Conjoint and how to do it with open source tools
 Maria Plieva
Maria Plieva
As a researcher, I often want to try some new methods of research. In most cases, I find ready-made solutions on the market, but they are usually not cheap. Companies are not always willing to pay for research software right away for the sake of trying it out. This was a problem for me with Conjoint research.
Conjoint is a quantitative market research technique that aims to understand how individuals make decisions by evaluating their preferences for various attributes or features of a product, service, or concept. It helps researchers gain insights into the relative importance of different attributes and how they influence consumer choices and decision-making processes.
Conjoint is like a game where you have to choose the combination of product features that you like best.
This is how it looks for respondents:
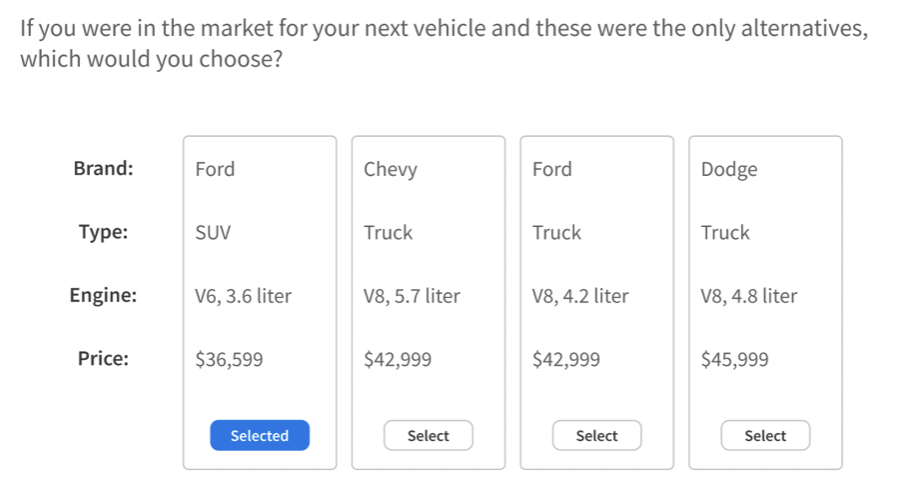
As a result of the study, we can obtain potential market shares for the new product and a rating of different characteristics by users.
The most popular ready-made solutions for Conjoint:
Sawtooth Software - covers all stages from design, programming to analysis and results.
Qualtrics Conjoint XM - again, covers all stages of research.
SPSS, SAS - in most cases, can be used only for analysis of results, not for full research setup.
R and Python - there are a number of libraries that are specifically created for conjoint (
conjointandsupport.CEsin R andpylogitandChoiceModelsin Python). So these libraries provide functionalities for designing and analyzing conjoint studies, but these options require some programming skills, of course.At first glance, the idea of using R or Python looks best as they are open source, however, this option lacks the actual interface for respondents to participate in the survey.
So...my idea was to do all possible stages of conjoint in R or Python and use the data collection platform only on the stage when the respondents fill in the questionnaire.
Steps of a typical conjoint
Coding conjoint research studies in R and Python typically involves designing the choice scenarios, collecting data, and analyzing the data using appropriate techniques. Here's a high-level overview of the steps involved:
Experimental Design: It's necessary to choose an experimental design that ensures an efficient and balanced representation of attribute combinations. Commonly used designs include full-factorial designs, fractional factorial designs, and orthogonal arrays. I use conjoint software packages like
AlgDesignin R orpyDOE2in Python to generate the design.Choice Scenario Generation: The next step is to use the experimental design to create choice scenarios by combining attribute levels. Each choice scenario should include a set of attributes and levels for respondents to evaluate. Ensure that the number of choice scenarios is manageable for respondents to complete without fatigue.
Data Collection: Next, we should implement the choice scenarios in a survey format using your preferred survey tool or programming language. Participants will be presented with the choice scenarios and asked to make their preferences known (e.g., rank, rate, or choose preferred options). For me, it was the hardest point, as it took me a long time to find handy software. I've found Limesurvey, and for now, it's the best option for me.
Data Analysis: The last and most pleasant step for me is to analyze the collected data using conjoint analysis techniques to estimate attribute importance and utility scores. Two common methods are traditional conjoint analysis (based on rating or ranking data) and choice-based conjoint analysis (based on choice data).
А couple of my code examples:
RStudio
# Assuming you have a data frame "conjoint_data" with columns representing attribute levels and respondent choices# Perform conjoint analysis using rating datalibrary(conjoint)result <- conjoint(conjoint_data, type = "rating")print(result)# Perform conjoint analysis using choice datalibrary(conjoint)result <- conjoint(conjoint_data, type = "choice")print(result)Python:
import pylogit# Assuming you have a data frame "conjoint_data" with columns representing attribute levels and respondent choices# Create a choice model objectmodel = pylogit.create_choice_model(data=conjoint_data, alt_id_col='Alternative_ID', obs_id_col='Observation_ID', choice_col='Choice')# Estimate the choice modelmodel.fit_mle()# Print model summaryprint(model.summary())These examples provide a basic starting point that I use regularly, and the specific implementation may vary depending on the package and analysis technique you choose.
I think the described steps are the best way to do conjoint if you don't have a budget for sophisticated software right now. So finally, I'd be happy to chat about experimental research and see you on LinkedIn.
Subscribe to my newsletter
Read articles from Maria Plieva directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Maria Plieva
Maria Plieva
I am a data science and research enthusiast with a passion for user behavior research. In love with nerdy survey methods.