed on how to arrange your files and make them a package according to the project requirements so that you can easily import and use them in a different module. I'm only focused on breaking down the flow and logic implemented to achieve a console interface for our Airbnb web application.
Let's write a class, FileStorage with two private class attributes.
The first attribute is __filePath: a string that holds the path to the JSON file (ex: file.json), __objects : empty dictionary that will store all objects by <class name>.id e.g: to store an instance of MyBase with an id=22443344, the key will be MyBase.22443344 followed by the instance attributes, which are key-value pairs too. In totality, what will be stored in the dictionary __objects will be a double or nested dictionary where the key is the class name indexed by its ID and the value is a dictionary (key-value pair) containing all attributes of the class instance. (ex: to store an instance of MyBase, it will be something like this: {'MyBase.224423344': {'id': 22443344, 'name': 'myModel', '__class__': 'MyBase'}} you can see that we have a dictionary where the key is the class name dot the instance ID, and the value is a dictionary containing the class instance attributes.
Let's define the class with the required private class attributes.
class FileStorage:
__filePath = "file.json"
__objects = {}
The class attributes we just declared above are prefixed with double underscores, which denotes they are private class attributes, and this brings us to one of the important principles of object-oriented programming, encapsulation. Here we are trying to encapsulate the implementation details of the FileStorage class and prevent other parts of the program from accessing or modifying these attributes directly. Encapsulating this implementation provides us with lots of benefits, but I will talk about just two of them: security and consistency.
Security: By making the
__file_pathattribute private, we are preventing external code from accessing or modifying the path of the file where our data is stored. This helps to ensure that the data is stored in a secure location and is not susceptible to attacks that might occur if the file path were public or accessible (can be modified from an external module or code).Consistency: By making the
__objectsattribute private, we are ensuring that all objects are stored in a consistent manner within the dictionary, which is indexed by the object's class name and itsID. This makes it easier to retrieve objects later on and ensures that the data is stored in a predictable manner that is not dependent on the specific implementation of theFileStorageclass.
For example, suppose that an external module directly modifies the __filePath attribute of the FileStorage class to point to a different file without going through the proper methods of the class. This could cause unexpected behaviour in the rest of the code that relies on the original file path and could result in data loss or corruption.
Similarly, if the __objects attribute was not private, external code could modify it directly without going through the proper methods of the class. This could lead to an inconsistent state where the __objects dictionary contains invalid data or is missing some objects that were not properly added to it.
I believe I've made some sense about encapsulation as regards our implementation. Let's move on to writing a method all(self) that returns the dictionary __objects where all our objects are stored. and also another method new(self, obj) that sets in __objects the obj with key <obj class name>.id just like I explained before. The contents of __objects will be in this format: {'MyBase.224423344': {'id': 22443344, 'name': 'myModel', '__class__': 'MyBase'}}. the key is <obj class name>.id which is 'MyBase.224423344', then obj is the value, which is 'id': 22443344, 'name': 'myModel', '__class__': 'MyBase' an instance of Mybase.
def all(self):
# returns the dictionary __objects
return FileStorage__objects
def new(self, obj):
# set the key-value pair in __objects (class.id as key, obj as the value)
FileStorage.__objects[f"{obj.__class__.__name__}.{obj.id}"] = obj
Another more clear and basic way to do this is to first set the key format in a variable, then use that variable as the dictionary key, and then assign or pair the value obj to this key.
def new(self, obj):
keyFormat = f"{obj.__class__.__name__}.{obj.id}"
FileStorage.__objects[keyFormat] = obj
Now it's time for serialization. We will be writing a method save(self) that serializes the data in __objects to our JSON file (path: __filePath)
from json import dump
def save(self):
# declaree an empty dictionary to hold the object we are serializing
dictObj = {}
# loop and grab the objects (key-value pair) we stored in __objects
for key, val in FileStorage.__objects.items():
# convert the values to a dictionary using our save_to_dict() method
dictObj[key] = val.save_to_dict()
# open the file path for writing (serialization)
with open(FileStorage.__filePath, "w", encoding="utf-8") as jsonF:
# dump the serialized object into the file
dump(dictObj, jsonF)
At the beginning of this article, I explained the flow of our serialization and deserialization. You may want to go back and read it again to understand the code I just wrote. I accessed the dictionary __objects where our objects are stored with the class name FileStorage because it is a class attribute. I then retrieved its contents (key-value pair) with a loop. Remember how we stored the key in this dictionary? <class name>.id. So what we need here is just the value, which is the object or class instance ( a dictionary containing the instance attributes). ex: {'id': 22443344, 'name': 'myModel', '__class__': 'MyBase'}, We then convert this object to a Python dictionary representation using the save_to_dict() method we wrote earlier. And finally, the file path to where we will dump the JSON string representation of our objects is opened in write mode, and the objects are serialized to a JSON string and dumped into it using a dump() function from json.dump Module.
Our implementation is incomplete without a method to deserialize this JSON string representation back to a Python object (instance of our class). So let's write a method reload(self) that deserializes the data in our JSON file back to the dictionary __objects (only if the JSON file (__file_path)) exists; otherwise, do nothing). If the file doesn’t exist, no exception should be raised.
from json import load
def reload(self):
# Be sure you import all your defined classes into this local namespace
# as you progress and write other classes used in this programme. ex:
from MyPackage.MyFileName import MyBase
# dictionary to hold all our defined classes (user-defined)
definedClasses = {'MyBase': MyBase}
# Attempt to open the Json file in the filePath
try:
with open(FileStorage.__filePath, encoding-"utf-8") as jsonStr:
# deserialize the JSON string in the file at the file path
deserialized = load(jsonStr)
# Iterate over each obj's value in the deserialized dictionary
for obj_values in deserialized.values():
# get obj's class name from the '__class__' key
clsName = obj_values["__class__"]
# get the actual class object in the definedClasses dictionary
cls_obj = definedClasses[clsName]
# Create a new class instance with the object's values as
# its arguments
self.new(cls_obj(**obj_values))
# Catch FileNotFoundError and ignore if theres no file to deserialize
except FileNOtFoundError:
pass
The reload method we just wrote above attempts to deserialize an object from a JSON file and create an instance of the corresponding class using the deserialized data.
Before attempting to deserialize the JSON file, we declared a dictionary definedClasses to hold all user-defined classes that will be used to recreate class instances (objects). Remember to keep updating this dictionary definedClasses with any class you define or write in the future so that its actual class can also be retrieved from the value paired to the keys in this dictionary (a name string of the class that corresponds with the actual defined class), which will be used for regenerating a new instance of that class.
Inside the try block, we used the load function from json module to deserialize the JSON string in the file at the specified file path. Then we iterate over each object's values in the deserialized dictionary (remember, the data in the file is a nested dictionary where the key is the <classname.id>, and the value is another dictionary containing the class instance attributes). Inside this object value, which is a key-value pair, we have a '__class__' key with the object's class name as its value, so we extract the object's class name which is MyBase in our case, and assign it to the variable clsName which is afterwards used to get the actual class that corresponds with this name from the dictionary definedClassses. So after the assignment cls_obj = definedClasses[clsName], cls_obj now holds the actual defined class MyBase. We then pass in the object's values as arguments into the class constructor. So this assignment self.new(cls_obj(**obj_values)) evaluates to self.new(Mybase(**obj_values)). Rember how we implemented MyBase class __init__() method to receive and set arguments when Kwargs is not empty, So now we are passing in a dictionary to the __init__() method of MyBase class which will unpack this dictionary and set it according to the implementation of MyBase class when kwargs is not empty. You may want to check it again and understand how this argument will be unpacked and used to regenerate a new class instance or object. Finally, our we use the new() method to return a class instance in its own format, with the class name dot ID as the key followed by the instance attributes as its value.
But if the attempt to access this file fails, which means that the file is not found or doesn't exist, then the method ignores the FileNotFoundError exception and passes silently.
Another tempting way to achieve this is by using eval() function, but due to the security risks, vulnerabilities, and how dangerous it is to use this function, it is advised to totally abstain from using it if possible. But if you used it in your implementation, you can write a verifier to validate what eval() takes in as input from an implementation like the one below:
from json import load
def reload(self):
try:
with open(FileStorage.__filePath, encoding-"utf-8") as jsonStr:
deserialized = load(jsonStr)
for obj_values in deserialized.values():
clsName = obj_values["__class__"]
# eval() evaluates the string in cls_name('MyBase') and
# return the corresponding defined class
self.new(eval(clsName)(**obj_values))
except FileNOtFoundError:
pass
From this code, eval() evaluates the string (our object class name) in the variable clsName as a Python expression and returns the actual class. The insecurity here is that if malicious code somehow successfully finds its way to that place as the argument, eval() will evaluate the string as a Python expression and can execute this code arbitrarily, resulting in some undefined or unwanted behaviour (behaviours that can crash the program or potentially cause security vulnerabilities).
One way to stop this is by verifying that the string or input to eval() function is validated and conforms to only what it is intended for. In our case, we are expecting a str which will be evaluated and returned in the actual corresponding defined class. Below is a line of code that ensures the input it is receiving conforms to what it is intended for:
if isinstance(clsName, str) and type(eval(clsName) == type:
First, we check if the input is a str, then we check if the str value evaluates to a class type type when evaluated by eval() function which indicates that it is a real defined class. Because every class in Python, whether built-in or user-defined, is an instance of the type metaclass. This means that a class is an object that is created from a template (the class definition) and is itself an instance of a class (the type metaclass).
Below is the updated version of the relaod() method using eval() with the input validation for eval() implemented.
from json import load
def reload(self):
try:
with open(FileStorage.__filePath, encoding-"utf-8") as jsonStr:
deserialized = load(jsonStr)
for obj_values in deserialized.values():
clsName = obj_values["__class__"]
# Verify and validate the input to eval()
if isinstance(clsName, str) and type(eval(clsName) == type:
# evaluate and process the inputs if this condition is met
self.new(eval(clsName)(**obj_values))
except FileNOtFoundError:
pass
With all that has been done, it's time for us to link this FileStorage to the entire codebase so that the program can save and restore instances of objects between program executions, providing a form of persistence for the program's data.
First, we will create a unique FileStorage instance for our application by using the variable storage. This should be done in the __init__.py file inside your parent package, and make sure you are importing correctly according to the hierarchy of the program packages to avoid running into import troubles.
After creating an instance of FileStorage with the variable storage, we then call the reload() method on this variable to deserialize the contents of the JSON file (if it exists) into a dictionary of objects, which is stored in the __objects attribute of the FileStorage instance. This ensures that all instances of objects created during previous program executions are restored to memory.
# your import statement might look somewhat like this but depends on your file arrangement and heirachy. ex:
from parentPackage.subPackage.fileStorageModule import FileStorage
# create an instance of Filestorage with the variable 'storage'
storage = FileStorage()
# call the reload() method on this instance
storage.reload()
Next is to update and link our base class MyBase to FileStorage by using the variable storage to enable instance serialization and deserialization.
First, we import the variable storage, then in the method save_update(self), we call the save(self) method of storage which ensures that every time a MyBase instance is saved, it is also saved to the JSON file through FileStorage and will be available for serialization. We also modify the __init__(self, *args, **kwargs) method of MyBase class and call the new(self) method on storage if it's a new instance (not from a dictionary representation). This will ensure that every time a new instance of MyBase is created, it is added to the dictionary of objects in FileStorage.
from datetime import datetime
from uuid import uuid4
class MyBase:
def __init__(self):
self.id = str(uuid4())
self.created_at = datetime.now()
self.updated_at = datetime.now()
def save_update(self):
# make sure to import the variable storage
from yourPackage import storage
updated_at = datetime.now()
# call save(self) method of storage to save al instance of MyBase
# to the JSON file
storage.save()
let's also update the __init__(self, *args, **kwargs)
class MyBase:
def __init__(self, *args, **kwargs):
if kwargs:
del kwargs["__class__"]
for key, val in kwargs.items():
if key == "created_at" or key == "updated_at":
dtime = datetime.strptime(val, "%Y-%m-%dT%H:%M:%S.%f")
setattr(self, key, dtime)
else:
setattr(self, key, val)
else:
self.id = str(uuid4())
self.created_at = datetime.now()
self.updated_at = datetime.now()
# add a call to the method new(self) on storage for new objs
storage.new(self)
Conclusion
We have successfully achieved persistent data interchange for our program by implementing data serialization and deserialization using JSON. With this implementation, we can now save our program data to a file and load it back even after the program has ended.
In the next episode, we will focus on writing and implementing the necessary commands to interact with our program objects using the console.
Thank you for following along with this series. If you have any feedback, questions, or suggestions, please feel free to reach out to me or connect with me via LinkedIn or Twitter. I am also open to collaboration, peer learning, or any other opportunities you believe would be a good fit for my growth.
Don't forget to follow this blog to stay updated on the next part of this series and also for more valuable tech-related articles.
Subscribe to my newsletter
Read articles from Chiagoziem El-Gibbor directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by