Mojo- A Python Competitor
 Tarushi Vishnoi
Tarushi Vishnoi
What is Mojo?
Mojo is a new programming language that was created by Chris Lattner and developed by Modular. It combines the usability of Python with the performance of C, unlocking the unparalleled programmability of AI hardware and the extensibility of AI models. Mojo is designed to be a superset of Python, which means that it can be used to write Python code, also you can use existing libraries and frameworks like NumPy, PyTorch, or TensorFlow with Mojo.
How can you learn and practice Mojo?
Mojo can be learned by setting up a Mojo Playground which is a web-based Jupyter IDE that allows you to write, run, and debug Mojo code. It might look like that we are running Python syntax, but it will run by the Modular engine which increases the rate by two, three, or four times and hence is responsible for Mojo's speed advantage.
Link to sign up for the Mojo Playground: https://www.modular.com/get-started
Link to the Documentation: https://docs.modular.com/mojo/
What makes Mojo faster than Python?
Unlike Python, Mojo provides better execution speed because of its underlying LLVM compiler. LLVM is an intermediate representation (IR) that can be used to represent code for a variety of different hardware platforms. This makes it possible to write a single compiler that can generate code for a wide range of CPUs, without having to write a separate compiler for each CPU.
How does Mojo solve the problem of Memory Latency?
Memory latency refers to the time delay or the amount of time it takes for a computer system to retrieve data from the memory. It is a measure of the time it takes for the processor to access or fetch data from the main memory, which is typically slower compared to the speed of the processor itself. To solve this problem, Mojo has come up with a solution for Floating Point.
The memory allocation is usually done in fixed-size blocks. Reducing the precision of floating-point numbers can lead to improved performance in terms of computation speed and memory usage. This is because lower precision requires fewer bits to represent the number, resulting in a smaller memory footprint and potentially faster arithmetic operations. Floating-point numbers themselves have fixed sizes but in Mojo we can decide our floating-point precision.
e.g., var x: F16 = 28
MatMul (Matrix Multiplication) in Mojo
MatMul is considered one of the biggest problems in the AI world. Mojo has solved this problem as it uses SMID. SIMD stands for "Single Instruction, Multiple Data." In SIMD processing, data is typically organized into vectors or SIMD registers, which can hold multiple data elements of the same type. The SIMD instructions specify operations to be performed on these vectors or registers, allowing for efficient parallel execution.
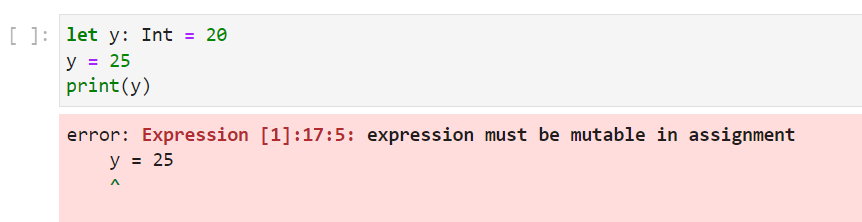
let and var declarations
Mojo supports let and var declarations, which introduce a new scoped runtime value: let is immutable and var is mutable.
e.g.,

Subscribe to my newsletter
Read articles from Tarushi Vishnoi directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Tarushi Vishnoi
Tarushi Vishnoi
Enthusiastic learner who loves to talk about emerging tech and creating software products.