Adversarial Attack on Community Detection by Hiding Individuals
 Jordan Hsu
Jordan Hsu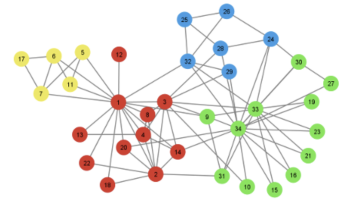
Published in KDD 2020
此篇為這issue的第一篇paper,故提出的方法實驗效果並沒有很好,只是題目新穎能帶來啟發
前言
Community detection (CD) 是什麼?簡單來說就是圖上nodes的聚類,同一類之間會比較dense,類跟類之間會比較sparse
每種顏色為同一類
Adversarial attack in CD是什麼?可以微調(perform small perturbations)圖的nodes、edges或features(例如增刪node, edge),來讓CD的演算法聚類的結果不同
如下圖,原本黃色類別的target nodes,在砍掉一條edge後,被同樣的CD演算法分為紫色類別了
攻擊這件事能幹嘛?舉個例子,電商上有許多商店,假設黃色類別代表評價差,紫色類別代表評價優良,透過攻擊電商的CD系統,我就能讓目標商店(target nodes)混入評價優良的類別,得到更多曝光率
註:在graph上,通常砍edge比加edge會有更多的影響,by 指導教授 in 清大資工
問題定義
給定一個CD演算法,要train一個生成adversarial graph的graph generator,目標是讓給定的一組target nodes 能分散地隱藏進不同的communities中,可以理解成要把一些身份特殊的人混入人群中,讓他們不被發現(如下圖)
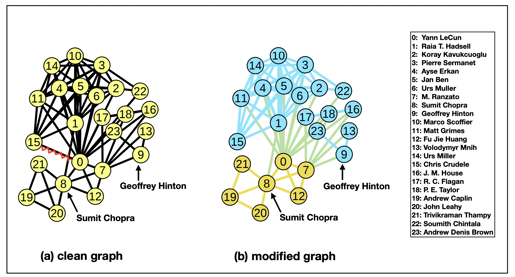
此paper的Intuitive example,原本node 8, 9是在同一類別,刪掉0跟15之間的edge後,node 8, 9就被歸類到不同communities了**(分散地隱藏)**
另外此篇paper簡化問題,生成adversarial graph時只考慮edges的增刪,並限制一個budgets,限制改變的數量(例如增刪加起來總共只能改變5條edges);另外 focus on non-overlapping communities,一個node只會屬於一個community
方法
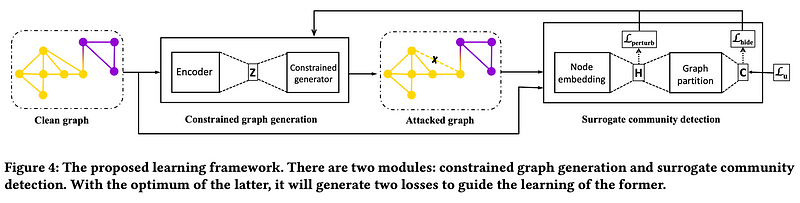
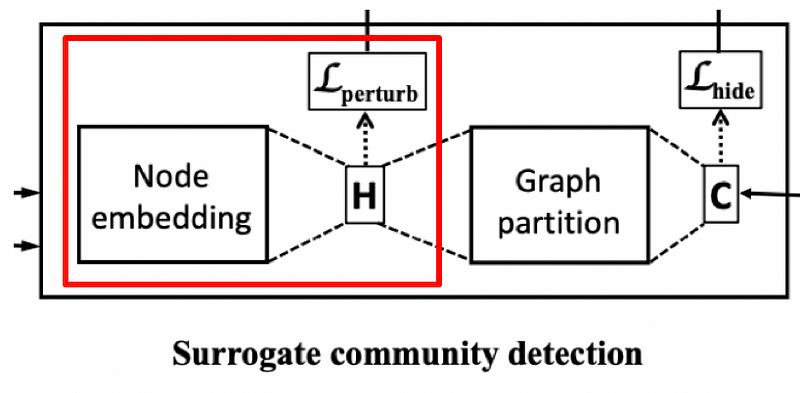
整體流程圖
整體分成兩個modules,為constrained graph generator跟surrogate community detector,constrained graph generator部分的輸入是乾淨的graph,輸出是改動過的攻擊graph,constrained的意思是能增刪的edges在一budget數目以下;surrogate community detector代表可替換的CD演算法,會藉由兩個loss指導generator生成的攻擊圖要符合兩個原則:
(1) 乾淨圖跟攻擊圖的每個node的embedding要相似(i.e. all node embedding之間的KL散度要低)
(2) target nodes之間要盡量被CD assign到不同的communities(i.e. target nodes之間預測屬於每個communities的機率的向量,兩兩KL散度要越大越好,代表兩兩不同target nodes的communities類別預測的機率分佈長得越不一樣、越不同類)
細節
● Surrogate community detection model
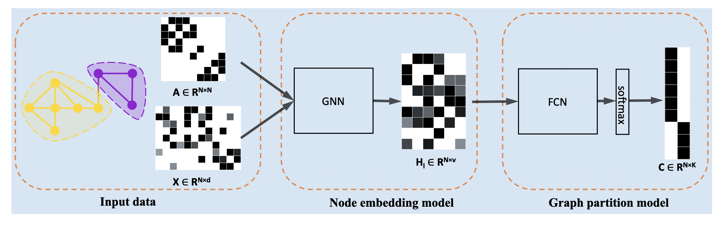
輸入一張graph,會經過兩個modules:node embedding module跟graph partition module,node embedding module在本篇透過GCN(local資訊)或Personalized PageRank(global資訊)來學出每個node的向量表示;graph partition module為Fully connected layer + softmax輸出每個node分別屬於K類的機率向量,當然,node embedding module跟graph partition module都是可以替換成不同方法的
這部分的loss為normalized cut,原則是want intra-group connections are denser than the inter-group ones, which mean lower numerator and higher denominator
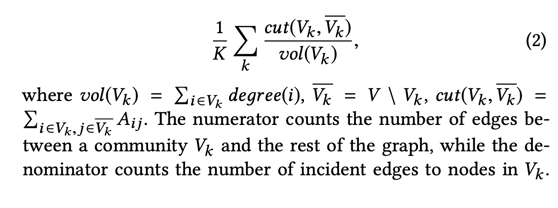
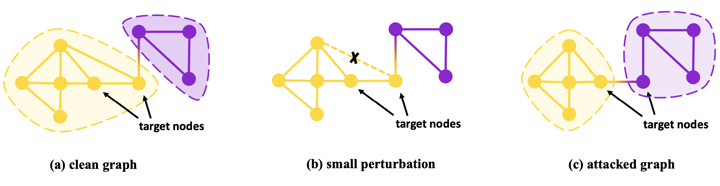
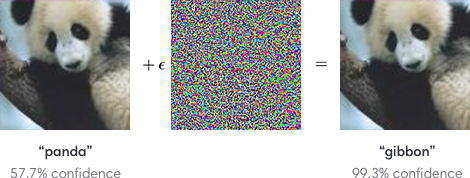
● Imperceptible perturbations
Adversarial attack很重要的事情是,改變前改變後不能太明顯,在image上的例子如下圖
但在graph上沒辦法透過視覺化直觀地判斷這個改變明不明顯,所以如何定義graph上的imperceptible perturbations還沒有一個標準套路,有人是透過比較圖本身的資訊來判斷(例如node degree distribution),而這篇是透過比較原圖跟攻擊圖學出來的node embedding,兩張圖每個點之間的node embedding的KL散度加起來越小越好
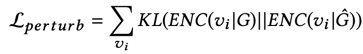
G為原圖;G hat為攻擊圖,ENC為encode的意思
● Constrained graph generation
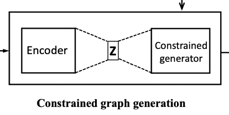
分成encoder part跟constrained generation part:,輸入為原graph,encoder part follow Variational Graph Auto-Encoder (VGAE)這篇paper的作法(目前graph generation上效果好的方法,參考下圖和reference [1], [2]),讓編碼出來的每個node的embedding服從標準高斯分佈

VGAE sample code
Encoder part的loss為:

Constrained generation part:
大原則就是,幫graph裡面的node兩兩算一個相似度分數,如果分數高代表這兩個node之間越可能有edge,依照分數排名,for large-scale graph,就刪掉原本有edge的node pairs裡,排名最後delta位的edges;for small-scale graph,刪掉原本有edge的node pairs裡,排名最後delta / 2位的edges,並新增原本沒有edge的node pairs裡,排名前面delta / 2位的edges

from 自製ppt
這邊的缺點就是實驗用的dataset都算很小的(如下圖),以及上述增刪edge的setting太naive,通常都不是optimal的解
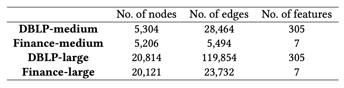
Experiments

from 自製ppt
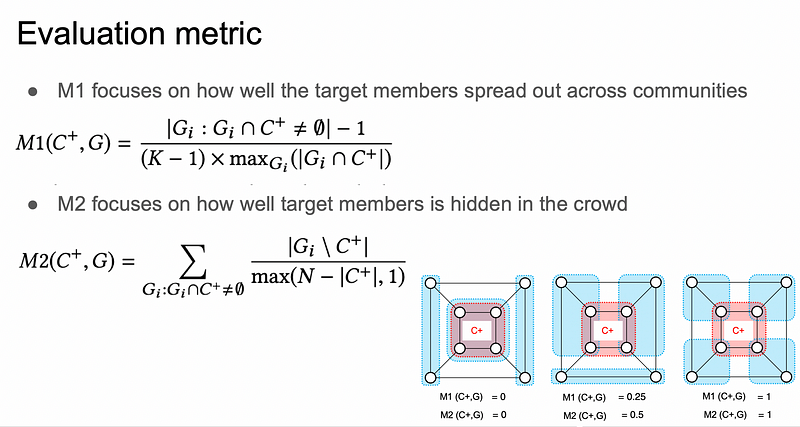
from 自製ppt
上圖中右下角的例子紅色部分的C+為target nodes們,藍色為communities
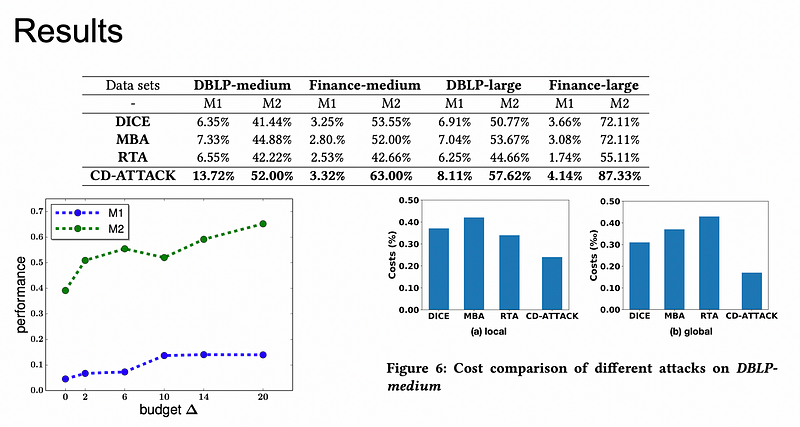
from 自製ppt
上圖的實驗結果可以看出這攻擊方法效果並沒有很好,M1的指標最高也才13.72%,而且budget的增加也不能帶來多少效果提升,甚至綠色線在10的地方還掉下去
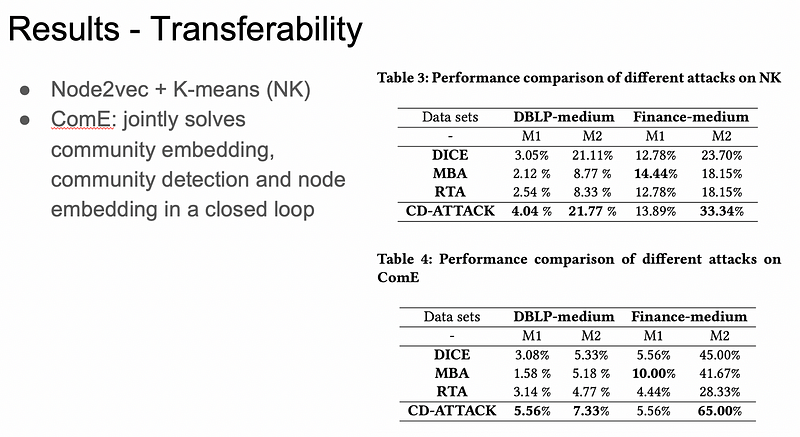
from 自製ppt
上圖的遷移實驗結果也可以看出這攻擊方法效果並沒有很好,M1的指標甚至還在Finance-medium被超過,其他的也沒跟baselines差多少
Rethink
○ 沒有做各個loss的ablation study,不知道各loss的重要程度跟必要性
○ Actor-Critic style的方法,critic部分難收斂,paper中也提到CD部分跟攻擊部分是分開train,但這樣就沒有互相學習的效果了
○ Only report the values of M1 and M2 rather than the gain/changes of these measures,只回報數值感覺跟CD部分用什麼model比較有關係,而不是攻擊的成效
○ 只要點子新穎,即使提出的方法效果再差,還是可以上top conference
And that’s a wrap! Enjoy. 🎆
👏
Reference
[1] https://zhuanlan.zhihu.com/p/78340397
[2] https://jjzhou012.github.io/blog/2020/01/19/GNN-Variational-graph-auto-encoders.html
[3] 自己 & 和指導教授討論過的理解
Subscribe to my newsletter
Read articles from Jordan Hsu directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Jordan Hsu
Jordan Hsu
Software Engineer with a Master's degree in Computer Science from Tsing Hua University, specializing in web development.