Comparison of LDA vs. BERTopic for topic modeling of code commit data
 Axel Lonnfors
Axel Lonnfors
At Metabob, when we started building the topic modeling system for our data pipeline, we were first utilizing a Latent Dirichlet Allocation (LDA) topic model. However, after spending time tuning the model to its best capabilities, our team continued research by looking into other potential topic models to use. We started iterating over Top2Vec and BERTopic and eventually landed on a decision to start utilizing BERTopic to prepare the dataset for our detection model training. In our case, BERTopic is used for analyzing the surrounding documentation of code changes and determining why something was changed based on the natural language available to analyze (think GitHub issues). We call the outputs from it our ‘problem categories’. These categories represent what is the high-level topic that the documentation describes, e.g., ML algorithm optimization. Some of the categories we get as an output are more descriptive than others.
In this blog, we’ll introduce some of the disadvantages of LDA for our use case as well as the advantages of BERTopic that lead us to our decision on the topic model. In addition, at the end of the article, there is a visualization of the embedding distances of the categories from BERTopic.
LDA
Latent Dirichlet Allocation (LDA) is a topic model but it’s also a statistical-based model
Here's a simplified explanation of how LDA works:
Random assignment: Each word in each document is assigned to a topic randomly. This random assignment gives both a topic representation of all the documents and word distributions of all the topics.
Iterative refinement: LDA then iteratively refines these assignments by going through each word and reassigning the word to a topic. The probability of assigning a word to a topic depends on how prevalent the topic is in the document and how prevalent the word is in the topic.
Final model: The algorithm iterates over and over and eventually reaches a steady state where the assignments are more sensible.
LDA has several disadvantages:
Preprocessing and parameter tuning: LDA requires careful preprocessing of the text data (like tokenization, stop words removal, and stemming) and also tuning of several parameters such as the number of topics. Poor preprocessing and wrong parameter choices can lead to poor results.
Lack of consideration of word order: LDA is a bag-of-words(a document is represented as the bag of its words, disregarding grammar and even word order but keeping multiplicity) model and doesn't take into account the order of the words in the document and the grammar.
Fixed number of topics: In traditional LDA, the number of topics is a hyperparameter set by the user and not learned from the data.
Assumes topics are uncorrelated: LDA assumes that topics are uncorrelated, which is often not true in real-world scenarios.
BERTopic
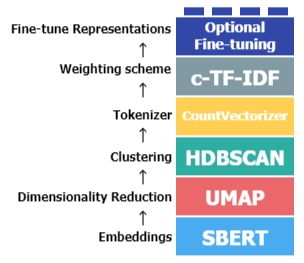
Unlike LDA, BERTopic leverages transformer-based models (like BERT) for embedding generation, while LDA uses a probabilistic modeling approach.
Advantages
Semantics: BERTopic, due to BERT's architecture, can better understand semantics, contexts, and nuances within the text data, providing better topic quality. This results in more meaningful and coherent topics compared to LDA.
Language Independence: BERT has pre-trained models for many different languages, and thus BERTopic can be used effectively for different languages. In contrast, LDA would need extensive preprocessing for languages that do not adhere to a subject-verb-object structure, like English.
Representation Learning: BERTopic leverages deep learning and representation learning. These models can capture more complex patterns in the text, whereas LDA is limited to bag-of-words or TF-IDF representations.
Noise Handling: BERTopic is often more robust to noise in the data because it uses sentence embeddings, which naturally handle noise better than bag-of-words models.
Evaluation
Topic Coherence: Both models can be evaluated using topic coherence measures, such as c_v, c_p, c_uci, and c_npmi. A higher coherence score often suggests that the words in a topic are more semantically related.
Manual Evaluation: We have human evaluators go through the topics and the documents associated with those topics. They can rate the quality of the topics on a scale (from 1 to 5). While this is labor-intensive, it can be one of the most reliable methods.
Metabob is now available as a VSCode extension to analyze Python!
Subscribe to my newsletter
Read articles from Axel Lonnfors directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Axel Lonnfors
Axel Lonnfors
I am a product manager working on a tool (Metabob) that aims to improve code reviews using a unique combination of graph neural networks and generative AI.