The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
 Jordan Hsu
Jordan Hsu
paper link: https://arxiv.org/abs/1803.03635
Published in ICLR 2019
前景提要
樂透彩券的特性為一堆彩券中,真正中獎的只有那幾張,本文藉由樂透彩券來比喻神經網路的架構,真正對整體預測結果有關鍵影響的sub-network(中獎彩券)可能只有一小部分,其他的部分(沒中獎的)就可以prune掉,來加速模型的訓練時間和降低複雜度
本文方法
文章中對彩票假設的正式定義為:一個隨機初始化的密集神經網絡包含一個初始化的子網絡,在單獨訓練時,最多經過相同的迭代次數,可以達到和原始網絡一樣的測試準確率。
聽起來很文鄒鄒對吧,白話文理解就是你買樂透的時候,真正有價值的號碼是會中獎的號碼(目標sub-network),所以你會不會賺錢(測試準確度)是取決於那”目標sub-network”
那我們要怎麼找出會中獎的號碼呢?我們試著用形象化的方式來說明流程
首先,假設我們的場景是買大樂透,我們要在49個號碼(原始的複雜network)中選出6個會Fa Da Tsai💰的號碼(目標sub-network)
我們一開始隨便亂選(隨機初始化),這時的選擇策略(model)的weight稱為theta 0,比如我看38這數字不爽就比較不會選(負權重);看7這數字比較爽就比較會選(正權重)
開始課金try and error,從錯誤中學習,漸漸知道哪些號碼比較會中獎,並找一個有經驗的老師(mask)來判斷目前體悟到的選擇策略(model),哪些是影響結果的重點
有經驗的老師(mask)會prune掉不是重點的選擇策略(model),得到一精煉後的model
接著把此精煉後的model的weight改成mask內積theta 0,然後就可以得到最後的目標sub-network,theta 0這裡是為了讓精煉後的model weight正負號和初始訓練時一致
原文流程解釋如下:

為什麼保持正負號的一致會work呢?這也是這篇paper最innovative的點
在原paper中並沒有解釋得很清楚,另一篇paper《Deconstructing Lottery Tickets: Zeros, Signs, and the Supermask》裡面做了實驗來驗證這件事,如下
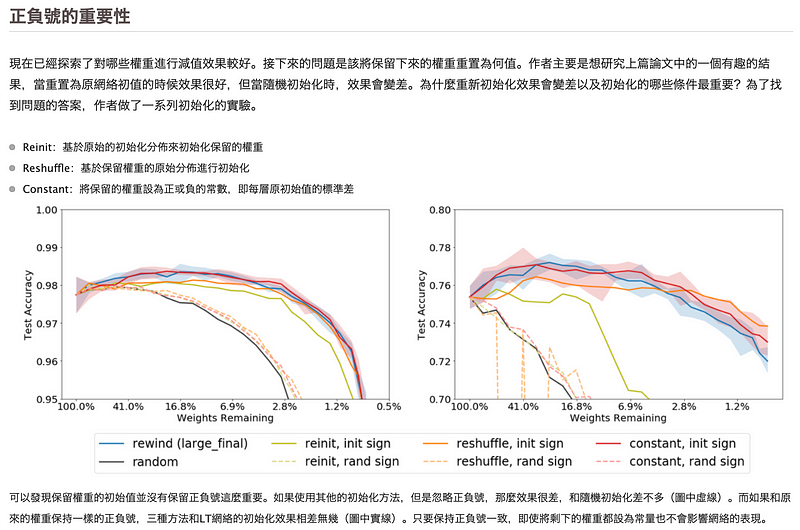
我的理解為,初始權重(theta 0)為一開始的投資策略,當中會有些策略是對的(比如買38比較不容易中),有些是錯的(比如買7其實也不容易中),所以需要一個身經百戰的老師(aka. mask)來幫忙判別你當初的投資策略哪些做對了or做錯了,那些在還沒有try and error就做對的結果就是我們要找的”對整體預測結果有關鍵影響的sub-network”,所以第四步的model weight才會是mask內積theta 0
實驗結果
經過大量prune的model(刪掉85%-95%的權重)與原model相比性能並沒有明顯的下降,而且,如果僅僅剪掉50%-90%的權重後的model性能往往還會高於原本的model。
另一方面,對於訓練好的普通model,如果重新隨機初始化權重然後再訓練,得到的結果往往會與之前的相當。但對於彩票假設的網絡並沒有這個特點,只有當網絡使用和原網絡一樣的初始化權重,才能很好地訓練,如果重新初始化會導致結果變差。mask(如果刪掉weight置0,否則為1)和權重的特定組合構成了中獎彩票。
詳細實驗的部分有興趣可以直接看paper,這邊只是提供一個理解整篇paper最tricky的部分的一個想法
And that’s a wrap! Enjoy. 🎆
👏
Subscribe to my newsletter
Read articles from Jordan Hsu directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Jordan Hsu
Jordan Hsu
Software Engineer with a Master's degree in Computer Science from Tsing Hua University, specializing in web development.