Unlocking the Power of Kafka: Use Cases, Core Features, and Ecosystem
 Ajay Singh
Ajay Singh
Introduction
Kafka is a distributed messaging system that simplifies communication between source and target systems. It is widely used for real-time data processing and stream processing. In a traditional integration scenario where multiple source and target systems need to interact with each other, the direct interaction of source and target systems can result in complex integrations, with each integration coming with its own set of problems related to protocol, data format, and data schema. However, Kafka simplifies this process by decoupling the direct interaction between source and target systems. With Kafka, you can decouple the direct interaction of source and target systems, eliminating the need to write multiple integrations for every source and target system. In this article, we'll discuss Kafka's use cases, core features, and ecosystem.
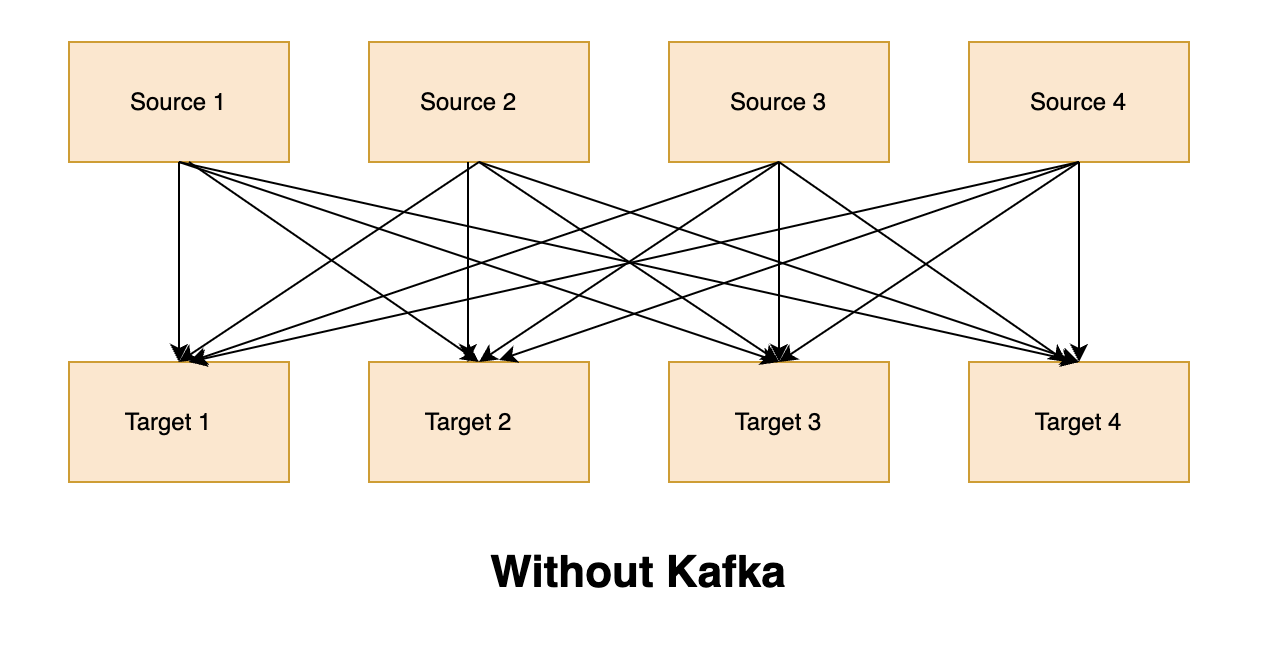
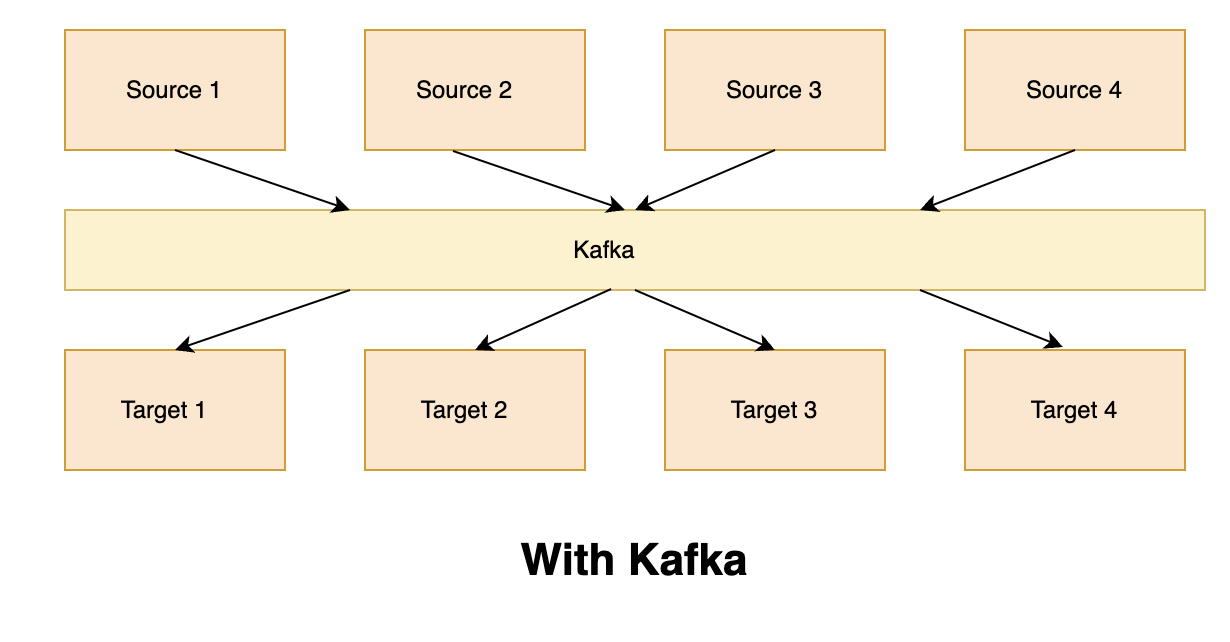
Use Cases of Kafka
Kafka's features include high resiliency, fault tolerance, horizontal scalability, and near real-time processing, with a latency of less than 10 milliseconds. These features make Kafka ideal for use cases such as messaging systems, activity tracking, gathering metrics from different locations, application logs, stream processing, and integration with Spark, Flink, and other big data technologies.
Kafka Core and Ecosystem
Kafka has several core components, including brokers, producers, consumers, topics, partitions, and consumer groups. Kafka also has an ecosystem of extended APIs, including Kafka Connect and Kafka Streams.
Kafka Connect: Kafka Connect is a tool for putting data into Kafka and taking data out of Kafka. It can be used to integrate Kafka with other data systems.
Kafka Streams: Kafka Streams is a client library for building real-time stream processing applications. It provides APIs for processing incoming data streams.
Mirror Maker: Mirror Maker is another useful tool that allows you to copy all the data from one Kafka cluster to another Kafka cluster.
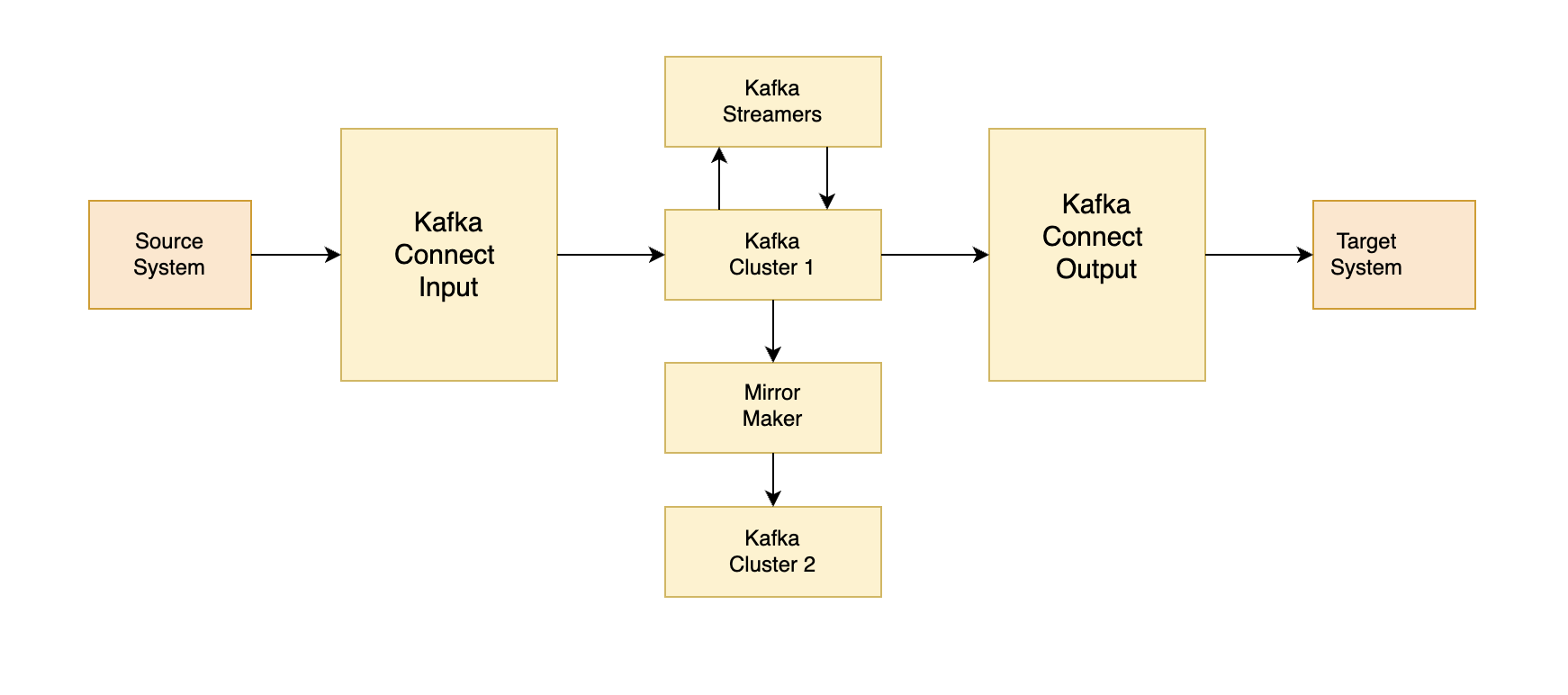
Schema Registry and REST Proxy: Kafka also has a schema registry and REST proxy. While Kafka allows you to push anything into it without verifying anything, there are times when a schema needs to be defined. The schema registry solves this problem, and it is good for Java producers and consumers. For non-Java producers and consumers, the Kafka REST Proxy is available. It allows you to use HTTP POST and HTTP GET to put and take data out of Kafka. The REST proxy directly interacts with the schema registry.
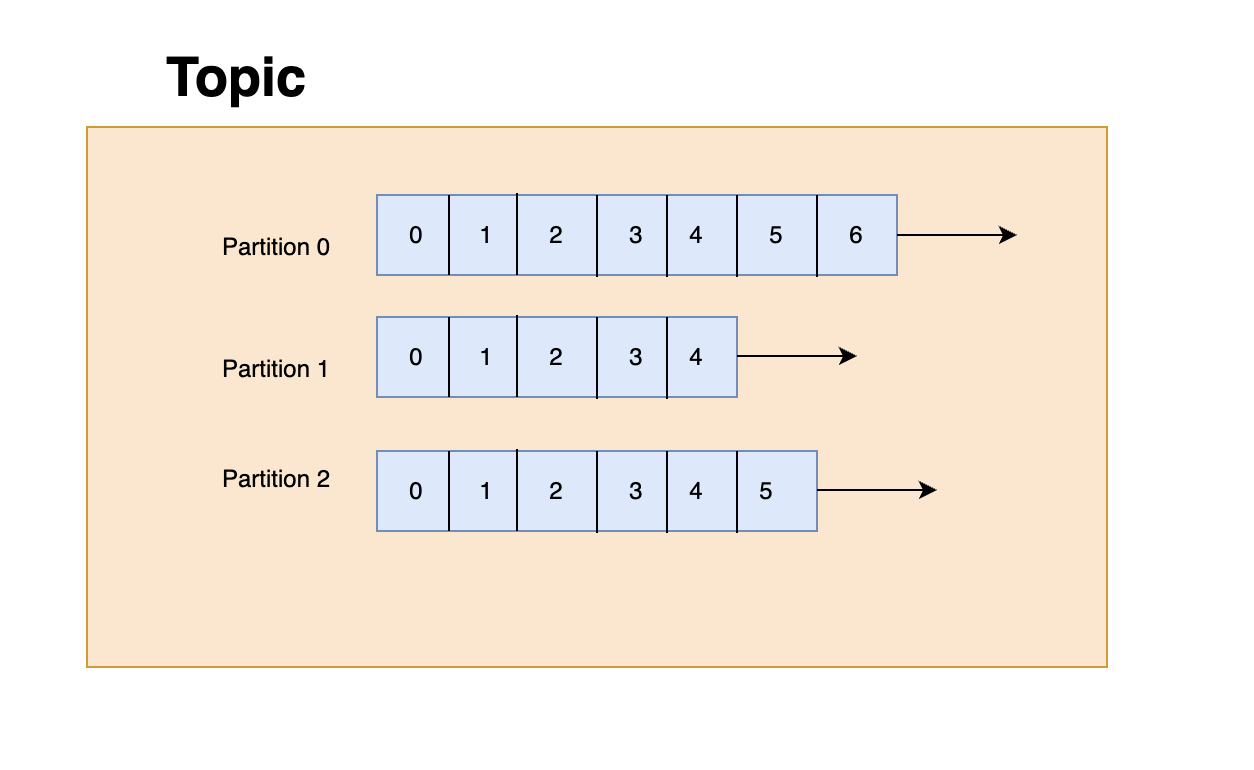
Topics and Partitions
In Kafka, a topic is similar to a table in a database, and it is identified by its name. Topics can have as many partitions as needed. Each partition is ordered, and each message in the partition receives an incremental ID, called an offset. Offsets only have meaning for specific partitions, and the order is only guaranteed within a partition. Data is only kept for a limited time, with the default being two weeks. Once the data is written to a partition, it cannot be changed, which is known as immutability. Data is assigned randomly to a partition unless a key is provided. You can have as many partitions in a topic as you want.
Brokers
A Kafka cluster is composed of multiple brokers (servers). Each broker is identified by its ID and contains certain topic partitions. After connecting to any broker (called a bootstrap broker), you will be connected to the entire cluster. A good number to get started is three brokers, but some big clusters have over 100 brokers.
Topic Replication Factor and Leaders
A topic should have a replication factor greater than one (usually two or three). This way, if a broker is down, another broker can serve the data. At any time, only one broker can be a leader for a given partition. Only that leader can send and receive data for that partition, while the other brokers will synchronize the data. Each partition has one leader and multiple in-sync replicas (ISR).
If the leader goes down, a new leader is elected from the ISR by the ZooKeeper service. This election process is designed to ensure that only one broker becomes the new leader, and that it has the most up-to-date data. Once a new leader is elected, the ISR is updated to exclude any replicas that are out-of-sync.
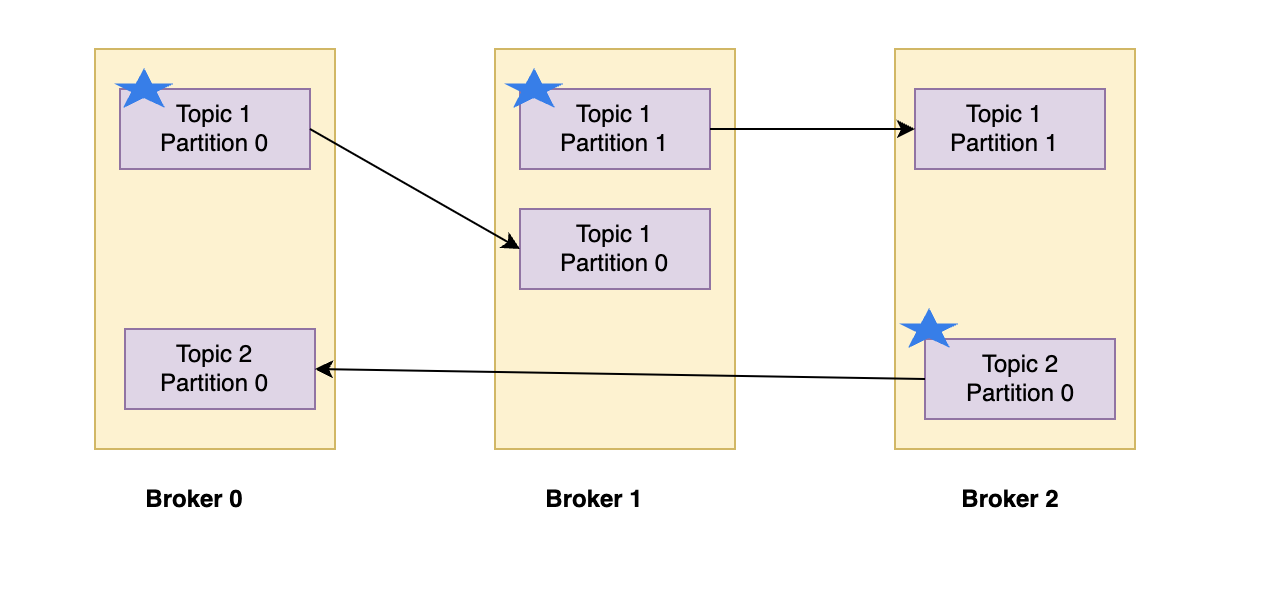
Producers in Kafka
Producers write data to topics. They only have to specify the topic name and one broker to connect to, and Kafka will automatically take care of routing the data to the right brokers. Producers can choose to receive acknowledgement of data write, with the following options:
Acks = 0: Producers won't wait for acknowledgement. In this case, the producer simply sends the message to the broker and does not wait for any response. This approach provides the highest write throughput, but it also has the potential for data loss if the broker fails before the message is replicated.
Acks = 1: Producers will wait for the leader's acknowledgement. In this case, the producer sends the message to the broker, waits for the leader to confirm that it has received the message, and then continues. This approach is more durable than the previous one, but it still has the potential for data loss if the leader fails before the message is replicated to all the in-sync replicas.
Acks = all: Producers will wait for the leader and replicas' acknowledgement. In this case, the producer sends the message to the broker, waits for the leader to confirm that it has received the message, and then waits for all the in-sync replicas to confirm that they have received the message. This approach is the most durable and provides no potential for data loss, but it also has the lowest write throughput.
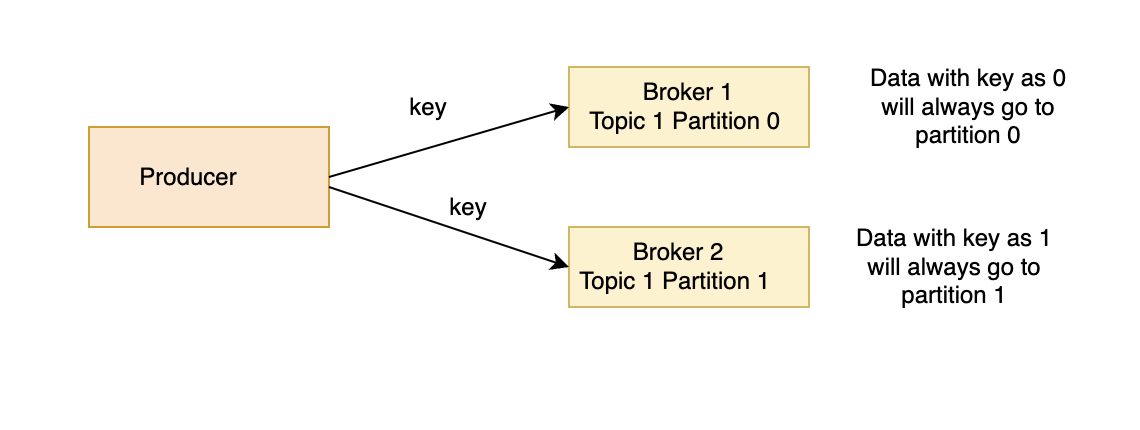
Producers can also send a key with a message. The key can be any sort of ID, and if a key is sent, then the producer has the guarantee that all messages for that key will always go to the same partition. This enables the producer to guarantee ordering for a specific key, which is useful in certain scenarios. However, if no key is sent, then the message will be assigned to a partition randomly.
Consumers in Kafka
Kafka consumers read data from topics, which are partitioned and distributed across multiple brokers in a Kafka cluster. Consumers only need to specify the topic name and one broker to connect to, and Kafka will automatically handle pulling the data from the appropriate brokers.
Data is read in order for each partition, but is read in parallel across partitions. This enables Kafka to achieve high throughput and low latency.
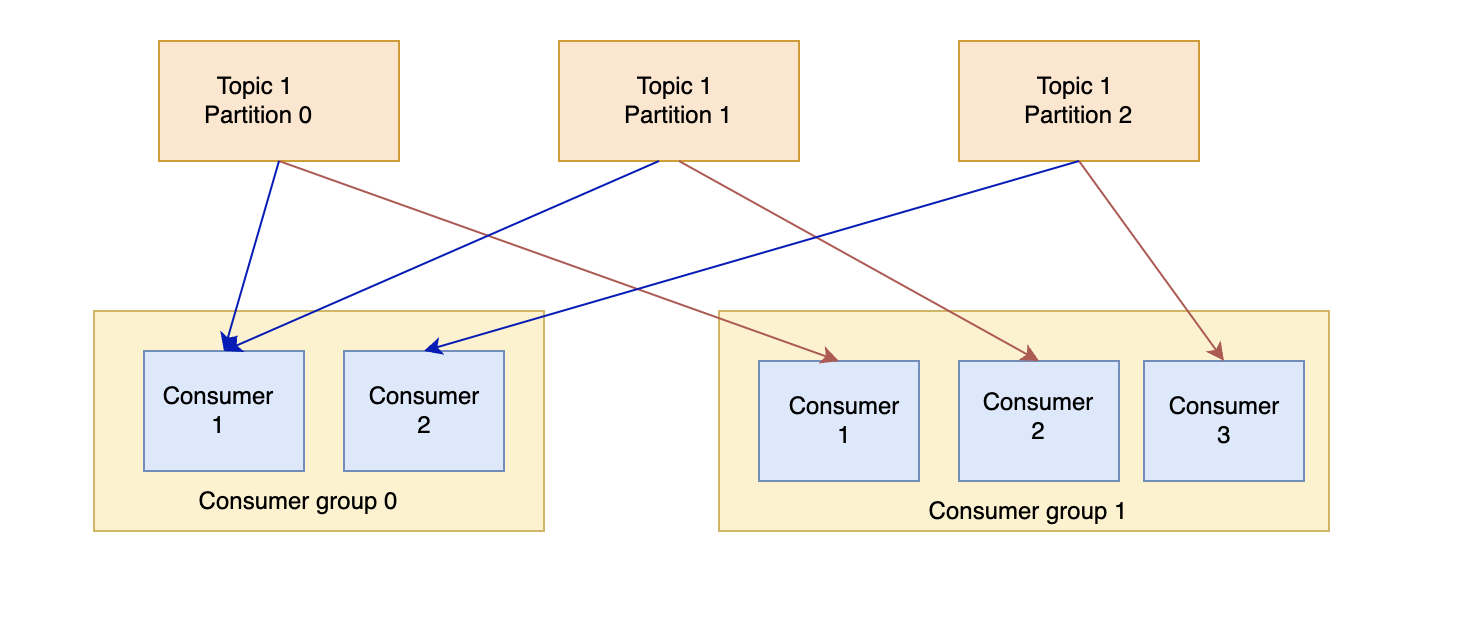
Consumer Groups
Kafka consumers read data in consumer groups, where each consumer within a group reads data from exclusive partitions. Consumer groups enable Kafka to scale horizontally and distribute data processing across multiple instances.
The number of consumers in a group cannot exceed the number of partitions, otherwise some consumers will be inactive. However, a consumer group can have multiple consumers reading from multiple partitions.
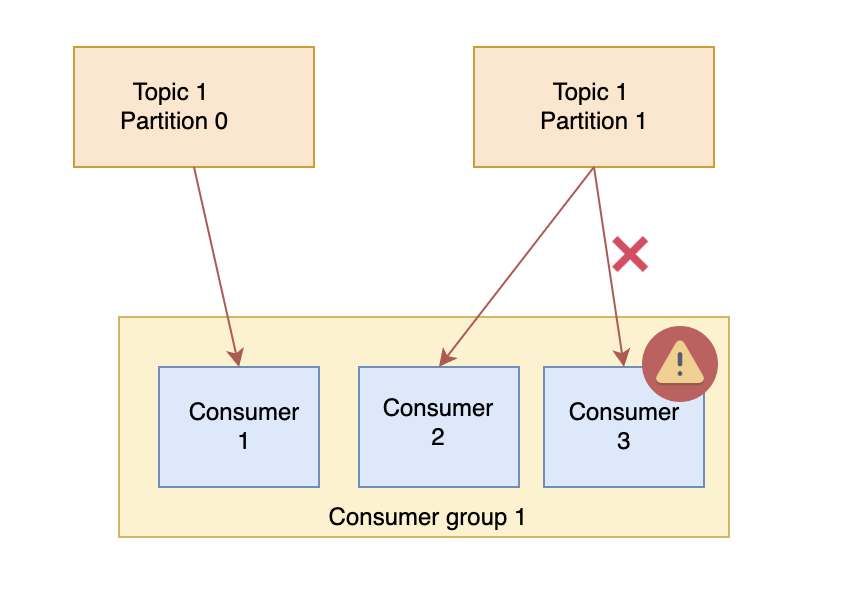
Multiple consumers in the same consumer group cannot read from the same partition. Each partition can be consumed by a single consumer in a consumer group. This ensures that each message is only processed once, and also enables Kafka to maintain message ordering for each partition.
Consumer Offset
Kafka stores the offsets at which a consumer group has been reading in a special Kafka topic called “_consumer_offsets”. When a consumer processes data received from Kafka, it commits the offsets so that Kafka knows where the consumer left off.
If a consumer process dies, it will be able to read back from where it left off thanks to consumer offsets. This ensures that no messages are missed or processed twice, even in the event of a failure.
Conclusion
In conclusion, Kafka is a distributed messaging system that simplifies communication between source and target systems, decoupling the direct interaction of source and target systems and eliminating the need to write multiple integrations for every source and target system. Kafka's features include high resiliency, fault tolerance, horizontal scalability, and near real-time processing, with a latency of less than 10 milliseconds, making it ideal for messaging systems, activity tracking, gathering metrics from different locations, application logs, stream processing, and integration with Spark, Flink, and other big data technologies. Kafka has several core components, including brokers, producers, consumers, topics, partitions, and consumer groups, and an ecosystem of extended APIs, including Kafka Connect, Kafka Streams, Mirror Maker, Schema Registry, and REST Proxy. With Kafka, producers can write data to topics by specifying the topic name and one broker to connect to, while consumers can subscribe to topics and receive data in real-time.
Subscribe to my newsletter
Read articles from Ajay Singh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Ajay Singh
Ajay Singh
I am a passionate full-stack developer with expertise in Spring Boot, Angular, SQL and JavaScript. My curiosity and eagerness to learn always drive me to stay updated with the latest technologies and trends. I am committed to delivering efficient and high-quality solutions to complex problems. When I am not coding, you can find me reading books or spending time with my family.