Semantic Web : Documentation
 Ronit Banerjee
Ronit Banerjee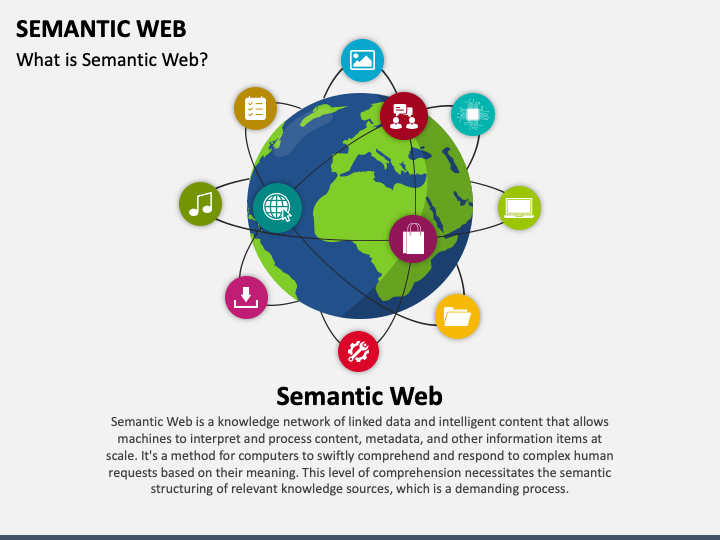
Before entering the multiverse of the Semantic web, these things should be known :
The Semantic Web is an extension of the current web that aims to make the information on the Internet more understandable and usable by machines. It's often described as a web of data that can be processed directly and indirectly by machines.
Here's a simple analogy: Imagine the internet as a very large book. Right now, humans can read and understand this book, but computers can't. They can display the pages (websites) of the book, but they don't understand what the words (data) mean. The Semantic Web is like adding a layer to the book that allows computers to understand the words and their meanings.
The Semantic Web works by using standards and technologies that add metadata and semantic content to web resources. This metadata describes the content, context, and relationships of data, which helps machines to understand the meaning of the information.
Here are some key technologies used in the Semantic Web:
1. RDF (Resource Description Framework): RDF is a standard model for data interchange on the web. It allows us to make statements about web resources in the form of subject-predicate-object expressions, known as triples. For example, "John (subject) hasAge (predicate) 25 (object)".
2. OWL (Web Ontology Language): OWL is used to define and link web-based ontologies. An ontology is a way of showing the relationships between different data, like "A Cat is a type of Animal".
3. SPARQL (SPARQL Protocol and RDF Query Language): SPARQL is a query language for RDF. It's used to retrieve and manipulate data stored in RDF format.
4. XML (eXtensible Markup Language): XML is a markup language that defines a set of rules for encoding documents in a format that is both human-readable and machine-readable.
The ultimate goal of the Semantic Web is to enable computers to do more useful work and to develop systems that can better understand and interact with both human users and other systems.
All the links of the other related documentations will be here for reference.
Understanding the Web and Semantic Web
What is the Web? How does it work?
The World Wide Web, often simply referred to as the "web," is a system of interconnected documents and resources, linked by hyperlinks and URLs. It was created in 1989 by British computer scientist Tim Berners-Lee and is now used by billions of people to access information, communicate, conduct business, and more. The web works through a system of servers (which host websites and content) and clients (like your web browser) which request and display this content. The communication between servers and clients is facilitated by the HTTP protocol. This [source](https://developer.mozilla.org/en-US/docs/Learn/Getting_started_with_the_web/How_the_Web_works) from Mozilla provides a comprehensive explanation of how the web works.
What is the Semantic Web?
The Semantic Web, on the other hand, is an extension of the web where information is given well-defined meaning, enabling computers and people to work in better cooperation. It's a vision of information that's understandable by computers, enabling them to do more of the tedious work involving information searching, combining, and processing. It involves technologies and standards that enable machines to understand the semantics, or meaning, of information on the web. This [source](https://www.w3.org/DesignIssues/Semantic.html) from W3C provides a roadmap for the Semantic Web.
How does it differ from the traditional Web?
The main difference between the traditional web and the Semantic Web comes down to the level of data interpretation. In the traditional web, data can be easily interpreted by humans but not by machines. The Semantic Web aims to make this data machine-readable, creating a more efficient and powerful web ecosystem.
Here are some key points from the Semantic Web roadmap:
- The Semantic Web is designed to be a web of data, somewhat like a global database.
- It aims to develop languages for expressing information in a machine-processable form.
- The Semantic Web is based on a common model of great generality, the Resource Description Framework (RDF).
- The RDF model contains just the concept of an assertion, and the concept of quotation - making assertions about assertions.
- The Semantic Web also introduces the concept of a schema layer to declare the existence of new properties and constrain the way they are used.
- The Semantic Web also includes a logical layer, which introduces the concept of predicate logic and quantification.
- The Semantic Web is expected to have a significant impact on search engines, which will be able to index RDF objects instead of just words, making the web searchable as if it were a giant database.
This is a high-level overview, and there's a lot more to both the web and the Semantic Web than can be covered in a single response. I recommend reading the provided sources for a more in-depth understanding.
History and Motivation for the Semantic Web
Who proposed the Semantic Web and why?
The Semantic Web was proposed by Tim Berners-Lee, the same person who invented the World Wide Web. He first outlined his vision for the Semantic Web in a document titled "Semantic Web Roadmap" in September 1998. This document was an attempt to provide a high-level plan for the architecture of the Semantic Web, which he described as a consistent logical web of data [source](https://www.w3.org/DesignIssues/Semantic.html).
The motivation behind the Semantic Web was to make the Web not only useful for human-human communication but also for machines. Berners-Lee observed that most information on the Web was designed for human consumption, and even if it was derived from a database with well-defined meanings, the structure of the data was not evident to a robot browsing the web. The Semantic Web approach aimed to develop languages for expressing information in a machine-processable form.
What problems does the Semantic Web aim to solve?
The Semantic Web was designed to solve several problems associated with the traditional Web. One of the main issues was the difficulty machines had in understanding and processing the information available on the Web. The Semantic Web aimed to make this information more accessible and understandable to machines, thereby enabling more efficient data integration, data sharing, and the use of machine learning algorithms on web data.
The Semantic Web also aimed to solve the problem of data interoperability. On the traditional Web, data is often locked into individual applications, making it difficult to share or combine with other data. The Semantic Web, with its emphasis on data linking and standard data formats, aimed to make data more interoperable, allowing it to be shared and reused across different applications.
Another problem the Semantic Web aimed to address was the difficulty of searching for specific information on the Web. The Semantic Web, with its emphasis on data linking and machine-readable data, aimed to make it easier to find specific information by enabling more precise and efficient search capabilities.
In summary, the Semantic Web was proposed to make the Web more understandable and usable by machines, to improve data interoperability, and to enhance search capabilities.
Components of the Semantic Web
What are the key technologies and standards used in the Semantic Web, such as RDF, OWL, and SPARQL?

The Semantic Web is a vision of the World Wide Web Consortium (W3C) to make the web a place where data can be shared and processed by automated tools as well as by people. It is often described as a "Web of Data" and is built on several key technologies and standards:
1. RDF (Resource Description Framework): RDF is a standard model for data interchange on the Web. It has features that facilitate data merging even if the underlying schemas differ, and it specifically supports the evolution of schemas over time without requiring all the data consumers to be changed. RDF extends the linking structure of the Web to use URIs to name the relationship between things as well as the two ends of the link (this is usually referred to as a “triple”). This linking structure forms a directed, labeled graph, where the edges represent the named link between two resources, represented by the graph nodes. This flexible model allows structured and semi-structured data to be mixed, exposed, and shared across different applications.
2. OWL (Web Ontology Language): OWL is a Semantic Web language designed to represent rich and complex knowledge about things, groups of things, and relations between things. OWL is a computational logic-based language such that knowledge expressed in OWL can be exploited by computer programs, e.g., to verify the consistency of that knowledge or to make implicit knowledge explicit. OWL documents, known as ontologies, can be published in the World Wide Web and may refer to or be referred from other OWL ontologies.
3. SPARQL (SPARQL Protocol and RDF Query Language): SPARQL is an RDF query language, that is, a semantic query language for databases, able to retrieve and manipulate data stored in Resource Description Framework (RDF) format. SPARQL allows for a query to consist of triple patterns, conjunctions, disjunctions, and optional patterns.
4. SKOS (Simple Knowledge Organization System): SKOS is a common data model for sharing and linking knowledge organization systems via the Web. Many knowledge organization systems, such as thesauri, taxonomies, classification schemes and subject heading systems, share a similar structure, and are used in similar applications. SKOS captures much of this similarity and makes it explicit, to enable data and technology sharing across diverse applications.
These technologies are used to create data stores on the Web, build vocabularies, and write rules for handling data. Linked data are empowered by these technologies, enriching data with additional meaning, which allows more people (and more machines) to do more with the data.
For more detailed information, you can refer to the [W3C Semantic Web](https://www.w3.org/standards/semanticweb/) page.
Principles of the Semantic Web
What are the underlying principles of the Semantic Web, such as the use of URIs for identification and the linking of data?
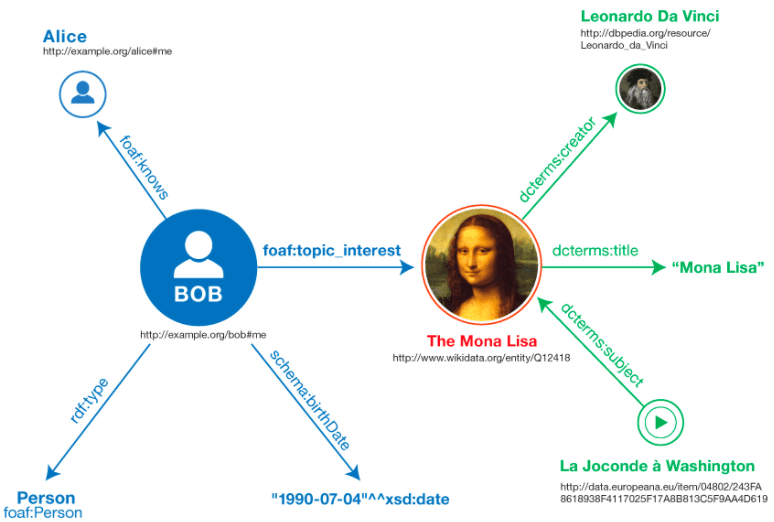
The Semantic Web, as described by the World Wide Web Consortium (W3C), is a vision of a "Web of data" that extends beyond the traditional "Web of documents." This concept is built on several key principles:
1. Linked Data: The Semantic Web is essentially a web of data that includes dates, titles, part numbers, chemical properties, and any other conceivable data. The Resource Description Framework (RDF) forms the basis for publishing and linking this data. Various technologies, such as RDFa and GRDDL, allow data to be embedded in documents, while others enable the exposure of SQL databases or the provision of RDF files.
2. Vocabularies: Sometimes, it's important or valuable to organize data. Using the Web Ontology Language (OWL) to build vocabularies (or "ontologies") and the Simple Knowledge Organization System (SKOS) for designing knowledge organization systems, data can be enriched with additional meaning. This allows more people (and more machines) to do more with the data.
3. Query: Query languages are essential for databases. If the Semantic Web is seen as a global database, then a query language for that data is necessary. SPARQL serves as the query language for the Semantic Web.
4. Inference: Near the top of the Semantic Web stack, you find inference, which involves reasoning over data through rules. W3C's work on rules, primarily through the Rule Interchange Format (RIF) and OWL, focuses on translating between rule languages and exchanging rules among different systems.
5. Vertical Applications: W3C is collaborating with different industries, such as Health Care and Life Sciences, eGovernment, and Energy, to enhance collaboration, research and development, and innovation adoption through Semantic Web technology. For example, Semantic Web technologies can aid decision-making in clinical research by bridging various forms of biological and medical information across institutions.
These principles, when combined, enable the Semantic Web to support trusted interactions over the network and allow computers to do more useful work. The Semantic Web technologies empower people to create data stores on the Web, build vocabularies, and write rules for handling data.
Source: [Semantic Web - W3C](https://www.w3.org/standards/semanticweb/)
Semantic Web vs. Linked Data
What is Linked Data and how does it relate to the Semantic Web?
Linked Data
Linked Data is a method of structuring and interconnecting data on the web. It's not just about putting data on the web, but about making links so that a person or machine can explore the web of data. With linked data, when you have some of it, you can find other, related, data. This concept was described by Tim Berners-Lee, the inventor of the World Wide Web, in his article on [Linked Data - Design Issues](https://www.w3.org/DesignIssues/LinkedData.html).
The key principles of Linked Data, as outlined by Berners-Lee, are:
1. Use URIs as names for things.
2. Use HTTP URIs so that people can look up those names.
3. When someone looks up a URI, provide useful information, using the standards (RDF*, SPARQL).
4. Include links to other URIs, so that they can discover more things.
These principles are designed to make data interconnected, which in turn increases the ways it can be reused in unexpected ways. It is this unexpected re-use of information that adds value to the web.
Linked Data and Semantic Web
The Semantic Web is a vision of a web of data that can be processed directly and indirectly by machines. It's about having data on the web defined and linked in a way that it can be used for more effective discovery, automation, integration, and reuse across various applications.
Linked Data is a key component of the Semantic Web. It provides a method of structuring data that allows it to be interlinked and become more useful through semantic queries. It enables data from different sources to be connected and queried.
In essence, Linked Data is a way of realizing the Semantic Web vision. By applying the principles of Linked Data, we can create a web of interconnected data - the Semantic Web.
Linked Open Data
Linked Open Data (LOD) is Linked Data which is released under an open license, which does not impede its reuse for free. Berners-Lee also proposed a 5-star rating system for Linked Open Data, where you get more stars as you make your data progressively more powerful and easier for people to use.
1. ★ Available on the web (whatever format) but with an open license, to be Open Data
2. ★★ Available as machine-readable structured data (e.g., excel instead of image scan of a table)
3. ★★★ As (2) plus non-proprietary format (e.g., CSV instead of excel)
4. ★★★★ All the above plus, Use open standards from W3C (RDF and SPARQL) to identify things, so that people can point at your stuff
5. ★★★★★ All the above, plus: Link your data to other people’s data to provide context
This system encourages people, especially government data owners, to provide good linked data.
In conclusion, Linked Data is essential to connect the Semantic Web. It is quite easy to do with a little thought, and becomes second nature. Various common sense considerations determine when to make a link and when not to.
Benefits and Challenges of the Semantic Web
What are the potential benefits of the Semantic Web for different fields, such as science, business, and government?
The Semantic Web offers numerous benefits across various fields such as science, business, and government. Here are some examples:
1. Science: The Semantic Web can enhance scientific research by enabling more efficient data integration and discovery. It allows scientists to link and cross-reference data from different studies, facilitating more comprehensive and nuanced analyses.
2. Business: Businesses can benefit from the Semantic Web through improved data management and decision-making. For instance, Biogen Idec, a pharmaceutical company, uses Semantic Web technologies to manage its global supply chain. The Semantic Web allows for efficient handling of constantly changing data and views, facilitating cross-organizational collaboration and data exchange between suppliers at every level of the supply chain. This leads to improved efficiency and reliability in managing complex supply chains [^1^].
3. Government: Governments can use the Semantic Web to improve public services, enhance transparency, and facilitate data sharing between agencies. This can lead to more efficient public administration and better-informed policy-making.
What are the challenges in implementing the Semantic Web?
Despite its potential benefits, there are several challenges in implementing the Semantic Web:
1. Reduced Anonymity: With the Semantic Web, information about individuals' identities, interests, and habits may become easier to discover, leading to reduced anonymity on the web.
2. Increased Invasion of Privacy: The Semantic Web could lead to increased invasion of privacy, as more personal information becomes accessible and potentially subject to misuse.
3. Intelligent Content Scraping: With the Semantic Web, content scraping could become more sophisticated, potentially leading to issues such as plagiarism or misuse of information.
4. Value Paradigm Shifts: The Semantic Web could lead to shifts in how we value information, potentially turning information into more of a commodity and raising questions about how to generate revenue from commoditized content.
5. Vocabulary Incompatibilities: The Semantic Web relies on vocabularies to classify and apply meaning to data. However, different people may use different vocabularies, leading to potential misunderstandings or conflicts [^2^].
These challenges highlight the need for careful consideration and management as we move towards the Semantic Web.
[^1^]: [Cambridge Semantics - Examples of Semantic Web Applications](https://cambridgesemantics.com/blog/semantic-university/semantic-technologies-applied/example-semantic-web-applications/)
[^2^]: [Semantic Focus - 5 Problems of the Semantic Web](https://www.semanticfocus.com/blog/entry/title/5-problems-of-the-semantic-web/)
Semantic Web Applications
What are some examples of applications that use Semantic Web technologies?
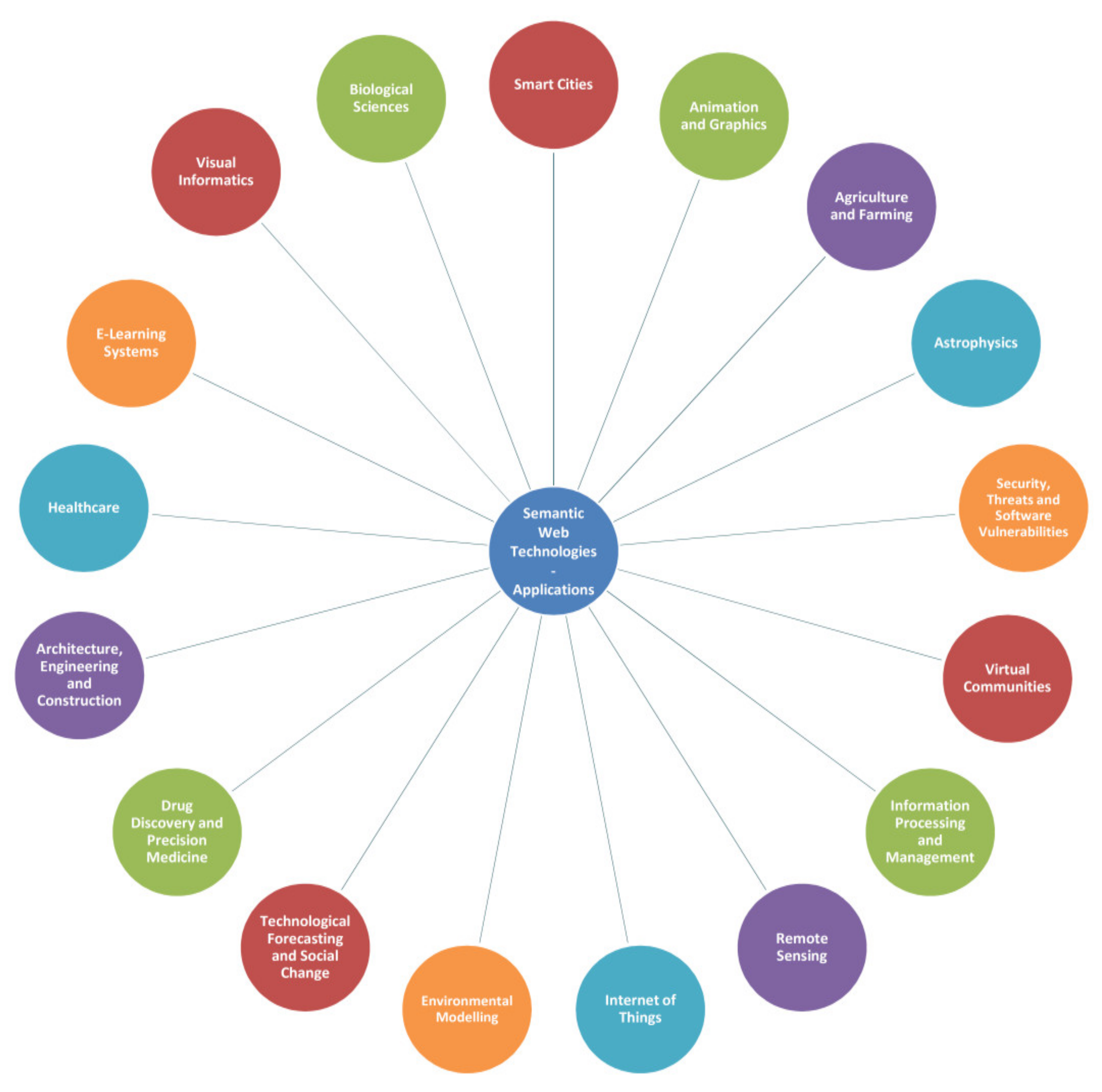
1. SemanticTeddy: This is a web application for intuitive editing of taxonomies and thesauri. It offers support for RDFS and SKOS vocabularies. The taxonomies and thesauri can be represented graphically, and may be exported as RDF/XML, Turtle, and N3. You can find more about this project on its [GitHub page](https://github.com/claudiu-mihaila/semanticteddy).
2. Semantic Knowledge Management Ontology for Online Library: This is a semantic web application for an online library management system. Queries are made in SPARQL language and data is stored in RDF format. Apart from the Client role, there is also the Admin role that has access to the admin panel for adding, editing, and deleting books. You can find more about this project on its [GitHub page](https://github.com/NensiSkenderi/semantic-knowledge-management-ontology-for-online-library).
3. Semiodesk UI5 Trinity RDF Contact Tracing: This is an OpenUI5 demo application for showcasing the Contact Tracing use case with an RDF Knowledge Graph Database via Trinity RDF. It also highlights the architectural data pipeline across several subsystems for connecting OpenUI5 to an ASP.NET Core server via OData v4. You can find more about this project on its [GitHub page](https://github.com/craicoverflown/semiodesk-ui5-trinityrdf-contacttracing).
These applications demonstrate the power and flexibility of Semantic Web technologies in various domains, from taxonomy editing and library management to contact tracing.
Future of the Semantic Web
What are some trends and future directions in the development of the Semantic Web?
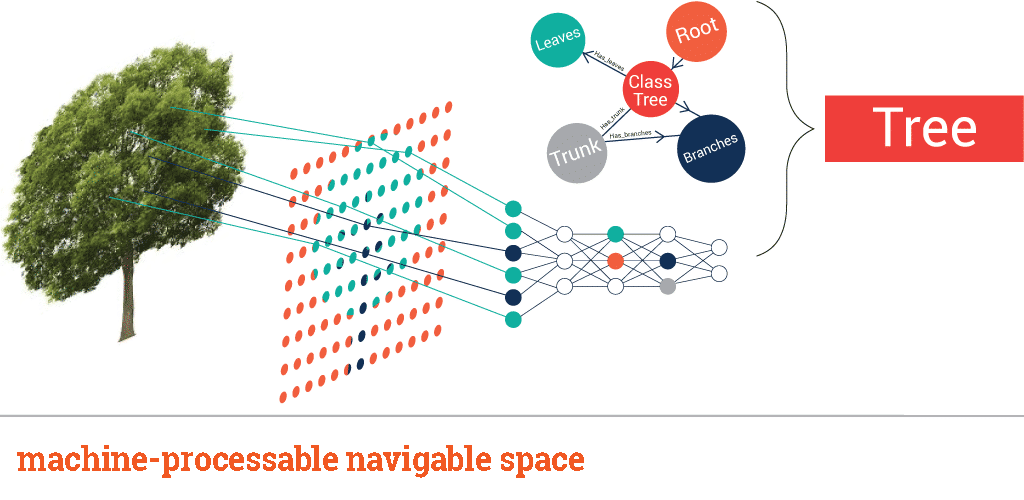
Here are some insights on the future trends and directions in the development of the Semantic Web:
1. Increased Interoperability and Integration: The Semantic Web is expected to continue enhancing interoperability and integration of data across different domains. This is particularly relevant in areas like digital humanities and cultural heritage, where Linked Data can help integrate and analyze large-scale digital data from various sources, making it more accessible and useful for research and discovery [^1^][^2^].
2. Standardization of Semantic Web Technologies: There's an ongoing effort to standardize the development of Semantic Web technologies. This involves creating a comprehensive index or guideline that quantifies the quality of work in Semantic Web technology, ensuring that it's designed well and can be evaluated quantitatively [^3^].
3. Application in Various Domains: The Semantic Web is finding applications in diverse fields. For instance, in healthcare, Semantic Web technologies are being used to create comprehensive knowledge bases about various datasets, helping healthcare professionals and researchers to identify, understand, and analyze major datasets more effectively [^5^].
4. Incorporation of AI and Low-Barrier Tools: There's a growing trend towards incorporating AI and low-barrier tools like Wikidata into the Linked Data production workflow. This can help scale up the production of Archival Linked Data, increasing access to and utilization of digitized and born-digital archives [^1^].
5. Uncertainty and Debate about the Extent of Realization: There's still debate among experts about the extent to which the vision of the Semantic Web will be realized. Some believe that progress will continue to be made in making the web more useful and information retrieval more meaningful. However, others think that the vision will take much longer to unfold than expected, and there's no consensus on the technical mechanisms and human actions that might lead to the next wave of improvements [^4^].
Please note that these trends are based on current research and expert opinions, and the actual future of the Semantic Web may evolve differently based on various factors given that we can see the merging of the semantic web as a branch of Machine Learning.
[^1^]: [Archives, linked data and the digital humanities: increasing access to digitised and born-digital archives via the semantic web](http://dx.doi.org/10.1007/s10502-021-09381-0)
[^2^]: [Digital cultural heritage standards: from silo to semantic web](http://dx.doi.org/10.1007/s00146-021-01371-1)
[^3^]: [A semantic web technology index](http://dx.doi.org/10.1038/s41598-022-07615-4)
[^4^]: [The Fate of the Semantic Web | Pew Research Center](https://www.pewresearch.org/internet/2010/05/04/the-fate-of-the-semantic-web/)
[^5^]: [Developing a healthcare dataset information resource (DIR) based on Semantic Web](http://dx.doi.org/10.1186/s12920-018-0411-5)
Thanks for reading till the very end.
Follow me on Twitter, LinkedIn and GitHub for more amazing blogs about Tech and More!
Subscribe to my newsletter
Read articles from Ronit Banerjee directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Ronit Banerjee
Ronit Banerjee
Building ProjectX.Cloud | GSoC'23 @ DBpedia | DevOps & Cloud Computing