Machine learning in online advertisement: data-driven attribution
 Kristina Fedorenko
Kristina Fedorenko
Data-driven attribution is a methodology used in online advertising to allocate credit to different interactions that contribute to a desired outcome, such as conversions. Attribution enables market players to have a big picture of what is going on to control their budgets and their partnerships. For publishers, it gives a clear idea of how much value each advertisement channel brings. For example, it can say things like “If I invest $X in promoting Booking.com on TripAdvisor, I would get $Y in return”. For platforms (e.g. Meta, which provides a platform for companies to post their ads) it would tell which impressions (ads shown on Instagram) lead to website X conversions. In this article, I am going to offer you an overview of several approaches to attribution.
Rule-Based Methods
Imagine there is a person who wants to book a holiday in Europe. First, they type a Google search prompt: “hotels in Paris” and click some ads displayed along with Google search results. But the person did not book anything because they wanted to double-check their trip dates first with their partner. Then this same person comes back two days later, types “booking.com” in their browser and books a hotel. From booking.com’s point of view, there were two entries for this user: Google search and direct. In this case, it makes sense to attribute the booking to a Google search channel. Such an attribution method is called First Click.
Let us take another example. A user prepares for their holiday in France. They searched for their destination on Google and landed on Booking.com. However, they did not book anything because they are still hesitant about whether to go to France at all. Two days later they came across a booking.com ad on TripAdvisor. This time they went through and booked accommodation. In this case, it makes sense to attribute the booking to TripAdvisor. Such an approach is called Last Click.
One can argue that in the second case, both channels contributed to user conversion. Well, we can assign half of the booking value to the search and the other half to TripAdvisor. This is called Uniform attribution.
All these approaches are rule-based: we have a certain rule on how to attribute bookings. But even the simplest examples we mentioned prove that rules alone cannot provide a one-size-fits-all solution. So we want to do better than using just one rule for attributing all conversions.
Data-Driven Attribution
Attribution based on the Markov chain
One of the possible approaches is to present the user journey as a graph where each node is a marketing channel. Eventually, the user journey ends up as a conversion or “no conversion”.
Here is how the second example from the article’s previous section would look like as a graph:

Based on all user journeys through marketing channels, we can make a probabilistic graph of transitions between each node, for example:
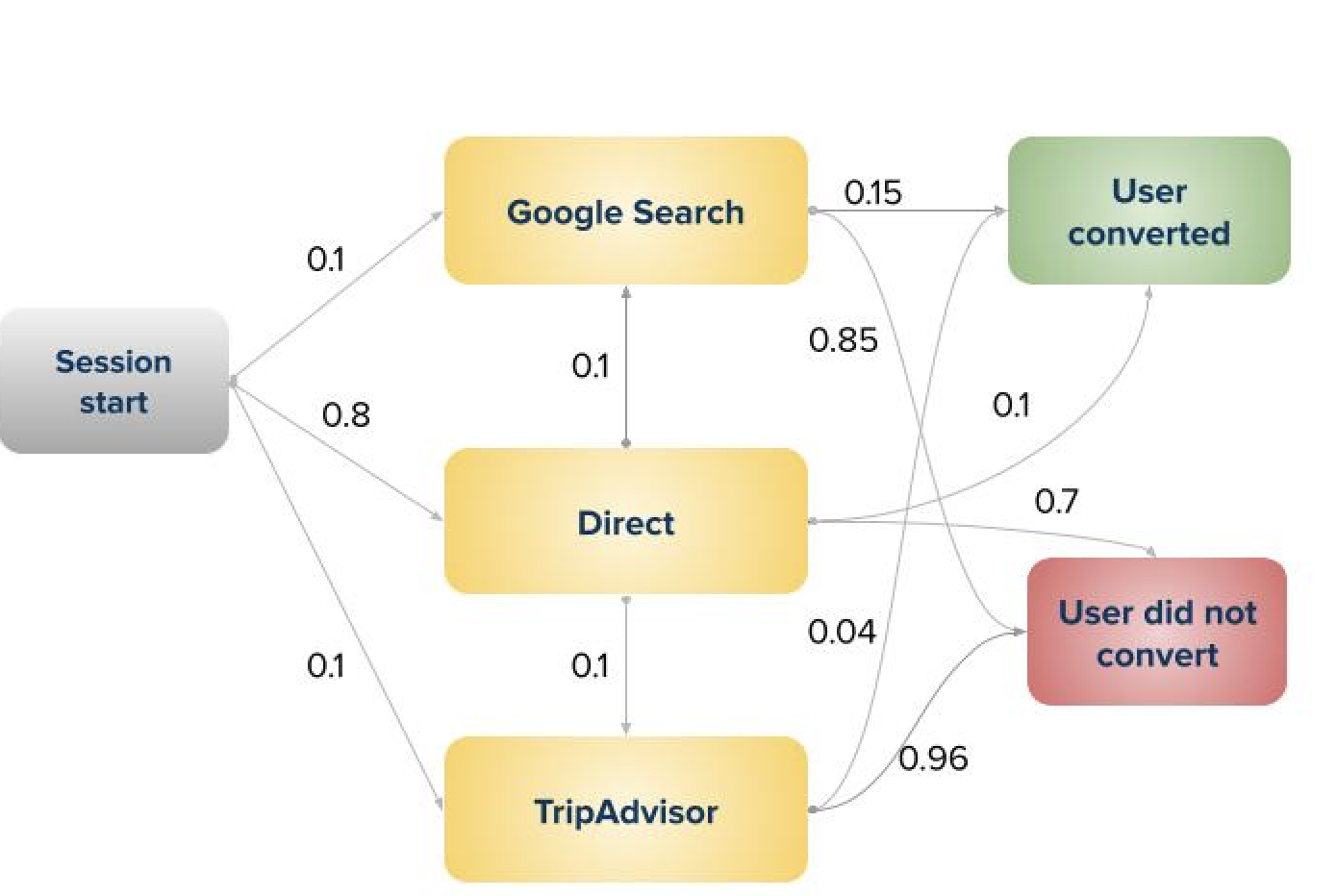
Once we represented the data this way, we can calculate various values for each node, such as:
the probability of hitting the conversion node
marginal increase in the probability of hitting conversion from the “begin” node b if we increase the weight of all edges outgoing from the node j by ε
value for each node i which is defined as the change in the probability of hitting conversion starting from the “begin” node b, if we remove node i from the graph.
We can choose to use one of the values or a combination of some or all of them as an attribution method. An efficient implementation of this approach is available through Apache Spark, part of the Hadoop ecosystem, an open source code framework for distributed processing of unstructured data.
You can find more about the Markov Adgraphs in this paper written by Nikolay Archak from New York University, Vahab S. Mirrokni and S. Muthukrishnan from Google Research.
Although this approach is great for visualizing, it becomes not feasible with the number of nodes increasing, as the graph size grows as N^2 with N being the number of channels. This problem makes it difficult to take into account sparse features of advertisement channels such as search words
Attribution based on logistic regression
This approach employs a simple logistic regression model to calculate the “importance” of each user touchpoint. The goal of the logistic regression model is to predict the probability of a conversion based on independent variables. We will use touchpoints as independent variables here and use weights learned by the logistic regression as the “importance” of each touchpoint. To make the results more stable we will sample data and train logistic regression M times. The final “importance” of a touch point is an average of estimated coefficients in M iterations.
More details about using logistic regression in advertising attribution can be found in a work by Xuhui Shao from Turn Inc., a data and media management platform provider, and Lexin Li of North Carolina State University. Practical tools for this method can be sourced at Vowpal Wabbit, an open-source library initially developed by Yahoo and currently supported by Microsoft.
The drawback of this approach is that it doesn’t take into account the sequential characteristics of the user journey. It also assumes that all touchpoints are independent one from another, which is not always true.
Attribution with Neural Networks
Neural networks can also be used for advertising attribution. The Long Short-Term Memory (LSTM) architecture can be particularly beneficial in this context as it allows for considering the entire user journey. Another advantage is that we can make touchpoints as granular as we want.
For instance, such an approach is described here by Ning Li from the University of Washington and a team of Adobe employees: Sai Kumar Arava, Chen Dong, Zhenyu Yan and Abhishek Pani. Authors train LSTM on all user journeys and predict whether or not they will end with a conversion. To determine the significance of each touchpoint in the conversion event, the authors introduce attention mechanisms. The attention weight is utilized as a measure of the credit assigned to the touchpoint
Conclusion
Attribution is an important part of many businesses and most of them use it in one way or another. We have examined the simplest rule-based approaches and their limitations, and briefly explored three alternative methods. Each of them has its advantages and disadvantages, so the choice depends on the specific requirements of a company. As a general guideline, if a quick and simple approach is preferred, sticking to the logistic regression model is recommended. If you need to consider more user journey peculiarities, employ Markov chains. LSTM and attention mechanisms are best for the most thorough solution.
####
Subscribe to my newsletter
Read articles from Kristina Fedorenko directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Kristina Fedorenko
Kristina Fedorenko
I am a machine learning engineer with 10+ years of experience. I have successfully led wide variety of ML projects such as detection of unprofessional images at IG&FB shops. Ads ranking models redesign in Meta. I have a master’s degree in Applied Mathematics and Computer Science from Saint Petersburg State University.