Web Scrapping IPL 2023 Player Data
 Puspender Kumar Yadav
Puspender Kumar Yadav
Cricket is one of my favorite sports(although I can’t play it to save my life). And since IPL 2023 has come to an end, I am sure millions of cricket fans would be interested in knowing which players were best this season.
For this article, I will only be carrying out only two tasks —
Finding all the players that have played 2023 IPL matches.
Finding all the player's information i.e. their batting and bowling stats.
Data Gathering Phase is a task that can take up to 70 to 80% of your total time dedicated to any project. For gathering data, I am going to use Web Scraping as all major cricket data is present on the web and we can easily access it through web scraping. HowStat is an excellent structured cricket statistics site that I will be using in this article. Another great option is espncricinfo.com.
Let’s start with the first task. For web scraping, we will need the following basic libraries which we will first import:
from bs4 import BeautifulSoup
import pandas as pd
import requests as rq
import numpy as np
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.chrome.options import Options
Next, we will write code for web scraping using Selenium and Beautiful Soup:
For the URL, I go to HowStat Website and decide to first take the data of the players who have player IPL 2023
Hence, the website URL is http://www.howstat.com/cricket/Statistics/IPL/PlayerList.asp. Go to this website link and press Ctrl+Shift+J to Inspect the HTML Code. Through this, you can understand the location of the needed data in the HTML code. This is important as we will scrap through HTML code. Next, since we only need data of the players that played in IPL 2023 we need to select the Season from the dropdown list.
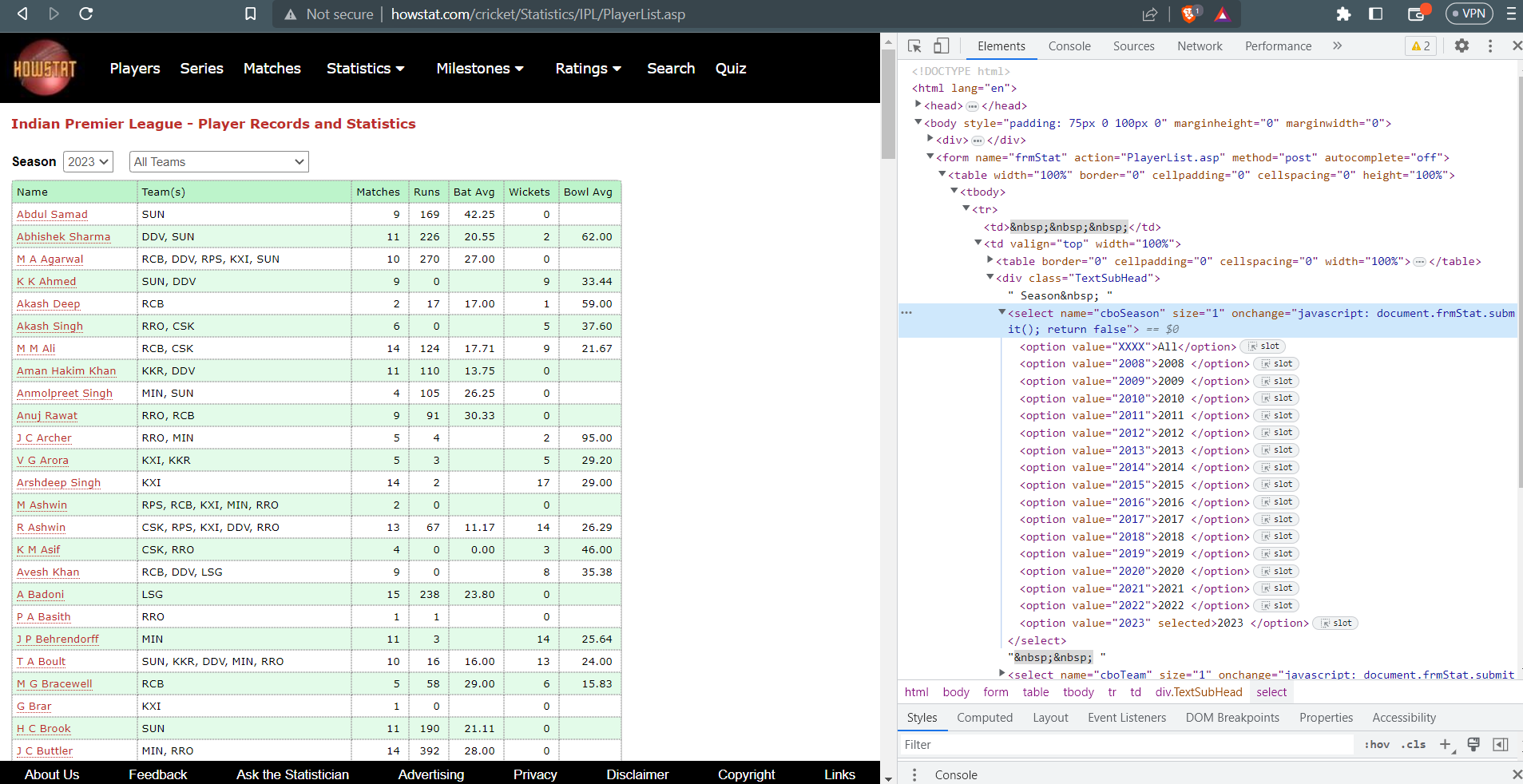
We will use the Select class from Selenium to interact with a drop-down list on the web page. It selects the 17th option (index 16) in the drop-down list. Here's the code for it -
driver = webdriver.Chrome()
url = "http://www.howstat.com/cricket/Statistics/IPL/PlayerList.asp"
driver.get(url)
select = Select(driver.find_element(By.NAME, "cboSeason"))
select.options[16].click()
The above action selects a specific season in the drop-down list, triggering a page reload with data related to the selected season.
Now we need to extract each player's data individually, to do so we can get all the player's individual stats page links through the <a> tag attached to the name.
For this, we need to see the table in HTML code and find the content of the class attribute so that our code can find it uniquely.
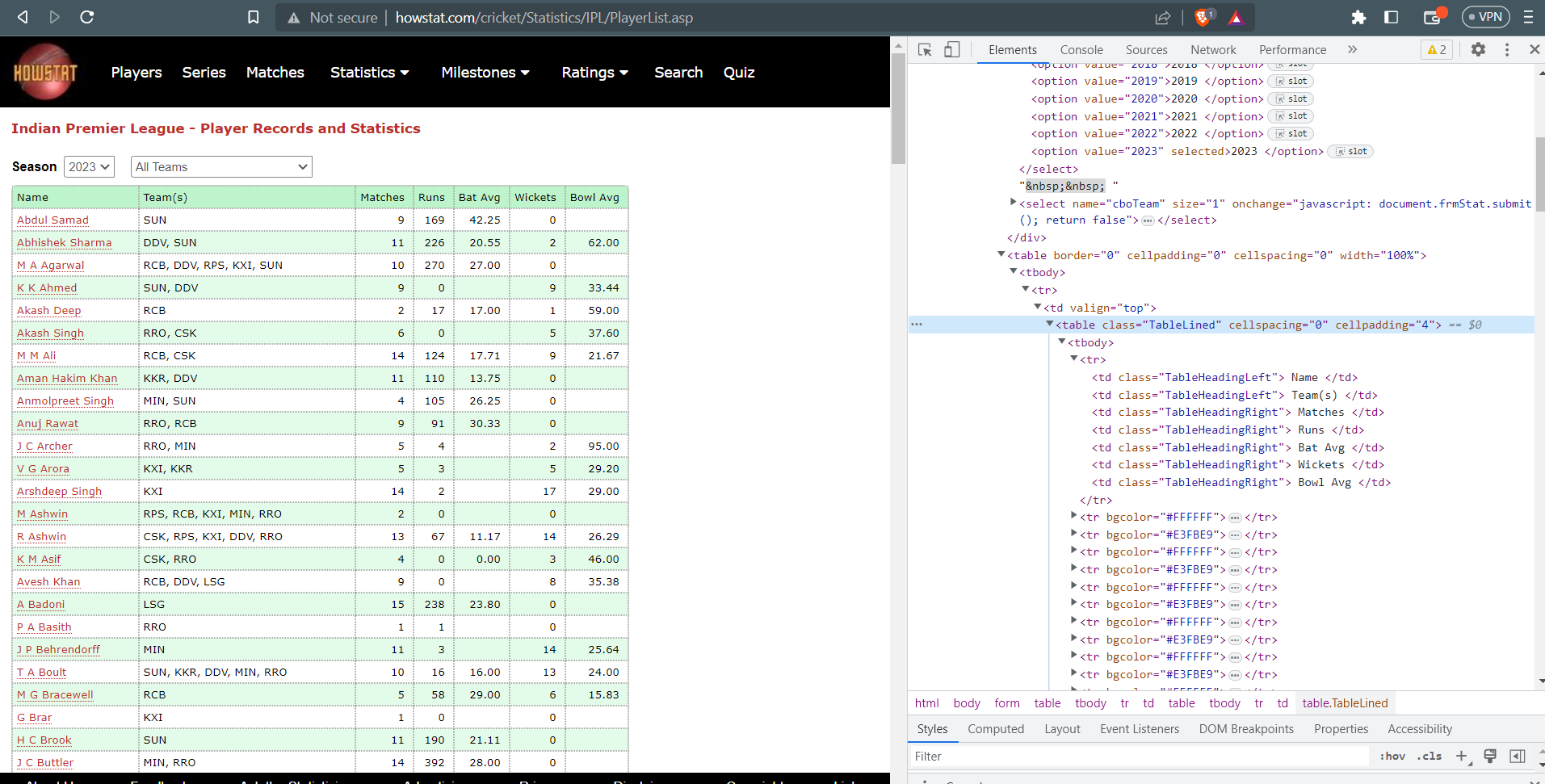
table.tablelined in the above picture shows that for the table tag we have class attribute value as TableLined. Now, we need to access the individual cell containing the name and other stats of the player.
The code would be -
table = soup.find("table",{"class":"TableLined"})
trs = table.find_all("tr")
After finding the table element using soup.find("table", {"class": "TableLined"}) and extracting all the rows from the table. Now we iterate over each row using a for loop. Within each row, we find the individual cells that contain player stats. Within each row, we find all <td> tags (table cells) using find_all("td"). The data from each cell is extracted and stripped of leading/trailing whitespace using text.strip(), and assigned to variables such as name, match, run, bat_avg, wicket, and bow_avg
Here's the code -
player_stat = defaultdict(def_value)
for i in range(1, len(trs)):
tds = trs[i].find_all("td")
name = tds[0].text.strip()
match = tds[2].text.strip()
run = tds[3].text.strip()
bat_avg = tds[4].text.strip()
wicket = tds[5].text.strip()
bow_avg = tds[6].text.strip()
player_stat = {"Name": name, "Matches": match, "Runs": run, "Batting Average": bat_avg, "Wicket": wicket, "Bowling Average": bow_avg}
data.append(player_stat)
Then, a dictionary named player_stat is created with the extracted data, using keys such as "Name", "Matches", "Runs", "Batting Average", "Wicket", and "Bowling Average". This dictionary represents the statistics of a single player.
The player_stat dictionary is then appended to the data list (which has been initialized earlier in the code) to store the statistics for all players.
Now the data is saved as a CSV file.
The complete code is available on my Gitub and the dataset file is available on my Kaggle.
In Part 2, I will solve the second problem i.e. Finding the best players of the season.
Subscribe to my newsletter
Read articles from Puspender Kumar Yadav directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by