Power BI Direct Lake Mode : Frequently Asked Questions
 Sandeep Pawar
Sandeep PawarUpdated on Sept 09 2023
Microsoft announced an innovative dataset storage mode for Power BI called Direct Lake at Microsoft Build. It fundamentally changes how we create and consume BI solutions. It promises to provide the perfect balance between import and Direct Query modes. But does it? Let's dig into it and understand the hows and whats of it. I also share my experience at the bottom of the post. Please share your comments and questions below.
Please note that this blog post is based on my understanding of how Direct Lake works. If you find any inconsistencies or inaccuracies, please let me know. Refer to the official Microsoft documentation here. Watch this official demo by Christian Wade.
Give me a Direct Lake tl;dr
Until the Microsoft Fabric announcement, Power BI dataset had two primary modes of storage - DirectQuery and Import. DirectQuery gives you the freshest data from the supported data sources (e.g. SQL, OData) by directly querying the underlying source without a need for dataset refresh but at the cost of poor query performance. Import, on the other hand, can be used with any data source by importing the data into the dataset, offering the best query performance but you get stale data as the dataset needs to be refreshed frequently. The new Direct Lake mode, exclusively available in Fabric, aims to provide the best of both worlds by giving import-like query performance and the latest data even for large datasets.
How does Direct Lake work?
To understand it better, let's first recap what happens under the hood and how Direct Query and import modes work. When a user interacts with a visual, DAX queries are generated irrespective of the storage mode of the table. Let's take a look at a high level of what happens in each mode:
Direct Query: If the table is in Direct Query mode, DAX is translated to the native SQL queries which are sent to the relational database. The database runs those queries and sends the resulting data back to Power BI and visuals are rendered. This DAX to SQL translation negatively affects Direct Query performance.
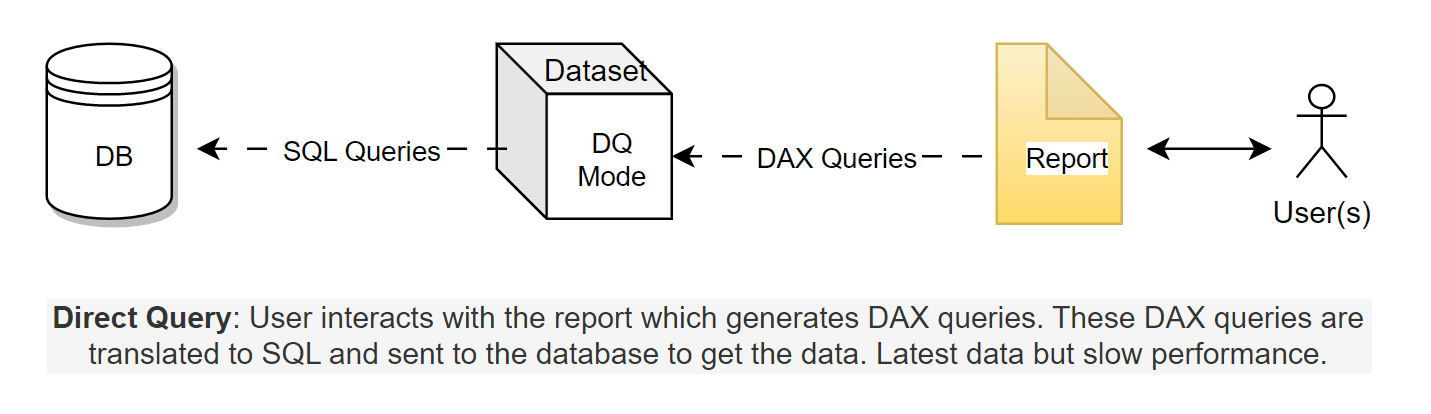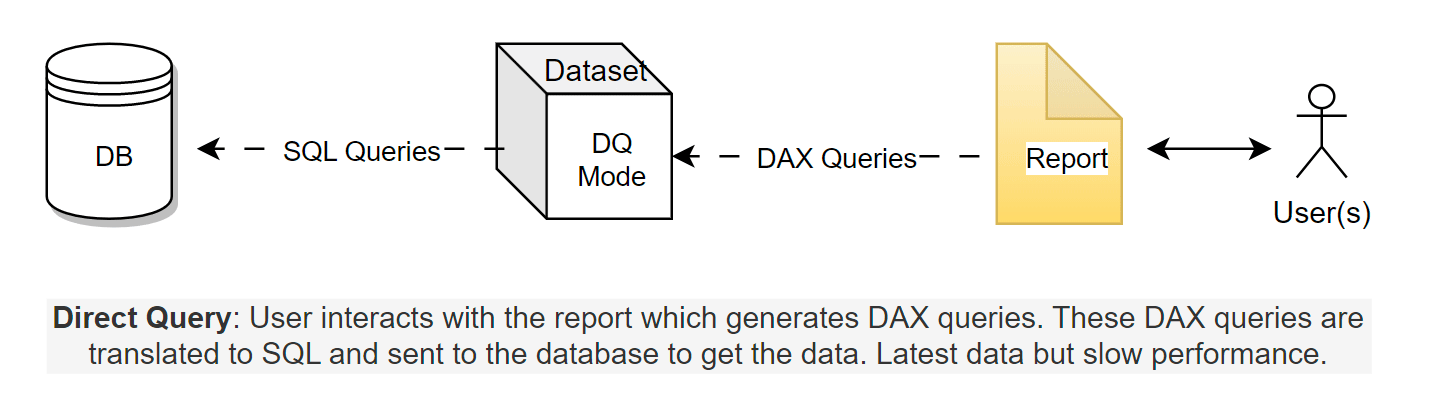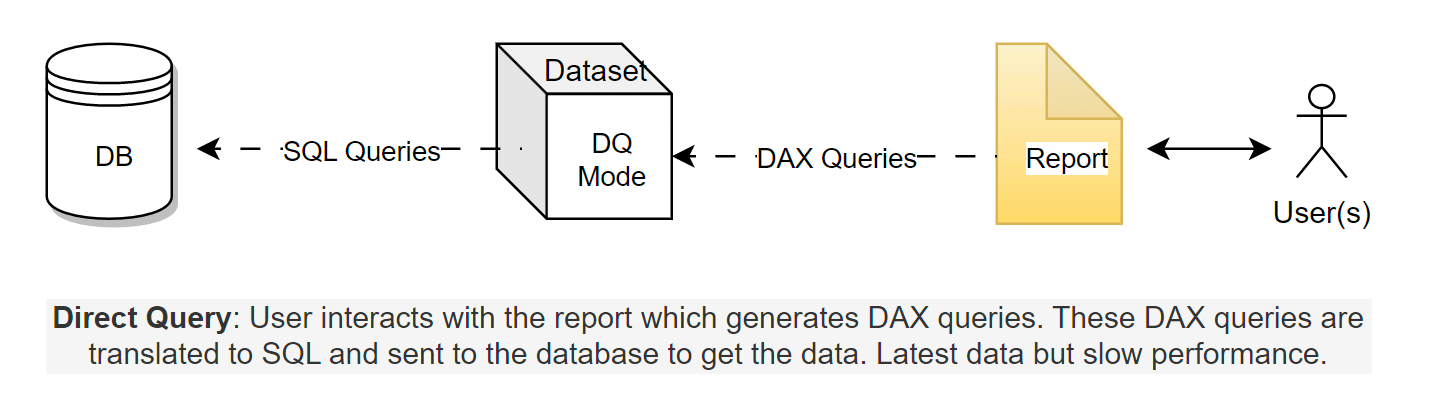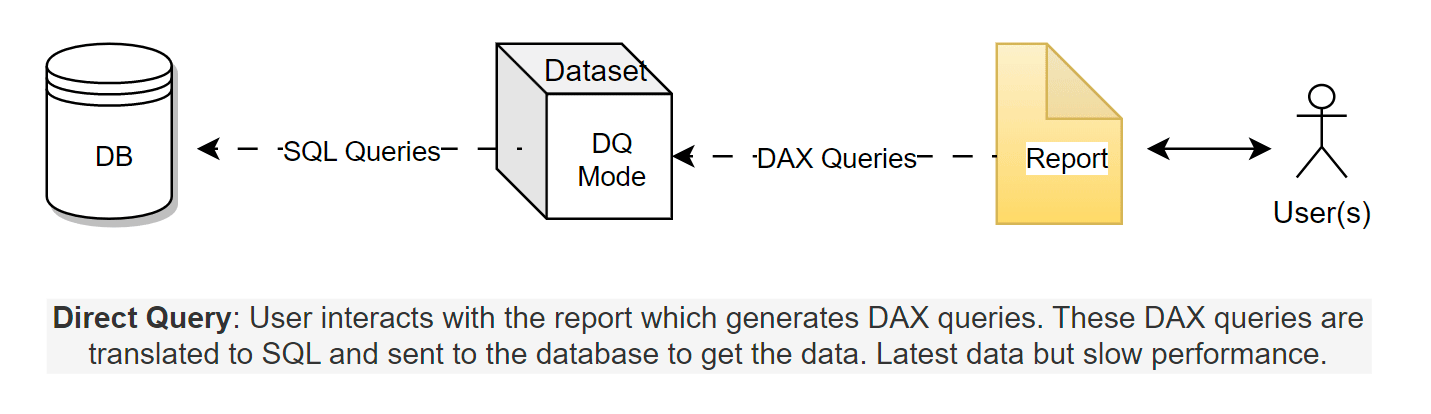
Import*:* In import mode, the data is imported into the model and saved in the proprietary *.idf files which are columnar storage files. When the user queries a visual, only the data requested by those queries (called vertiscan queries) are loaded on demand and returned to the visual. It's because of these proprietary columnar files that Power BI can significantly compress the data, thanks to the Vertipaq engine. The user has to copy the data from the source on a schedule, which can consume Power BI capacity resources. Any changes in the data must be captured by scheduled refreshes to copy the data again to the import dataset.
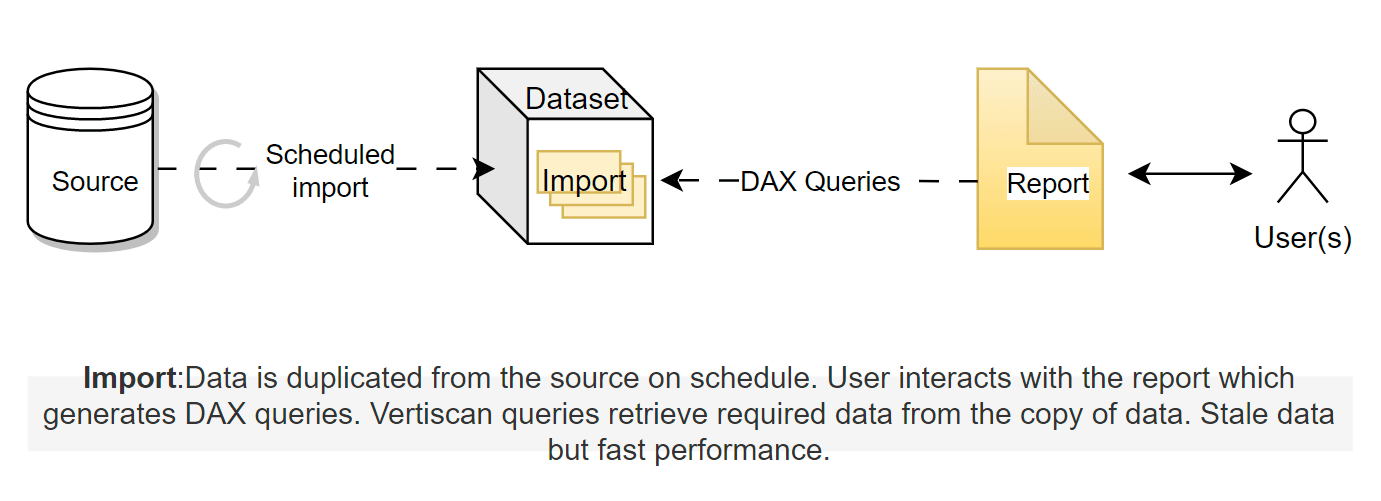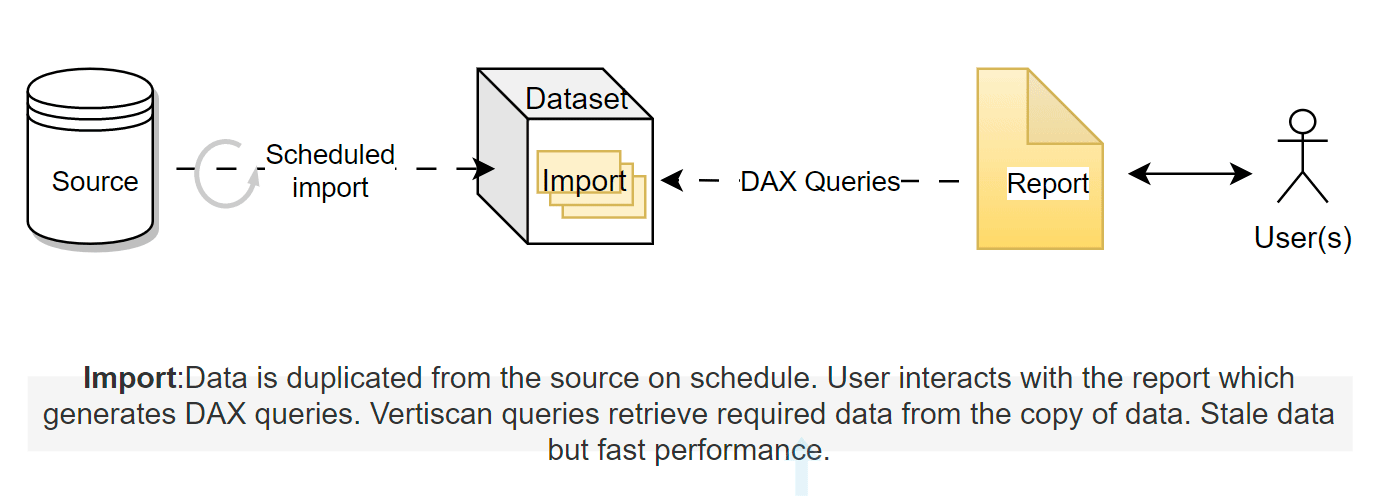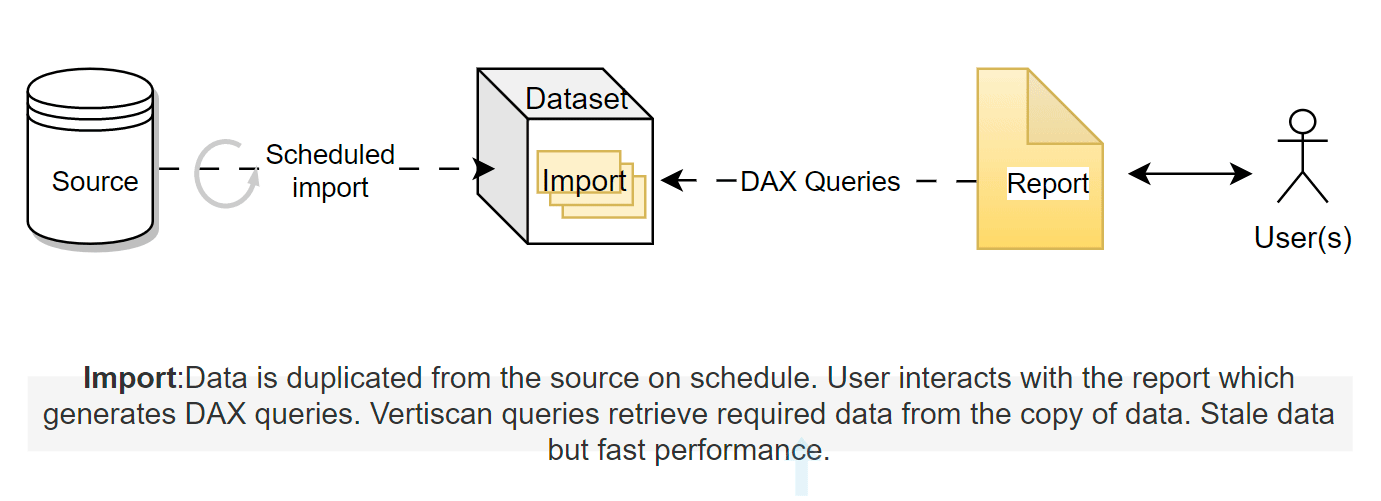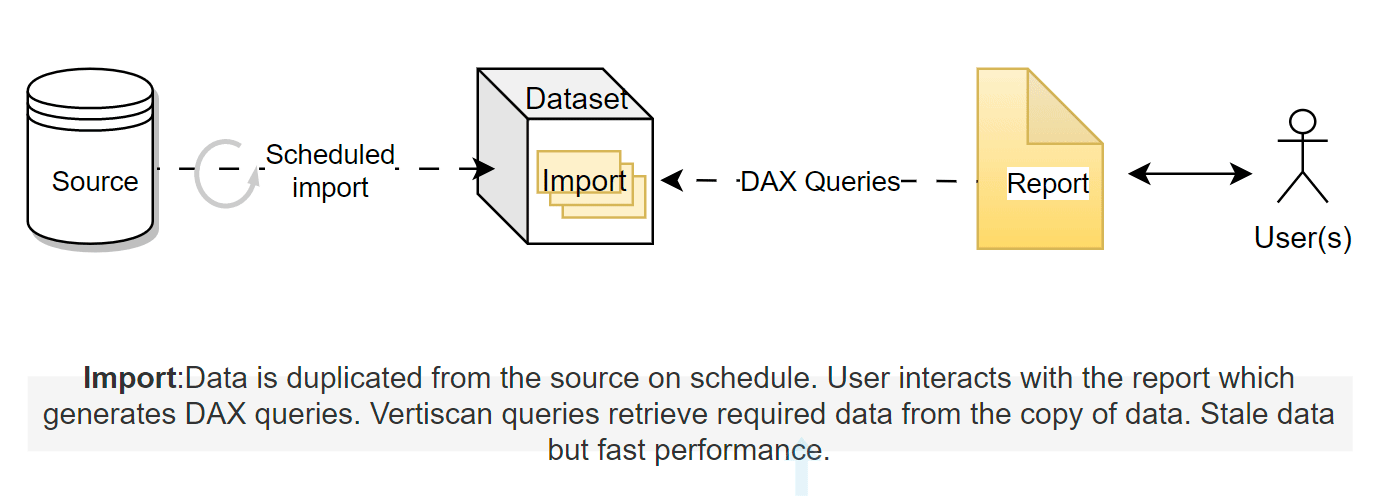
Direct Lake: Direct Lake essentially uses the same concept as the import mode. Because the parquet file is a columnar format, similar to the .idf files, the vertiscan queries are sent directly to the Delta tables and the requiredcolumns are loaded in memory. Delta uses different compression than vertipaq so as the data is fetched by Power BI, it is "transcoded" on the fly into a format that Analysis Services engine can understand. In Direct Lake, instead of the native idf files, the Delta parquet files are used which removes the need for duplicating the data or any translation to native queries. Another innovation Microsoft has introduced to make queries faster is the ability to order the data in the parquet files using
V-orderalgorithm which sorts the data similarly to vertipaq engine for higher compression and querying speed. This makes the query execution almost the same as the import mode. Data is cached in memory for subsequent queries. Any changes in the Delta tables are automatically detected and the Direct Lake dataset is refreshed providing the latest changes from the Delta tables. You will create the relationships, measures etc using web modeling or XMLA write (external tools) to turn the tables into a semantic model for further report development.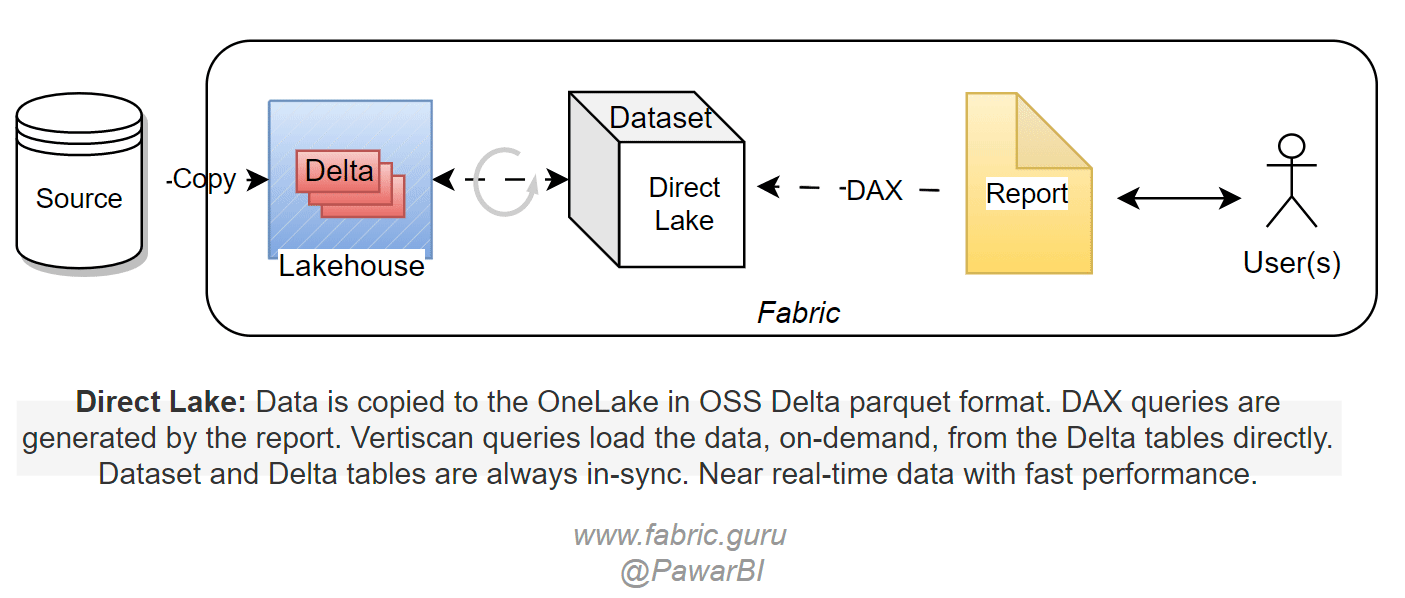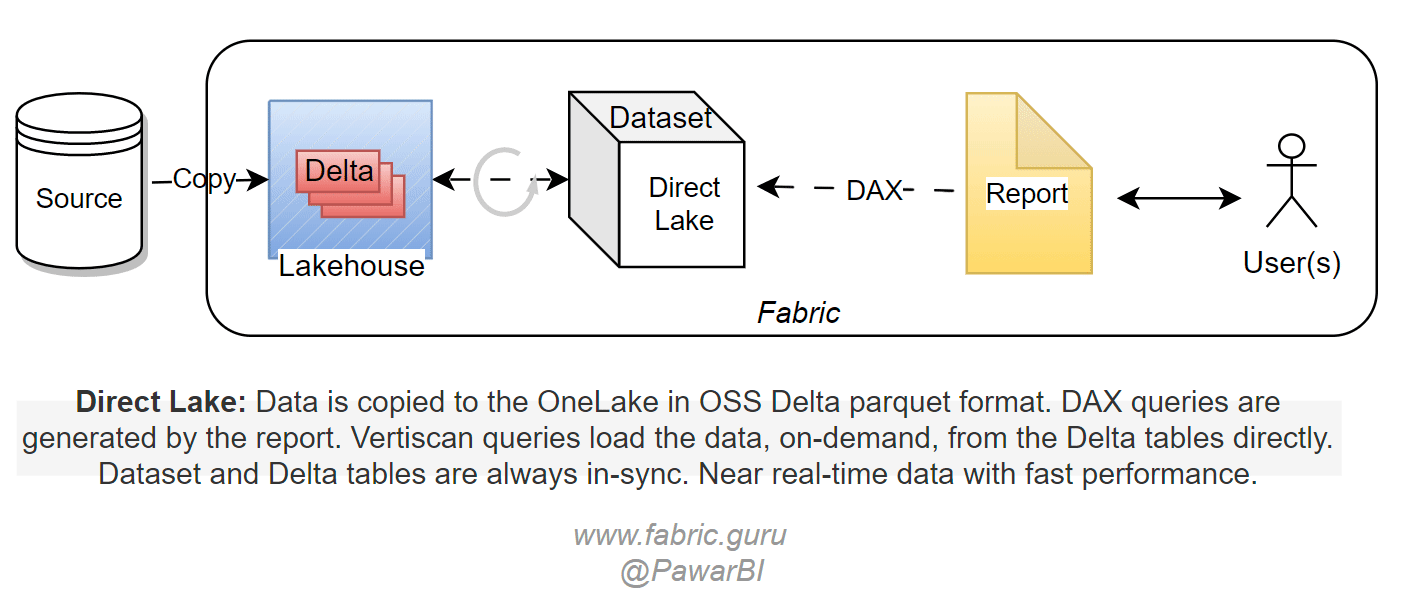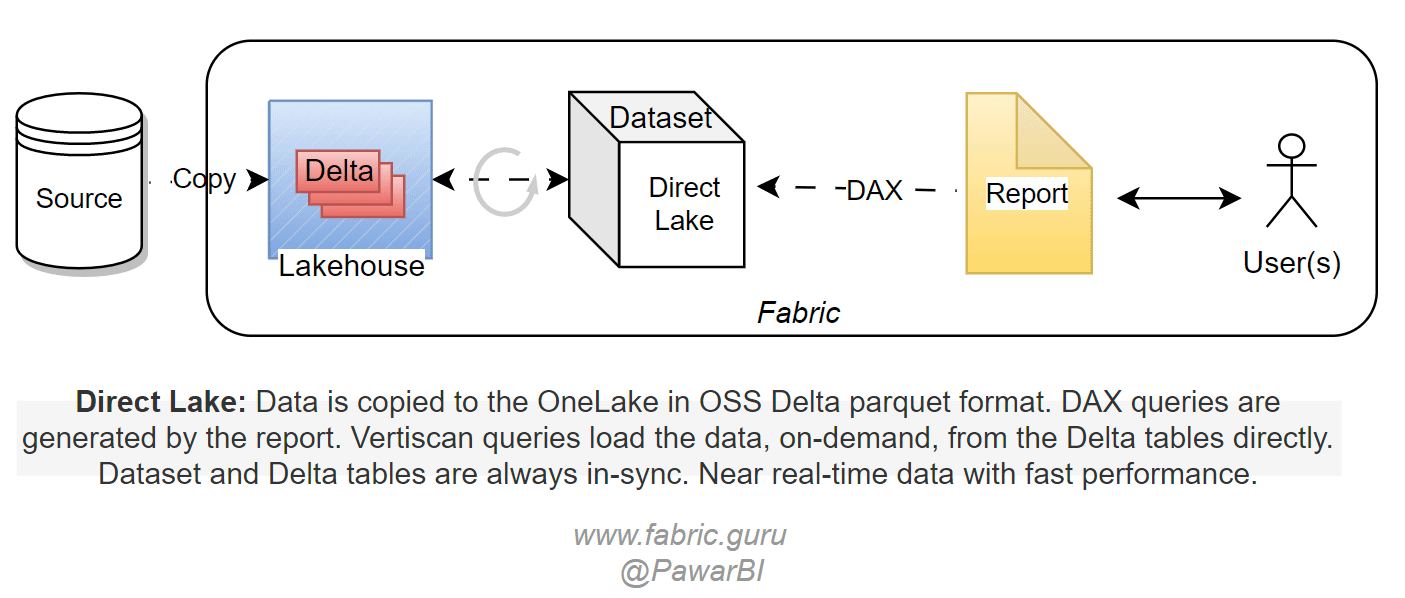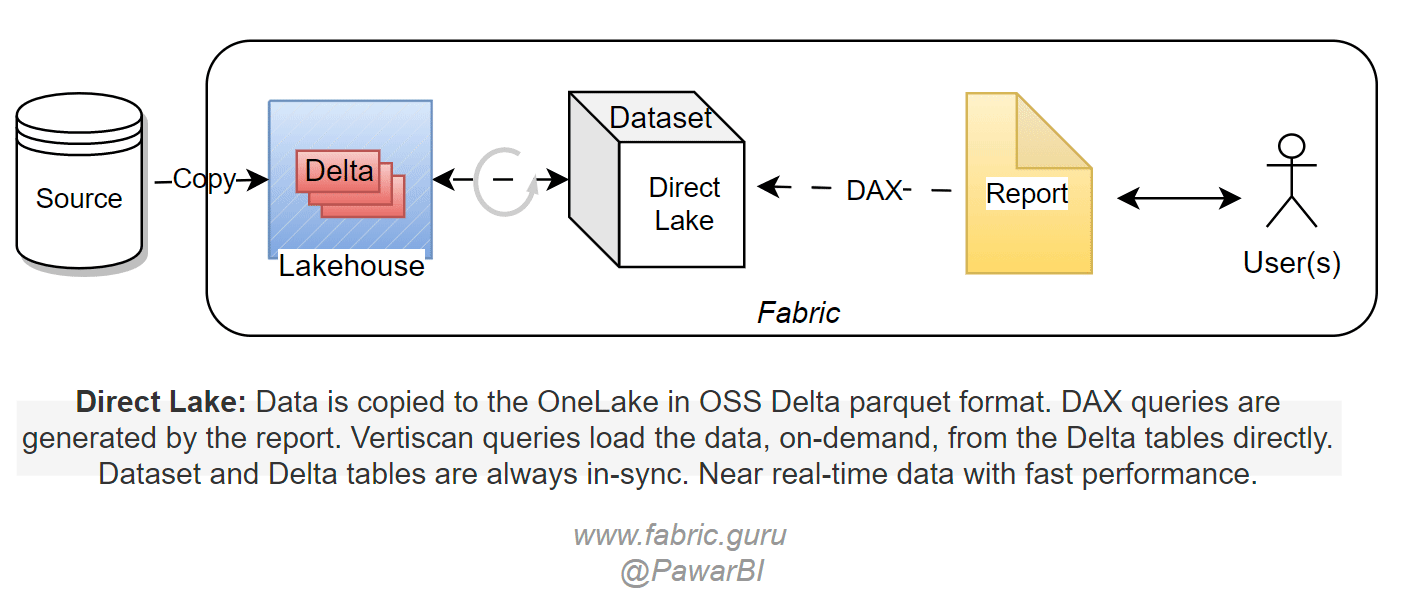
How is it different from the Live connection mode?
Live mode is just a connection to a dataset and not a storage mode in itself. When the user generates interactive DAX queries, it's sent to the dataset and depending on the storage mode of the underlying table (DQ or import), uses SQL or vertiscan queries to get the data back. In fact, in most cases, developers will be using the Live connection to a Direct Lake dataset to create the reports.
So the users still have to copy the data from the source to the OneLake on a schedule. How is that different from using the scheduled refresh in the import mode?
The user may or may not have to copy the data from the source depending on what the data source is and where it is stored. If the source data is in non-Delta format and/or not in another data lake, the users can use Spark engines (notebooks, pipelines, Dataflow Gen2, Kusto) to copy and transform the data at scale and save it as Delta tables. Power BI is not an enterprise ETL/ELT tool, especially at a large scale. Spark can load and transform the data at a much higher speed, scale and granularity than Power BI. You have access to the same existing data connectors available in Power BI.
If the data is already in another data lake (ADLSg2, S3 etc.), either in Delta or non-Delta ( csv, json, Excel etc.) format, the user can create shortcuts to those files without having to copy the data to OneLake.
Another huge difference is that Power BI is just another compute in Fabric eco-system using the data from OneLake. Other computes, such as Spark notebooks, data warehouse, Kusto etc. can access the same data as Power BI, offering the flexibility to choose any compute to create the analytics solutions. Thus, the number of refreshes and data movement will be lower compared to traditional approaches.
Refresh (aka framing) of the Direct Lake datasets is a metadata refresh option only, i.e. it doesn't load the entire data in memory again and irrespective of the dataset size usually lasts ~5 seconds, thereby significantly reducing the resource footprint. Import mode refresh loads the data in memory, Direct Lake refresh just syncs the metadata.
Does that mean Direct Query and import are going away?
Absolutely not. In fact, depending on the use case, the Delta tables can be used in Direct Query or import using the Lakehouse SQL endpoint. All the modes serve different purposes and depending on the requirements, data (volume & velocity) and the persona you can choose the right mode.
Is Delta table a hard requirement? Can I create Direct Lake dataset using csv, Excel files etc.?
Yes, Delta tables are a must. You can turn the CSV, Excel into Delta format to create Direct Lake dataset. Note that you can also create parquet/csv tables using spark, which will show up in the Tables section of the lakehouse, but it won't generate the SQL endpoint and hence can't be added to the dataset.
How do I create the Delta tables?
There are four primary ways at the moment depending on your experience and skill set.
Dataflow Gen2: If you are coming from Power BI background, you can use Dataflow Gen2 to import and transform the data using the familiar Power Query Online experience and save the resulting data to the Lakehouse as Delta tables. As you refresh the dataflow, it will automatically replace/append the data at scale.
Notebooks and Pipelines: If you are a Data Engineer or a Data Scientist with experience in SQL, ADF, Spark notebooks, python, R etc., you can use Notebooks or pipelines to copy and transform the data. Notebooks and pipelines can be scheduled, similar to dataflows, to create/append Delta tables.
Datawarehouse and KQL database generate Delta tables that can be used for Direct Lake mode. Views are also not supported for Direct Lake.
Load To Tables : You can select files in the lakehouse (csv, parquet) and select Load To Tables to convert it to Delta format.

Can I use Shared or Premium capacity to create Direct Lake datasets?
Direct Lake is exclusive to Premium P and Fabric SKUs and as such these datasets must be created in Fabric and reside in Fabric capacity.
Is there a limit on the dataset size?
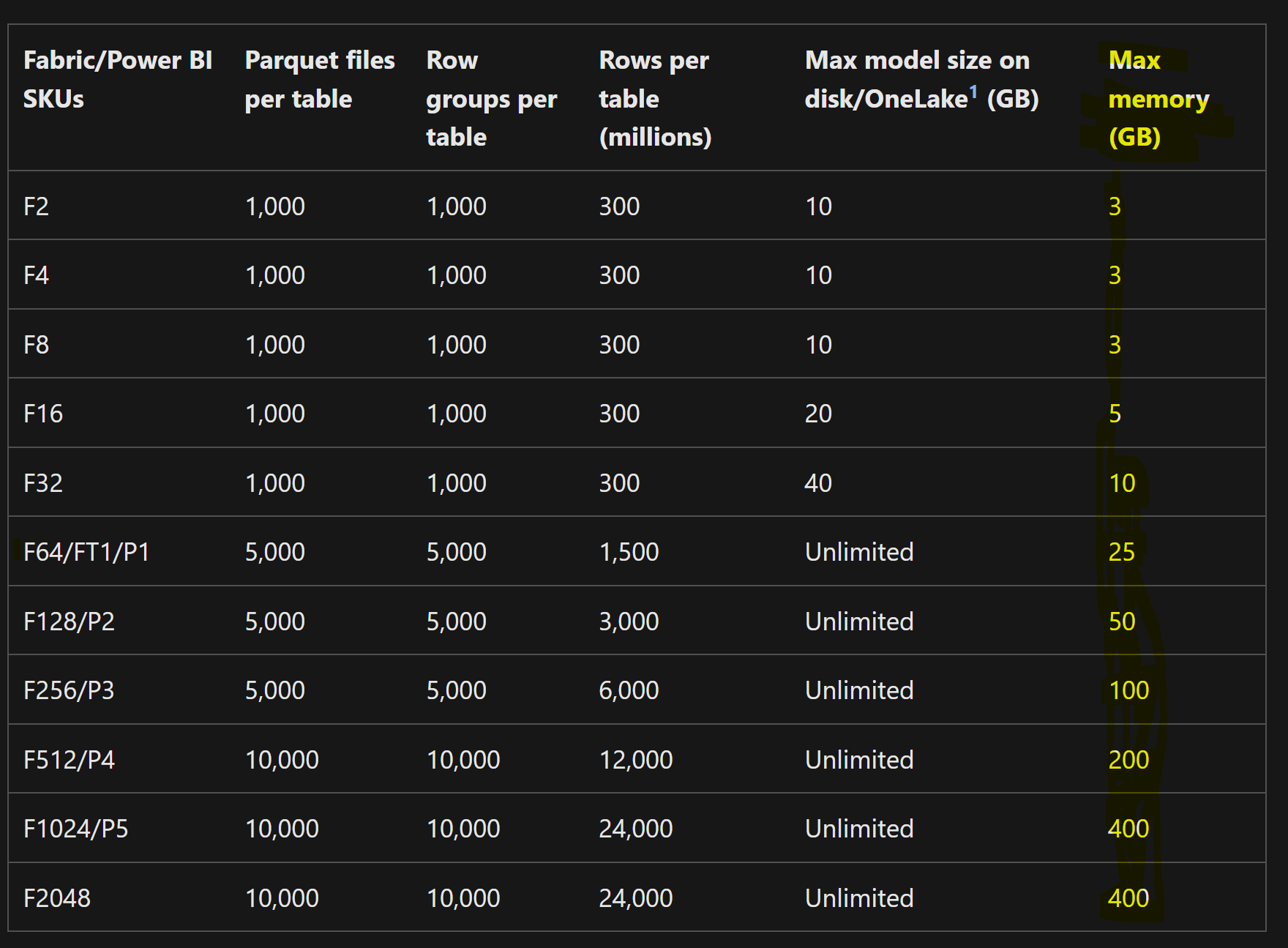
Yes, the limits are based on the F/P SKU and are posted here. There are two limits - model size on disk and size in memory.
The size limits look similar to import but there is a difference. In import mode, you load the entire dataset, so even if you don't use any columns or if the user never queries certain columns, those are loaded in the memory. If the original data is 50 GB in memory, you will always keep 50 GB in memory (roughly speaking). In Direct Lake, even if the Delta table is 50GB, if the user only queries certain columns, only those columns are loaded so the Direct Lake dataset size can be significantly smaller. If the users query the entire 50GB of data, you will likely run into memory pressures and will cause the model to be evicted from memory. Another distinction is that since refreshes are not needed, more data can be loaded. On-demand loading and paging means virtually larger datasets can be supported. In import mode, you need additional memory for refreshing the data which Direct Lake doesn't need. This also saves capacity resources. Similar to large dataset format, if certain columns are not used, they will be paged out dynamically thus reducing the size of the dataset.
What happens if the dataset size is exceeded?
Depends on which size limit is exceeded. If the size on disk is exceeded, it will fallback to DirectQuery. If the size in memory is exceeded, it will be paged out from memory.
💡You may be wondering, what's the difference between the two ? - When a Power BI semantic model is loaded in memory, it decompresses the data after loading it in memory. Hence, the size in memory is almost always more than size on disk. Read my blog on Direct Lake fallback mechanism for more details on how to calculate the size.In that event, will Direct Query limitations be applicable?
Yes, you will see Direct Query experience (potentially slower performance).
Can you create a composite model with Direct Lake?
You cannot mix and match storage modes at the moment in web modeling. You can certainly use Direct Lake dataset in local mode to create DQ over Analysis Services and then bring in additional data for the composite model in Desktop.
Can you create a Direct Lake dataset in Power BI Desktop ?
No. The dataset has to be created in service or using external tools.
Can I use XMLA endpoint to create/edit the model using Tabular Editor?
Yes. XMLA-W became available on Aug 9. You can read more about it here. Note that if you create or edit a Direct Lake dataset using XMLA, you cannot use the web modeling feature. Read this detailed blog post on how to use Tabular Editor to create Direct Lake dataset.
Can you connect to a Direct Lake dataset in Desktop in a Live mode ?
Yes. Once you create the semantic model using the web editing in service, you can connect to the dataset in Live mode in the Desktop to create reports.
Are there any limitations on the DAX functions?
In Direct Lake mode, there are no limitations. You use the same functions as the import mode. However, if the query falls back to Direct Query, then any Direct Query related limitations will be applicable.
Can I create Row Level Security?
You can define RLS using fixed identity using Tabular Editor 3. The web experience in service has not been rolled out yet. Note that RLS defined in the DWH will cause the queries to fall back to Direct Query.
That's a significant limitation.
Yes, OneSecurity will provide unified security across all Fabric item types including semantic models. Currently it is not available.
Will it work on existing Delta tables ?
It depends. You can either upload existing delta tables to the Lakehouse or if the Delta tables are in ADLSg2 or S3, you can create shortcuts to those tables. There is no copying of the files if shortcuts are created. Currently, Fabric does not support Delta protocols with Reader v2 and Writer v5. Delta with higher protocols will not generate the SQL endpoint.
Do the Delta tables need to be in OneLake?
If the shortcut can't be created, then yes.
Can I create Direct Lake dataset using Apache Iceberg/hudi (or any other table formats)?
Not currently. There is a OneTable open source format that allows interop between various table formats without copying the data. Microsoft is one of the contributors this project so hopefully in the future, this will be supported out-of-the box to use other table formats easily in Fabric.
What is the
vorderyou mentioned above?Think of it as a shuffling algorithm that sorts the data in the parquet files before saving it as parquet or Delta parquet. This is similar to what vertipaq does to achieve additional compression and fast query performance. Data is dictionary encoded, bin packed similar to vertipaq. Read more about V-Order here.
How do I create
vorder?All Fabric compute engines (spark notebooks, pipelines, Dataflow Gen2) automatically create Delta tables that are vorder'd. You can also specify the Spark configuration if you want to
spark.conf.set("spark.sql.parquet.vorder.enabled", "true")or while saving the Spark dataframe as a Delta table.option("parquet.vorder.enabled","true"). I thinkvorderis idempotent but I will have to confirm that. KQL tables do not yet apply V-order optimization.Does
vorderimprove Direct Lake performance?Yes. In my tests, I saw performance gains in loading the cold-cache data, in some cases warm-cache as well. Delta files were also compressed more and write speed was also 1.5x faster in some instances. I will write a detailed blog later to share the details. Please note that it also depends on the column type and cardinality of the column, so performance may vary.
Is vorder same as zorder in Databricks?
No, zorder is used to produce evenly balanced data which reduces the number of scans to read Delta tables.
vordersorts the data for optimum compression. Both are complementary to each other and will improve performance. It's recommended to Zorder before V-order.Is
vordera must-have requirement for Direct Lake?No, Direct Lake will work with non-vorder Delta tables too, it just may not perform as optimally. Also, note that only Fabric engines can create
vorderDelta tables, it's not an open-source algorithm.How do I know if a Delta table used for Direct Lake dataset has
vorder?There are two ways to do that - either inspect the Delta transaction log file or use pyarrow. Please read my blog for details.
Any other restrictions on V-Order?
Yes, sorting a table in spark will invalidate V-order. You will have to force the V-order by a spark config. Read my blog.
Does Direct Lake dataset built on top of shortcut'd Delta tables have a performance impact?
It may or may not have an impact depending on many factors. In my tests, querying a large (50M rows) Delta table on Amazon S3 bucket via Direct Lake showed a minor performance drop. But it may vary based on geography, network, configuration and many different factors. Be aware of potential egress charges when using shortcuts.
If you create a shortcut to a Delta table that's outside OneLake, note that you can still run OPTIMIZE on it or use table maintenance API to vorder those tables. I would recommend testing this before applying on production data.
Are partitioned Delta tables supported?
Yes.
If the Delta table is partitioned, will Direct Lake do partition pruning?
No, if you query a column with a filter applied, it will still load the entire column and not just specific partitions. This may change in the future. Only the selected columns are loaded.
Will parquet rowgroup size affect Direct Lake dataset performance?
Yes. Fewer rowgroups with tightly packed columns means
vorderwill have a chance to apply sorting on large block of rows. This should improve performance and avoid small file problem. But as always, it will depend on many other factors. There is also a limitation on the number of rowgroups but it hasn't been published. I will share my results in future blogs. Read my blog for details.Does it matter which compute engine I use to write the Delta tables?
Absolutely. At least as of publishing my blog on June 27, 2023, all Fabric engines created different Delta tables. This will affect Direct Lake performance. Read my blog for details. In general, spark will provide the most flexibility and knobs to optimize the tables. I need to do more tests to see how recent the recent improvements to delta affect the performance.
Does the compression codec used to compress the parquet (snappy, gzip, zstd) affect Direct Lake performance?
My tests with snappy and zstd did not show any difference in cold cache performance. Other codecs such as gzip and brotli typically have poor read performance so best to avoid them unless necessary. A detailed blog on this topic will be published soon.
What is Default dataset vs Custom dataset?
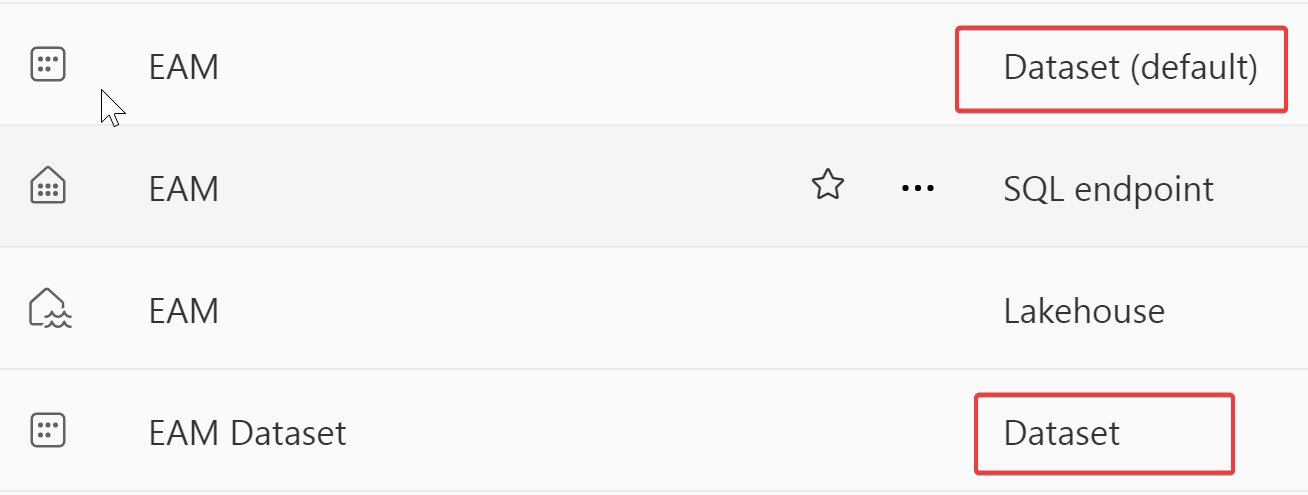
This is one of the confusing parts of Direct Lake dataset. Let me explain:
When you create a Lakehouse with Delta tables in it, a default dataset is created with all the tables in the Lakehouse. This is very similar to the default dataset created in Datamart. You can choose tables to exclude from the default dataset. It uses the TDS endpoint of the Lakehouse and is in Direct Lake/DirectQuery dual mode. It always stays in-sync with the Delta tables for any changes. If the 'Automatically update dataset` option is checked, any schema changes are also captured. However, the big limitation is that you cannot use XMLA-write. There is no refresh option. The Default dataset is also performance optimized. I have seen in some cases, default dataset perform faster in cold cache compared to custom dataset. I am not sure why. Default dataset is the best option when the data model is not complex, measures are simple and you want to use all the tables from that Lakehouse. Default dataset is identified as
Dataset (default)in the data hub. I wish there was a way to turn off default dataset to reduce number of artifacts. There is a known limitation of default dataset not getting generated if there is only one table. This is temporary. The Default dataset story is evolving, I will update the post when I have more details.Custom dataset, on the other hand, allows you to pick and choose the tables to be included. It also stays in sync with the Delta table if auto-sync is turned on. You can disable auto-sync and refresh using UI, REST API or manually. In the future, XMLA-W will be available for custom datasets. In most cases, it's the custom dataset that should be used for flexibility and pro-development. You can only create custom dataset in the Lakehouse.

Does Direct Lake dataset need to be refreshed?
The Default dataset doesn't need to be refreshed. Custom datasets, if auto-sync in on, will look for changes in the Delta table at a fixed time interval. (I need to confirm the interval used for polling before sharing). If Delta table has changed, it will refresh (i.e framing) the dataset. If you can also turn off auto-sync and refresh with a scheduled interval similar to import dataset.

Can I use existing REST APIs to trigger a Direct Lake dataset refresh ?
Yes
Can I do a selective refresh of a table?
I think so because I was able to process just one table in SSMS. But I need to confirm.
When and how does caching occur?
There are two caching mechanisms. Cold cache and warm-cache. When the framing occurs, Direct Lake dataset does metadata refresh and unloads all the memory, there is no data in the dataset. As soon as the first user interacts with the report, Direct Lake dataset loads data on-demand for the columns involved in the query. This is called cold-cache. If the user runs the same query again, the cached data is used and Delta table is not queried again. This is warm-cache. As the user applies more filters and interacts with different pages, more data is pulled into the cache and made available for subsequent queries. Currently, the cold-cache performance is not great and is very close to DirectQuery performance. If you want true import-like performance, you will need data in warm-cache. As soon as the framing occurs (i.e. dataset is refreshed), it will hit the cold cache again. Read more about it here.
Is it possible to always cache certain columns or tables after refresh?
Yes but not via UI. Read this blog on how to pre-warm the cache so the users will always get fast performance.
Is it possible to see which columns have been cached?
Yes, you can run this DMV in SSMS or DAX Studio
SELECT * FROM $SYSTEM.DISCOVER_STORAGE_TABLE_COLUMN_SEGMENTSand look for columns that have been paged in memory. Another easy option is to run Vertipaq Analyzer in DAX Studio.I have created the Direct Lake dataset but see this error message "ParquetException Unexpected end of stream" in the report visual.
I have seen this error message before and was able to fix it by running
OPTIMIZEon the delta table.Does Direct Lake dataset use M ?
No. You can use Dataflow Gen2 to ingest and transform data and sink it to the Lakehouse. But once the table is created, you cannot edit it using M in the Lakehouse. If you used Spark or pipelines to create the Delta tables, you cannot use Dataflow Gen 2 or M to edit the table.
If it doesn't use M, what about custom functions, and parameters?
You can use parameters inside the Dataflow Gen2 but not in the Delta table.
So no parameters at all?
Nope. If you have existing datasets that use parameters for connection strings or some function or transformation logic, that will need to be refactored. For example, typically for various deployment stages, we reduce the number of rows or use different connection strings etc and change it in service in dataset settings. Direct Lake datasets do not have that option.
What about partitions?
Direct Lake datasets have only one partition and you cannot change it or create additional partitions.
Then what about incremental refresh?
Direct Lake datasets do not have an incremental refresh. You can create incremental loading using Spark, pipelines or Dataflow Gen 2 to append/merge additional data. Blog to come.
Can I create calculated tables?
No. You cannot create calculated tables or columns.
Are all TOM properties currently available in import mode supported in Direct Lake mode?
Most are but not all. I don't have a list of what's available.
Does it support Calculation Groups?
Yes, support for calculation groups was added on Sept 6 2023. Check out this blog post. Note that you still need external tools such as Tabular Editor to create CGs.
Where do you write measures?
In the web modeling experience or using the external tools with XMLA endpoint.
Is it possible to always use the DirectQuery mode as default instead of the Direct Lake mode?
No, you cannot force it to be in one mode vs the other. It's always in Direct Lake by default, for now.
Can I evict a column from memory?
As far as I know, no. It will be evicted automatically either because of memory pressure or if it has not been accessed in a while.
Are the query plans created in Direct Lake the same as import mode?
Technically yes they should be but it may be different in some cases at least in Public Preview.
Can I apply MIP labels to Direct Lake datasets?
Yes.
Can I refresh a Direct Lake dataset in a pipeline?
Yes using the REST API.
Can I publish a Direct Lake dataset to a different workspace than the workspace of the Lakehouse?
No, currently the dataset must be in the same workspace as the Lakehouse
Can I use tables from different workspaces and Lakehouses?
Yes, you can shortcut tables from other Lakehouses
Can I shortcut to another Lakehouse authored by another user?
Yes if you have access to the Lakehouse.
Can I use Deployment pipelines with Direct Lake datasets?
Yes, and more. You can fully integrate with ADO for CI/CD.
What's the best way to migrate an existing DirectQuery or Import dataset to Direct Lake?
No matter what, there will be some refactoring needed. Dataflow Gen2 would be the easiest to refactor as you can use the M scripts, functions and parameters. The challenge will be calculated columns and tables. You will either need to build that logic using M (hard if DAX is complex) or use pyspark which will offer Python's flexibility with recursion and scalability.
If I create a table in Datawarehouse, can it be used for Direct Lake?
Yes, tables created in the Fabric DWH can be used and in fact V-Order optimized as well.
Delta tables have time travel, can I use it in Direct Lake dataset?
Not at the moment.
What happens if a column data type changes, columns are dropped or added?
For schema evolution, first you need to make sure in spark, schema evolution is allowed. Default dataset automatically takes care of changes with schema. Custom dataset will need to be manually updated.
Can I download Direct Lake dataset from service?
No
Can I serialize the Direct Lake dataset as .bim or .tmdl ?
Right now the XMLA is read-only so no. But considering Microsoft is actively supporting TMDL development, safe to assume it will be supported in the future.
There is also support for Power BI projects, a new format. How it works with Direct Lake I am not sure.
Can I use Analyze in Excel with Direct Lake dataset?
Yes
Can I use Direct Lake dataset with Paginated Reports?
I am not 100% sure. I need to check.
High cardinality columns are what kill import dataset compression and performance. Is that the case with Direct Lake dataset as well?
Yes. High cardinality columns are harder to compress. If the dataset is large, it will fail to load the column because of the column size. Also note that import dataset cannot have more than 2B unique values in a column. I am not 100% sure if that applies to Direct Lake but that's a large column and likely won't be supported. In that case, it will fall to DQ.
Is there a limit on number parquet files in a Delta tables used for Direct Lake dataset?
Yes, I think it's based on the SKU. Refer to the documentation for correct numbers. If number of parquet files is exceeded, run
OPTIMIZEcommand on the Delta table to reduce number of files. Notebooks will auto-optimize the Delta tables on creation. AlsoVACUUMthe Delta tables periodically to only kpee the necessary files/data.Can I use 'Publish to Web' report built on top of Direct Lake dataset?
No, since Direct Lake dataset requires SSO, Publish to web is not supported currently.
Is there any limitation on table names or column names?
In general, hive metastore doesn't support columns and table names with spaces in them. Plus, generally, column and table names are lowercase. After creating the Direct Lake dataset, you can change names in web modeling. Read my blog about this here.
Can I run DMVs on Direct Lake dataset?
Yes. Only certain DMVs can be used with XMLA read.
Can I create Direct Lake dataset using KQL database?
No
Can I use it in QSO enabled workspaces?
Yes, currently you have to sync the dataset manually using below PowerShell
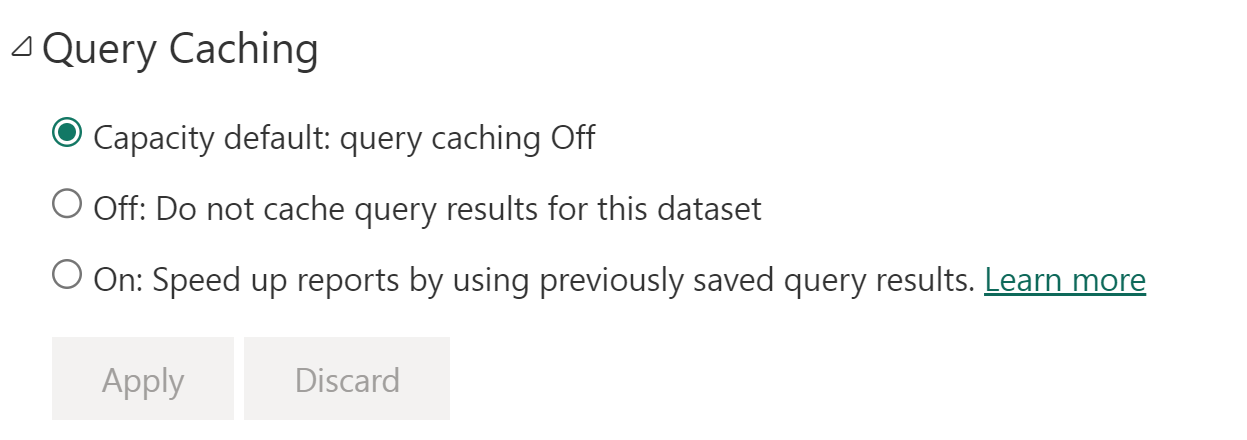
Login-PowerBI Invoke-PowerBIRestMethod -Url 'groups/WorkspaceId/datasets/DatasetId/sync' -Method Post | ConvertFrom-Json | Format-ListHow does Query Caching under dataset settings affect caching? Is that same as warm cache?
That's report level caching and may not be supported in the future for Direct Lake dataset because it won't be applicable in DQ mode.
I see Large dataset storage format setting in dataset settings, what does that do?
Not applicable to Direct Lake dataset.
Do I need to set up a gateway for Direct Lake dataset?
No gateways are needed since it's a cloud data source. May be needed for VNET situations but I am not sure.
Can I connect to a Direct Lake dataset which is in Workspace A and publish a report to Workspace B (Premium)?
Yes.
Can I connect to a Direct Lake dataset which is in Workspace A and publish a report to Workspace C (Pro)?
Yes, I think so. The only requirement is that Direct Lake must be in Fabric capacity. I will have to double-check this.
Do Direct Lake dataset haveon-demand loadlike other LDF datasets?
Yes, I talked about on-demand loading above.
Can I use streaming dataset with Direct Lake?
Not the Power BI streaming/push dataset. But you can certainly create structured streaming or use EventHub to create Delta tables which can be used for Direct Lake dataset.
Can I create perspectives?
I am not sure, but I doubt it.
Which Delta version is supported for Direct Lake?
I think only Delta < v2.2 are supported for now, but please check the official documentation.
If my data has a filter clause, let's say sum(sales) where year=2013, will it load data from the entire sales column from the Delta table or just for year 2013?
Since it is column based, the entire sales column will be loaded in memory and then FE will filter the data for year 2013.
Are hybrid tables supported?
No
Aggregation tables?
No
Auto date/time?
Direct Lake dataset does not create auto date/time tables
Dynamic M parameters?
No.
Does automatic page refresh (APR) work with Direct Lake?
Yes. To autorefresh the report in service, set the automatic page refresh so it shows the latest data, assuming the auto-sync in dataset has been tunred on.
Can I apply further transformations in the Direct Lake dataset?
Not after the Delta table has been created.
Can I create a view and use it in Direct Lake dataset?
No. Spark views are available yet. Views created in DWH cannot be used for Direct Lake either.
Can I query the Direct Lake dataset (or any other dataset) in the Notebook?
Using the REST API you can access the measures, semantic model. You can also query the Delta tables used in the dataset. Exciting things happening in this space, stay tuned.
Can I create an external dataset , i.e share it with external users ?
I am not sure, I will have to check.
Where does the data in Direct Lake reside, i.e any data residency implications?
It will be the same as the Fabric tenant geo-location. If you create a Delta table using shortcuts, it may leave the geography. Double-check that.
Does export to Excel work, similar to import?
Yes
Can I use Premium dataflow?
No. It has to be Dataflow Gen2.
If have an existing datamart can I create a Direct Lake dataset out of it ?
Yes. You will need to use the SQL endpoint of the datamart, copy the data using Dataflow Gen 2 to pipelines to create Delta table. So basically duplicate the data. Or use the same M code from the Datamart in Dataflow Gen2.
Does Log Analytics captures Direct Lake queries and activities?
I think so but I will check.
In PQ, I can group queries by creating folders to manage the queries. Can I create folders/sub-folders for the Delta tables?
No, folders are not supported.
If one of the tables has an error, will the framing happen for the rest of the tables or is it all or nothing?
I think it refreshes all or nothing, similar to import. I will test and update.
Why is the dataset size so small in the worskpace settings?
Because it shows the size of the metadata file, not the size in memory. To check the dataset/column size, use Vertipaq Analyzer.
Can I create Delta table using on prem data sources?
Yes, you can use Dataflow Gen 2 or pipelines.
Can Direct Lake dataset make use of parquet table/column statistics etc to speed up queries?
No
This all sounds good in theory. Does it really work in practice?
💡I have been using, creating and testing the Direct Lake datasets since private preview. It is fast, especially with the warm cache for massive datasets. Cold cache performance still has a lot of room for improvement. As we get closer to GA, I am 100% sure it will get far better. For most use case scenarios with ~25M rows and typical cardinality, best practices etc., users won't even notice any change in performance. Even for very large datasets, if you pre-warm the cache, the performance is very good. The biggest challenge is the RLS. For very large datasets like TPCH-SF100 (600M rows fact, multiple 20M rows Dims), it's impossible to import it into Desktop. Even if you do import it, creating relationships, measures, updates etc. slows down development in the Desktop. Direct Lake is essentially just metadata (like TE) which means there is no downtime and waiting. As soon as the Delta tables are created, you can create the model immediately and start building the report. It almost feels unreal for those massive datasets. The development workflow is another challenge. Since there are no calculated columns, calculated tables, parameters, incremental refresh etc., you have to re-think how to do that in the new world using pyspark and pipelines. Pay close attention to the Delta tables (#files, rowgroups, size etc.). Other than Direct Lake, I am most excited about being able to use Notebooks with Power BI datasets :) If you know me and have followed me, you may know that I use Python and notebooks in Power BI development so this is the best-integrated experience I can ask for. It opens so many options and avenues to develop new solutions using ML, advanced analytics, DataOps etc. Direct Lake may not be ideal in every single scenario, especially for citizen developers as there is some learning curve involved. We still don't know or understand a whole lot about this new mode, especially the Delta table maintenance, optimization and tuning best practices. It is still in Preview and you will run into issues/bugs so I don't recommend using it in production until GA. But truly an innovative feature. Kudos to the PG !

Thank you to Holly Kelly, Kay Unkroth, Tamas Polner, Akshai Mirchandani, Daniel Coelho, Eun Hee Kim, Justyna Lucznik, Bogdan Crivat, Jacob Knightley, Christian Wade from Microsoft for for all the information and my colleagues Simon Nuss and Bryan Campbell for support/testing.
Please refer to official Microsoft documentation for features, guidance and limitations. This product is in Preview and the features may change at any time.
Subscribe to my newsletter
Read articles from Sandeep Pawar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Sandeep Pawar
Sandeep Pawar
Microsoft MVP with expertise in data analytics, data science and generative AI using Microsoft data platform.