Essential Statistical Inference Concepts for Data-Driven Decision Making
 Bella Eke
Bella EkeTable of contents

Introduction
In today's data-driven world, statistical inference plays a crucial role in extracting valuable insights from raw data. It enables us to make informed decisions, validate hypotheses, and draw conclusions about entire populations based on representative samples. If you're new to statistics or looking to refresh your knowledge, this beginner's guide will unravel the mysteries of statistical inference and equip you with the fundamental approaches to harness its power.
Understanding Statistical Inference: A Beginner's Guide
Statistical inference is a branch of statistics that involves making conclusions or predictions about populations based on sample data. It allows us to generalize findings from a subset of the data (the sample) to the entire population. By using appropriate statistical methods, we can make reliable inferences and gain meaningful insights.
Key Concepts in Statistical Inference for Beginners
Population and Sample:
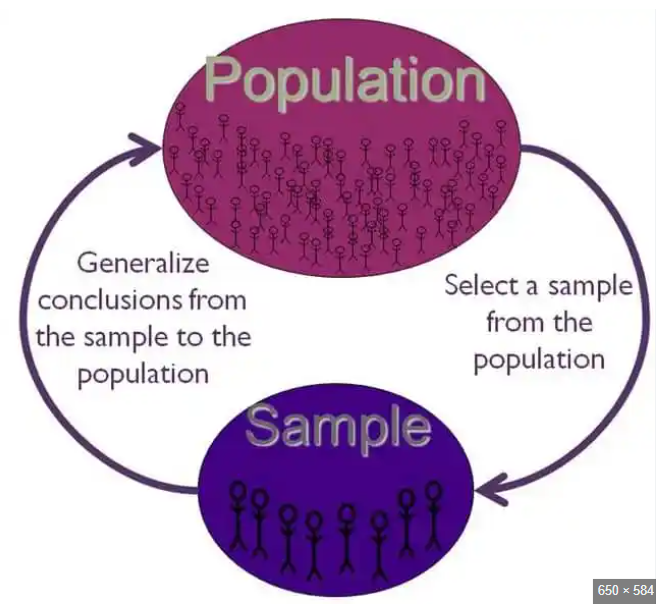
In statistical inference, we are interested in studying a larger group called the population. The population consists of all the individuals or objects that we want to draw conclusions about. However, it is often impractical or impossible to collect data from the entire population. Instead, we select a smaller subset from the population called a sample. A sample is a representative group that we collect data from to make inferences about the population.
Parameters and statistics:
Parameters and statistics are numerical characteristics that describe populations and samples, respectively. A parameter is a value that represents a specific attribute of the entire population. For example, the population mean is a parameter that represents the average value of a variable for the entire population. On the other hand, a statistic is a value calculated from the sample data. For example, the sample mean is a statistic that represents the average value of a variable within the sample. Statistics are used to estimate population parameters and make inferences about the population.
Sampling Distribution:
The sampling distribution refers to the distribution of a statistic, such as the sample mean, obtained from multiple random samples of the same size from a population. It helps us understand the variability and behavior of a statistic when repeatedly sampling from the population. The sampling distribution allows us to make probabilistic statements about how close our sample statistic is likely to be to the population parameter we are trying to estimate.
Confidence Intervals:
A confidence interval is a range of values within which we estimate that a population parameter lies. It provides a measure of uncertainty associated with our estimation. Confidence intervals are constructed based on the sample data and a chosen level of confidence. For example, a 95% confidence interval suggests that in repeated sampling, 95% of the intervals would contain the true population parameter.
Significance Levels and P-values:
In hypothesis testing, we compare the observed sample data against a null hypothesis, which represents the absence of an effect or relationship. The significance level, often denoted as alpha (α), is a predetermined threshold that determines the strength of evidence required to reject the null hypothesis. The p-value is a measure of evidence against the null hypothesis. It represents the probability of observing the sample data, or data more extreme, assuming that the null hypothesis is true. A small p-value (typically below the significance level) indicates strong evidence against the null hypothesis.
In real-world scenarios, the practical implementation of statistical inference principles can be observed and analyzed. For example:
A/B testing in marketing campaigns:
Companies often use statistical inference to determine the effectiveness of different marketing strategies. They may test two versions of an advertisement (A and B) and collect data on the response rates. By comparing the sample data and using hypothesis testing, they can infer which version is more effective for the target population.
Public health policy:
Researchers may use statistical inference to study the effects of an intervention on a population's health. For example, they might collect data on the prevalence of disease before and after implementing a vaccination program. Confidence intervals and hypothesis testing can help assess the program's impact and inform future policy decisions.
Financial forecasting:
Investment firms often rely on statistical inference to estimate future stock prices or market trends. By analyzing historical data and constructing confidence intervals, they can make informed decisions about their investment strategies and manage risk.
Understanding these essential concepts in statistical inference will equip you with a strong foundation for effectively exploring and analyzing data. By utilizing these principles, you can make well-informed decisions, estimate population parameters, and derive significant conclusions about the broader population using representative samples.
In conclusion, statistical inference is a powerful tool that enables us to make informed decisions and draw meaningful conclusions about populations based on sample data. By understanding key concepts such as population, sample, parameters, statistics, sampling distribution, confidence intervals, and significance levels, you can effectively analyze data and make reliable predictions. Furthermore, becoming familiar with frequentist and Bayesian methods, two major approaches within statistical inference, will allow you to tackle a wide range of data analysis tasks. Stay tuned for the next post, where we will dive deeper into these methods and demonstrate their implementation using Python code snippets.
Subscribe to my newsletter
Read articles from Bella Eke directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Bella Eke
Bella Eke
I am a data professional known for my unique visual perception skills. My passion lies in unraveling the mysteries of this groundbreaking field and making it accessible to all. I thrive on simplifying the most complex concepts for everyone's benefit. Through the hashtags #DataBytes, #DataPills, and #DataDose, I daily disseminate knowledge, offering bite-sized portions of data insights. My mission is to enhance data literacy, a social responsibility I embrace as a way of giving back to humanity. Join me on this journey towards a data-driven future.