Web Based Local First P2P Development with Holepunch's Ecosystem
 JITPOMI
JITPOMI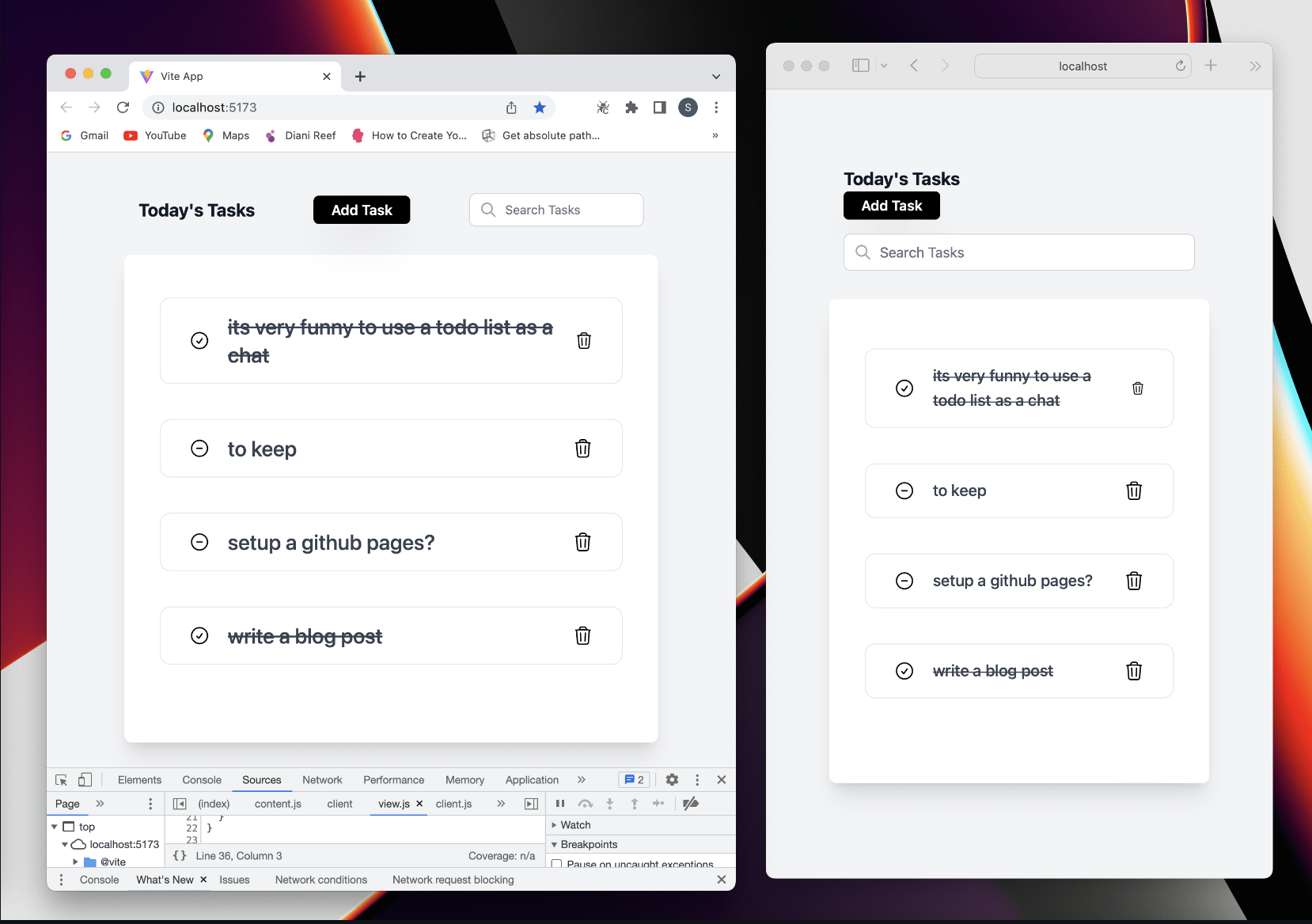
Memorial Day was bliss for our team, we found a ward into a dimension of software development we'd all thought was fictitious before - The World of Local-first P2P software development on the web. A world where your data is yours despite the cloud, a world of real collaboration, ownership and full availability of your data. We found Holepunch!
Holepunch is an app development platform that makes it easy to build, ship, and update fully P2P desktop/mobile/(even web) apps without using any cloud hosting servers. As you might have probably heard, working with Holepunch's tools in the browser is not common. Many believe it's impossible. Vih and I set out to debunk this when we built a demo to-do web app called hello-peers. You should clone it and run it (both the server and client) to see it in action!
How was it built?
I am happy to show you, but I strongly recommend that you check out the tech stack description in the GitHub repo. Here, I will take a precise approach to explain the demo's implementation and point out the specific semantics upon which the demo was built so you can follow it to build anything you want.
The Relay
Create a Hyperswarm DHT and add relay it over framed streams when a WebSocket connection is established. Your WebSocket implementation is up to you.
import Stream from '@hyperswarm/dht-relay/ws'; import { relay } from '@hyperswarm/dht-relay'; import DHT from 'hyperdht'; const dht = new DHT(); // .... websocket server implementaion => wss wss.on('connection', function (ws) { relay(dht, new Stream(false, ws)); })On the client side, grab the DHT from the WebSocket connection (whatever implementation) and create a HyperSDK to use for the rest of your hyper-core implementation on the client.
import DHT from '@hyperswarm/dht-relay'; import Stream from '@hyperswarm/dht-relay/ws'; import * as SDK from 'hyper-sdk'; const dht = new DHT(new Stream(true, socket)); const sdk = await SDK.create({ storage: false, // by choice we did not persist any data autoJoin: false, // we wanted fine control over peer discovery swarmOpts: { dht // passed the dht to the hyperswarm constructor } })And that's it. You got yourself a Hyper SDK that combines all the lower-level pieces of the Hyper stack into high-level APIs that you can use across platforms (web inclusive) and can now focus on your application's business logic.
The Discovery
Managing this is a choice we made when we turned autoJoin off on our SDK. Your use case may be different but if like us you asked for fine-grained control over peer discovery, here is how you would do it. Otherwise, just flip autoJoin to true.
There are several ways to discover nodes, you can do that by name, DNS, or a 32-byte buffer token. In our case, we used the later
//...
// @ts-ignore
import goodbye from 'graceful-goodbye';
// import * as BufferSource from 'buffer/'
import b4a from 'b4a';
// ... sdk generation code above
const topicBuffer = await crypto.subtle.digest('SHA-256', b4a.from('say a good hello', 'hex')).then(b4a.from);
// discovery here is a hypercore
const discovery = await sdk.get(topicBuffer);
discovery.on('peer-add', peerInfo => {
console.log('new peer, peer:', peerInfo, 'peer count:', discovery.peers.length);
});
// const db = await createMultiWriterDB(sdk, discovery)
// goodbye(async () => {
// await db.close()
// await discovery.close()
// await sdk.close()
// })
// const todoCollection = db.collection('todo')
// await todoCollection.createIndex(['text'])
// await todoCollection.createIndex(['done', 'text'])
// resolveReady()
//
// createWatcher()
sdk.joinCore(discovery).then(() => console.log('discovering'));
The Multi-Writer Hyperbee
A Hypercore is a secure, distributed append-only log built for sharing large datasets and streams of real-time data but we use the Hyperbee which is a b-tree running on a Hypercore and makes operations on it more efficient. Both Hypercore and Hyperbee can only have a single writer on a single machine; their creator is the only person who can modify it because they're the only ones with the private key, this is where Autobase comes in handy to transform these higher-level data structures into multi-writer data structures which facilitate two way features like collaboration.
For hello-peers, each peer needed an input and output core but since their roles are interlinked, we needed to remove the responsibility of managing custom storage/replication code from these independent higher-level modules so they are easier to manage so we used CoreStore; a Hypercore factory that makes it easier to manage large collections of named Hypercores and created an Autobase off that as you can see below:
import Autobase from 'autobase';
import Hyperbee from 'hyperbee'
// ....
export async function createMultiWriterDB (sdk, discoveryCore, { extPrefix, name } = defaultMultiWriterOpts) {
//Get back a namespaced Corestore instance
const IOCore = await sdk.namespace(name);
/*
UPGRADE:
No more there is no need to get the input and output cores
as autobase does that for you now.
const localInput = IOCore.get({ name: 'local-input' });
const localOutput = IOCore.get({ name: 'local-output' });
goodbye(async () => {
await Promise.all([localInput.close(), localOutput.close()]);
})
await Promise.all([localInput.ready(), localOutput.ready()]);
const autobase = new Autobase({ localInput, inputs: [localInput], localOutput })
*/
/*
If loading an existing Autobase then set bootstrap
to base.key (as second argument),otherwise pass bootstrap as null.
*/
const autobase = new Autobase(IOCore,null,{
apply: async (batch, view, base) => {
// Add .addWriter functionality
for (const node of batch) {
const op = node.value
if ('id' in op) {
console.log('\rAdding writer', op.key)
await base.addWriter(b4a.from(op.key, 'hex'))
}
}
// Pass through to Autobee's apply
await Autodeebee.apply(batch, view, base)
},
open: (store)=> {
const core = store.get(name)
return new Hyperbee(core, {
extension: false,
})
}
});
const localBee = new Autobee(autobase)
await localBee.ready() // multi-writer bee here
// ...
class Autobee {
constructor (autobase, opts = {}) {
this.autobase = autobase
this.opts = opts
/* UPGRADE: Needed here anymore - the view was created in Autobas'e open mthod
// use autobase to transform its hyperbees into multi-writer bee
if (!opts.sub) {
this.autobase.start({
unwrap: true, // this.bee.get calls will return full nodes
// The apply function to create the linearized Hypercore (this.bee)
apply: applyAutobeeBatch,
view: (core) =>
new Hyperbee(core.unwrap(), {
...this.opts,
extension: false
})
})
*/
this.bee = this.autobase.view
}
}
// MOVED: Into Autobee
// A real apply function would need to handle conflicts, beyond last-one-wins.
static async apply (batch, view) {
const b = view.batch({ update: false })
for (const node of batch) {
if('id' in node.value) continue;
const op = BSON.deserialize(node.value)
const bufKey = getKeyBufferWithPrefix(op.key.buffer || op.key, op.prefix.buffer || op.prefix)
if (op.type === 'put') {
await b.put(bufKey, op.value.buffer)
}
if (op.type === 'del') {
await b.del(bufKey)
}
}
await b.flush()
}
addInput (input, opts={indexer
: true}) {
const key = input.key;
return this.autobase.addWriter(key, opts)
}
removeInput (key) {
return this.autobase.removeWriter(key)
}
put (key, value, /*opts={}*/) {
const op = b4a.from(
BSON.serialize({ type: 'put', key, value, prefix: this.bee.prefix })
)
return this.autobase.append(op)
}
del (key, /*opts = {}*/ ) {
const op = b4a.from(
BSON.serialize({ type: 'del', key, prefix: this.bee.prefix })
)
return this.autobase.append(op)
}
// ... methods to manage the multi writer bee
}
/**
A linearized view is a "merged" view over the inputs giving you a way of interacting with the N input Hypercores as though it were a single, combined Hypercore.
*/
function getKeyBufferWithPrefix (key, prefix) {
return prefix ? b4a.concat([b4a.from(prefix), b4a.from(key)]) : b4a.from(key)
}
The Database
Hyperbee is super useful for storing data and searching for data using its ordered key search. When you set up your keyspace just right, you can query a small subset of a large database and quickly load what you need without having to download the entire dataset or traverse it. There is a module dedicated to explaining how to manually set up these indices for JSON data right but what is the reason for going with the manual process when there is a MongoDB-like database built on top of Hyperbee with support for indexing following the same design? We didn't have any so we just decided to use it. It's called Hyperbeedeebee. What a name! Anyway, you can look into the hello-peers repo to see how we use it through the app and or check out its documentation.
The Repo
To see the magic. Get a peer outside the network you are connected to and go to the hello-peers repo by clicking https://github.com/jermsam/hello-peers.
Clone the repo, install dependencies for both the server and client, run the server and the client and start collaborating.
We believe that you now have an understanding of how the pieces of Holepuch modules fit together and are ready to dive in and enjoy the excitement with the rest of us. For more information and discussion about Peer to Peer, let's hang out in the Holepunch discord servers. You can also check out our Personal Jitpomi Discord Server if you want to explore more exciting state-of-the-art technologies and maybe join our coding school (JSchool)
Subscribe to my newsletter
Read articles from JITPOMI directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
JITPOMI
JITPOMI
“We spice up your hustle!” At JITPOMI, we're all about empowering your grind through cutting-edge tech solutions — whether it’s in academia, trade, finance, media, or faith. We exist to make you better by helping you reach your business goals and exceed expectations through collaboration and co-creation.