Getting Started with Apache Storm: A Comprehensive Guide
 Elvis David
Elvis David
The need for real-time data streaming is growing exponentially due to the increase in real-time data. With streaming technologies leading the world of Big Data, it might be tough for users to choose the appropriate real-time streaming platform. Two of the most popular real-time technologies that might consider for opting are Apache Spark, Apache Storm and others.
In this article, we'll guide you through the process of getting started with Apache Storm and help you understand its core concepts and components.
What is Apache Storm?
Apache Storm is a distributed real-time computation system designed to process vast amounts of data streams in real-time. It was initially developed by Nathan Marz and his team at BackType, which was later acquired by Twitter. Storm became an Apache project in 2014 and has gained popularity due to its scalability, fault tolerance, and ability to process data in parallel across a cluster of machines.
Storm allows you to define data processing topologies, which are directed acyclic graphs (DAGs) that describe the flow of data and the transformations applied to it. These topologies can handle both simple and complex processing tasks and provide fault tolerance by ensuring that data is processed reliably even in the presence of failures.
Overview of Storm
Storm is a distributed and resilient real-time processing engine that originated from the efforts of Nathan Marz in late 2010 during his tenure at BackType. In his enlightening blog post on the history of Apache Storm and the lessons learned, Marz shares valuable insights into the challenges encountered during Storm's development (link to the blog: http://nathanmarz.com/blog/history-of-apache-storm-and-lessons-learned.html).
Initially, real-time processing involved pushing messages into a queue and subsequently reading and processing them one by one using languages like Python. However, this approach posed several challenges. Firstly, if the processing of a message failed, it had to be requeued for reprocessing. Secondly, maintaining the availability of queues and worker units for the continuous operation was demanding.
To overcome these hurdles and make Storm a highly reliable and real-time engine, Nathan Marz proposed two significant concepts:
Abstraction: Storm introduced a distributed abstraction in the form of streams. These streams could be produced and processed in parallel. Spouts, responsible for producing streams, and bolts, representing small units of processing within a stream, formed the core components. At the top level, a topology served as the overarching abstraction. The advantage of this abstraction was that users could focus solely on writing the business logic, without concerning themselves with the intricate internal workings, such as serialization/deserialization or message transmission between different processes.
Guaranteed Message Processing Algorithm: To ensure message processing reliability, Marz developed an algorithm based on random numbers and XOR operations. This algorithm efficiently tracked each spout tuple, regardless of the downstream processing triggered, requiring only approximately 20 bytes. This approach provided a solid foundation for reliable and efficient message processing.
After BackType's acquisition by Twitter in May 2011, Storm gained popularity in public forums and garnered the nickname "real-time Hadoop." In September 2011, Nathan Marz officially released Storm, followed by its proposal to the Apache Incubator in September 2013. Finally, in September 2014, Storm achieved the status of a top-level project within the Apache Software Foundation, solidifying its position as a powerful distributed real-time processing engine.
Storm architecture and its components
In this section, we'll discuss Storm architecture and how it works. The following figure depicts the Storm cluster:
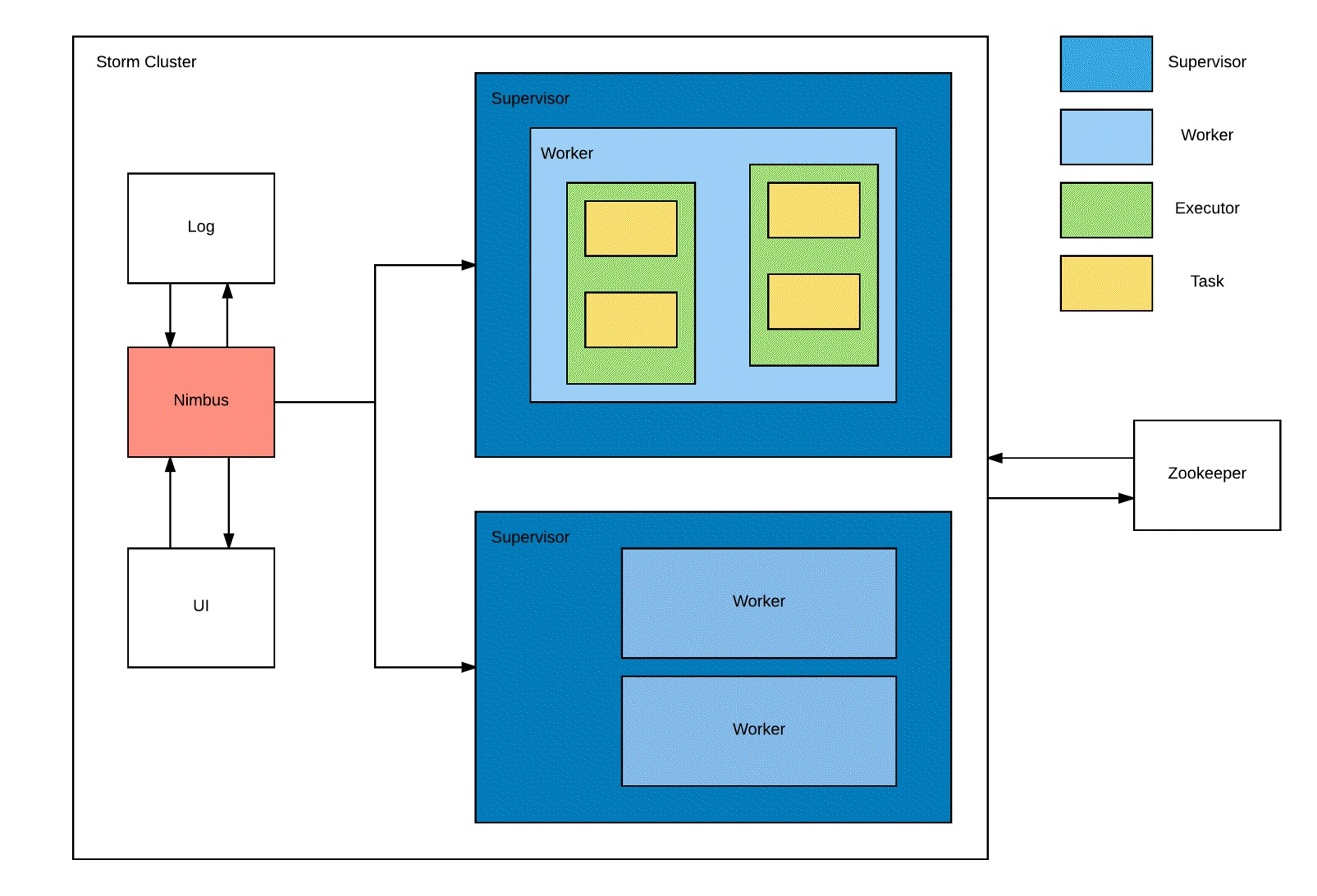
The Nimbus node assumes the role of the master node within a Storm cluster, playing a crucial role in topology analysis and task distribution among supervisors based on their availability. Additionally, it diligently monitors failures within the cluster, redistributing tasks among the remaining active supervisors if one of them becomes inactive. To maintain its state, the Nimbus node leverages ZooKeeper, utilizing it as a reliable mechanism for task tracking. In the event of a Nimbus node failure, it can be restarted, seamlessly resuming its operations by reading the state from ZooKeeper, thereby ensuring continuity from the point of failure.
Supervisors, on the other hand, function as slave nodes within the Storm cluster. Each supervisor node can accommodate one or more worker processes, represented by JVM instances. Acting as intermediaries, supervisors collaborate with workers to fulfil the assigned tasks originating from the Nimbus node. In the event of a worker process failure, supervisors efficiently identify available workers to resume and complete the pending tasks.
A worker process denotes a JVM instance executing within a supervisor node, comprising a set of executors. Within a worker process, there can be one or multiple executors responsible for coordinating and executing the assigned tasks.
Each executor, a singular thread process spawned by a worker, assumes the responsibility of executing one or more tasks, constituting a fundamental unit of work within the Storm cluster. These tasks actively engage in the processing of data, either as spouts (data sources) or bolts (data transformers).
In addition to the aforementioned components, two essential parts contribute to the functioning of a Storm cluster: logging and the Storm UI. The logviewer service, integrated into the Storm UI, facilitates effective debugging by providing access to logs pertaining to workers and supervisors. This invaluable resource aids in troubleshooting and monitoring the cluster's performance.
Components
The following are components of Storm:
Tuple - Serves as the fundamental data structure within the Storm framework. It possesses the capability to hold multiple values, with the flexibility to accommodate different data types for each value. By default, Storm serializes primitive value types, but if you have custom classes, it becomes necessary to provide a serializer and register it in Storm. Tuples offer convenient methods such as
getInteger,getString, andgetLong, which eliminates the need for manual casting of values contained within the tuple.Topology - Represents the highest level of abstraction within Storm. It encompasses the flow of processing, incorporating spouts and bolts. Essentially, it can be viewed as a graph computation, with nodes representing spouts and bolts, and edges denoting stream groupings that establish connections between them. The following diagram illustrates a simple example of a topology:
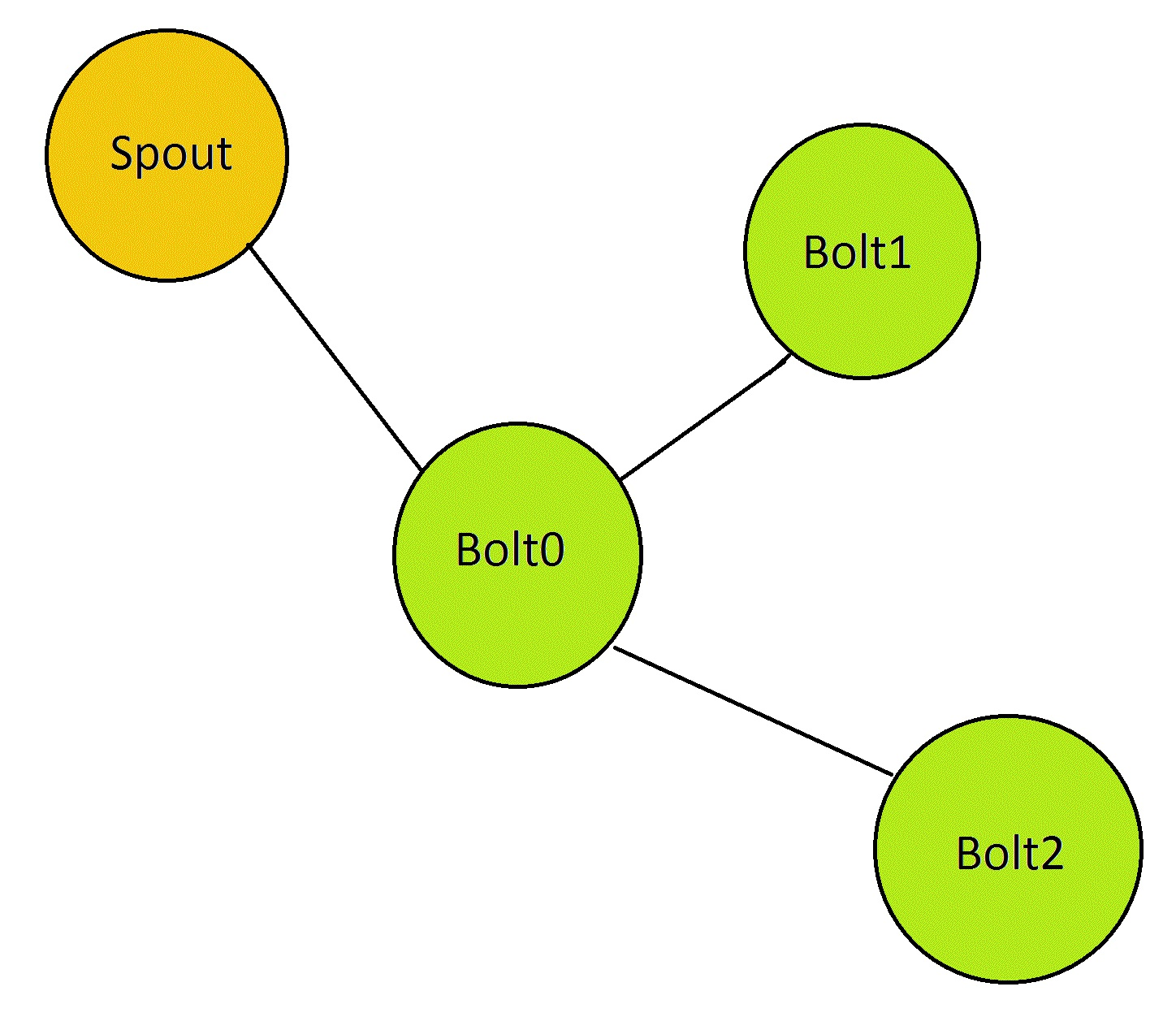
Stream - A stream forms the core abstraction in Storm, representing an unbounded sequence of tuples. Streams can be processed by various types of bolts, resulting in the generation of new streams. Each stream is assigned an ID, which can be defined explicitly by the user or defaults to the stream's default ID. The ID of a stream can be specified through the
OutputFieldDeclareclass.Spout - A spout serves as the source of a stream within Storm. It reads messages from external sources such as Kafka or RabbitMQ and emits them as tuples within a stream. A spout can produce multiple streams by defining the
declareStreammethod in theOutputFieldDeclareclass. There are two types of spouts:Reliable: A reliable spout keeps track of each tuple it emits and ensures that failed tuples are replayed for processing.
Unreliable: An unreliable spout does not maintain any record of emitted tuples once they are sent as streams to other bolts or spouts.
Spouts provide the following methods:
ack: This method is invoked when a tuple is successfully processed within the topology. The user should mark the tuple as processed or completed.fail: This method is called when a tuple fails to be processed successfully. The user should implement this method to handle the reprocessing of the tuple in thenextTuplemethod.nextTuple: This method is responsible for fetching the next tuple from the input source. The logic for reading from the input source should be implemented in this method and emitted as a tuple for further processing.open: This method is executed only once during the initialization of the spout. It is typically used to establish connections with input sources, configure memory caches, or perform other necessary setup operations. Once configured, these operations need not be repeated in thenextTuplemethod.
The IRichSpout interface in Storm provides the means to implement custom spouts, requiring the implementation of the aforementioned methods.
Bolt - A bolt represents a processing unit within Storm, responsible for various operations such as filtering, aggregations, joins, and database operations. It transforms input streams of tuples and generates zero or more output streams. It is also possible for the types or values within a tuple to change during processing. A bolt can emit multiple streams by utilizing the
declareStreammethod in theOutputFieldDeclareclass. It is important to note that subscribing to all streams simultaneously is not possible; each stream must be subscribed to individually.Bolts provide the following methods:
execute: This method is invoked for each tuple in an input stream that the bolt has subscribed to. Here, any required processing can be defined, including value transformations or persisting values in a database. Bolts must call theackmethod on theOutputCollectorfor every tuple they process, enabling Storm to track the completion of tuples.prepare: This method is executed only once during the initialization of a bolt. It is used to perform any necessary setup operations, such as establishing connections or initializing class variables.In Storm, there are two interfaces available for implementing the processing unit of a bolt:
IRichBolt: This interface provides advanced capabilities for implementing custom bolts. It requires the implementation of the execute and prepare methods, among others, allowing for more flexibility and control in the processing logic.IBasicBolt: This interface offers a simplified approach to implementing bolts by automatically acknowledging each tuple and providing basic filtering and simple functions. It is suitable for scenarios that do not require the advanced features provided by IRichBolt.
By choosing the appropriate interface, developers can tailor their bolt implementations to meet specific requirements and utilize the available features and capabilities provided by Storm.
Characteristics of Storm
The following are the important characteristics of Storm:
High Performance: According to Hortonworks, Storm sets an impressive benchmark by processing one million messages of 100 bytes per second per node. Its exceptional speed makes it a powerful choice for real-time data processing.
Reliability: Storm provides guarantees for message processing, ensuring that messages are processed either at least once or at most once, depending on the desired level of reliability.
Scalability: With its ability to handle a massive volume of messages per second, Storm offers remarkable scalability. By adding more supervisor nodes and increasing the parallelism of spouts and bolts within a topology, Storm can effectively scale to meet demanding processing requirements.
Fault Tolerance: Storm is designed to handle failures within the cluster. If a supervisor node becomes inactive, the Nimbus node redistributes the tasks to another available supervisor. Similarly, in the event of a worker failure, the supervisor reassigns the tasks to an alternative worker. This fault-tolerant approach applies to both executors and tasks, ensuring continuous processing even in the face of failures.
Language Agnostic: Storm allows flexibility in programming languages. Topologies can be written in any language, giving developers the freedom to choose the language that best suits their needs and preferences. This language-agnostic feature makes Storm accessible and adaptable to a wide range of programming ecosystems.
Stream grouping
The following are different types of grouping available with Storm:
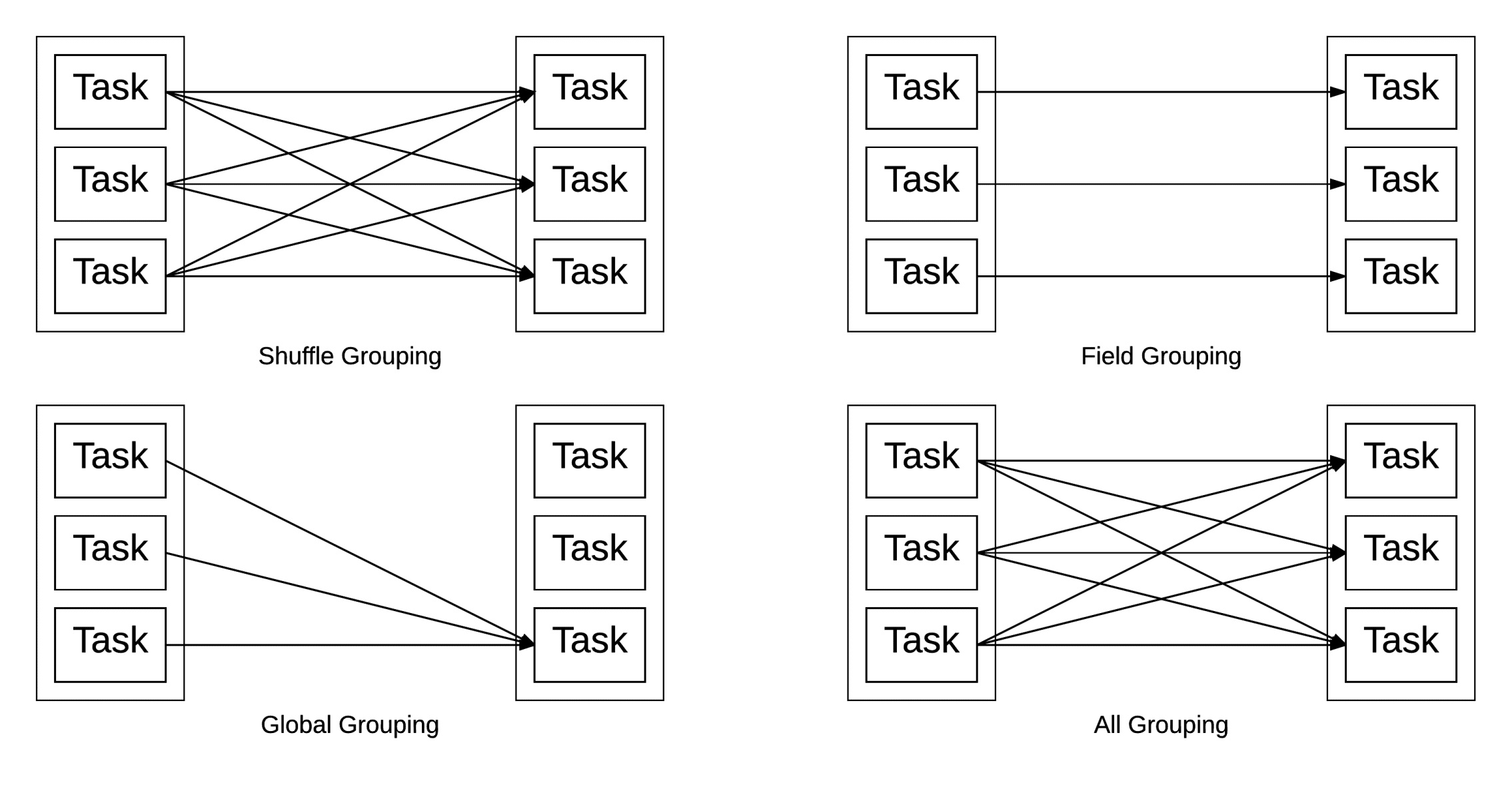
Shuffle Grouping: The shuffle grouping mechanism evenly distributes tuples across tasks, ensuring that an equal number of tuples are received by each task. This type of grouping is useful when you want to distribute the workload evenly among the tasks without any specific criteria.
Field Grouping: With field grouping, tuples are directed to the same bolt based on one or more specified fields. For instance, in a Twitter application, if you want to send all tweets from the same user to the same bolt for processing, you can utilize field grouping to achieve this behaviour.
All Grouping: In all grouping, all tuples are sent to all bolts within the topology. This type of grouping is particularly useful in operations such as filtering, where each bolt needs access to the complete set of tuples.
Global Grouping: Global grouping ensures that all tuples are sent to a single designated bolt. This type of grouping is commonly used in operations like reduce, where all tuples need to be processed by a single bolt for aggregation or summarization purposes.
Direct Grouping: With direct grouping, the producer of the tuple explicitly decides which specific consumer task should receive the tuple. However, this type of grouping is only applicable to streams that have been declared as direct streams.
Local or Shuffle Grouping: Local grouping occurs when the source and target bolts are running within the same worker process. In this case, data transmission does not require any network hops as the communication happens internally within the worker process. If the source and target bolts are not in the same worker process, the behaviour is equivalent to shuffle grouping.
Custom Grouping: Storm provides the flexibility to define custom groupings tailored to specific requirements. Developers can create their own grouping logic by implementing custom grouping methods and strategies. This allows for fine-grained control over how tuples are distributed among bolts within a topology.
Conclusion
In conclusion, we have discussed what is Apache Storm, its history, architecture, components and characteristics. We've also explored the various stream groupings supported by Storm.
In the next post, we will dive into setting and configuring Apache Storm. Keep watch!
Subscribe to my newsletter
Read articles from Elvis David directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Elvis David
Elvis David
Machine learning engineer and technical writer. Crafting innovative solutions and clear communication. 3 years of experience.