Columnar Databases & Compression
 Ahmad Ateya
Ahmad Ateya
Introduction
In the previous article, we delved into the world of database storage, specifically focusing on disk-oriented DBMS and how tuples are stored within pages using different approaches such as the Tuple Oriented Approach, Slotted Pages Approach, and the Log-Structured Approach. In this article, we will explore alternative methods for representing data to meet the needs of different workloads.
Database Workloads
First of all, what do mean by database workload?
In the context of database systems, workload refers to the set of activities and tasks performed by the database system. It encompasses the queries, transactions, data updates, and other operations that are executed against the database. The workload can include a variety of factors such as the type and complexity of queries, the frequency and volume of data access, the number of concurrent users, and the overall system demand.
In general, we categorize the workloads into 3 main categories:
1. OLTP: Online Transaction Processing
An OLTP (Online Transaction Processing) workload refers to a type of database usage that involves quick and short operations. These operations typically consist of simple queries that work with individual pieces of data at a time. In an OLTP workload, there are usually more updates or changes (writes) to the data than there are requests to retrieve the data (reads).
A prime example of an OLTP workload is an online storefront like Amazon. Users can perform actions such as adding items to their cart and making purchases, but these actions only impact their personal account and do not have a wide-ranging effect on the system or other users.
OLTP workloads are commonly the first type of applications that developers build, as they focus on managing individual transactions and providing real-time interactions with users.
2. OLAP: Online Analytical Processing
An OLAP (Online Analytical Processing) workload refers to a type of database usage that involves performing lengthy and complex queries. These queries typically involve reading and analyzing large amounts of data from the database.
In an OLAP workload, the database system focuses on analyzing and deriving new insights from the existing data collected through OLTP (Online Transaction Processing) operations.
To illustrate this, consider an example where Amazon wants to determine the most purchased item in Saudi Arabia on a sunny day. This analysis requires processing a significant amount of data and deriving meaningful information from it.
OLAP workloads are typically executed on the data that has been collected and stored from OLTP applications. By analyzing this data, businesses can gain valuable insights and make informed decisions based on trends and patterns discovered in the data.
3. HTAP: Hybrid Transaction + Analytical Processing
HTAP (Hybrid Transactional/Analytical Processing) is a relatively recent type of workload. HTAP aims to combine the capabilities of both OLTP and OLAP workloads within the same database system.
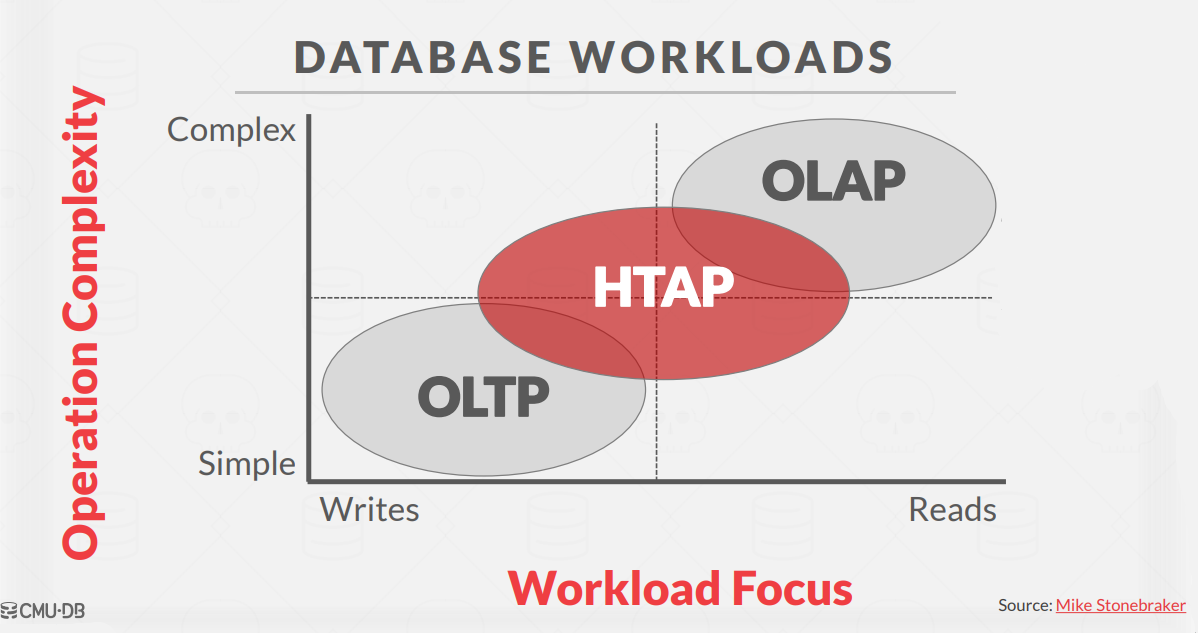
For this article, we are going to focus on OLAP workload, and how storing data on column-based can be so helpful for OLAP workloads.
Row vs Column Oriented Databases
Let's consider an example using the Wikipedia database to understand the problem at hand.
This article assumes that you can read and understand SQL queries.
Consider this is the schema for the Wikipedia database:
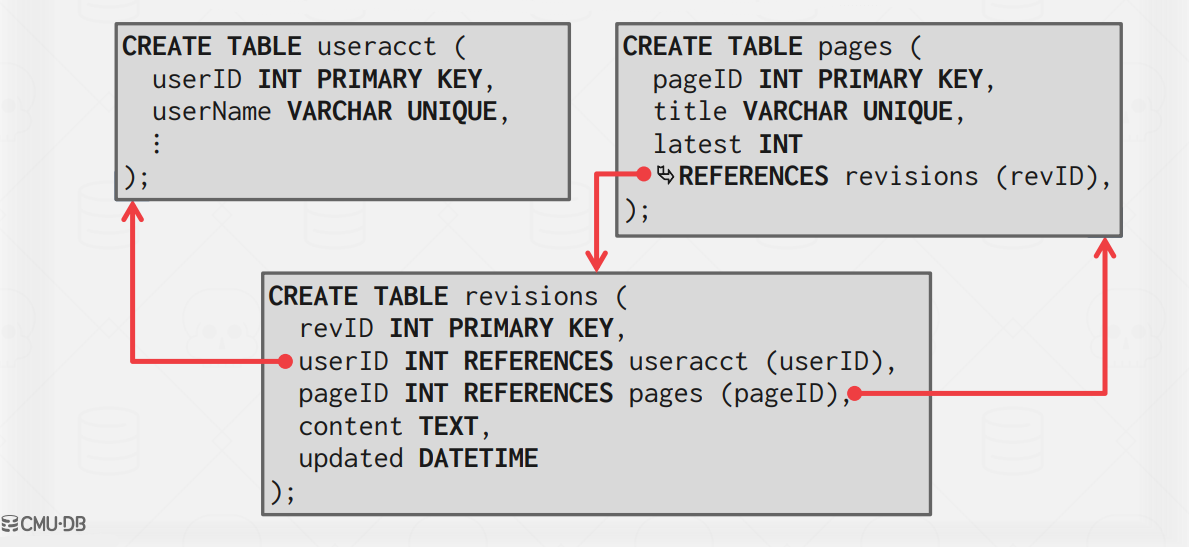
And these are the example queries as OLTP and OLAP workload.
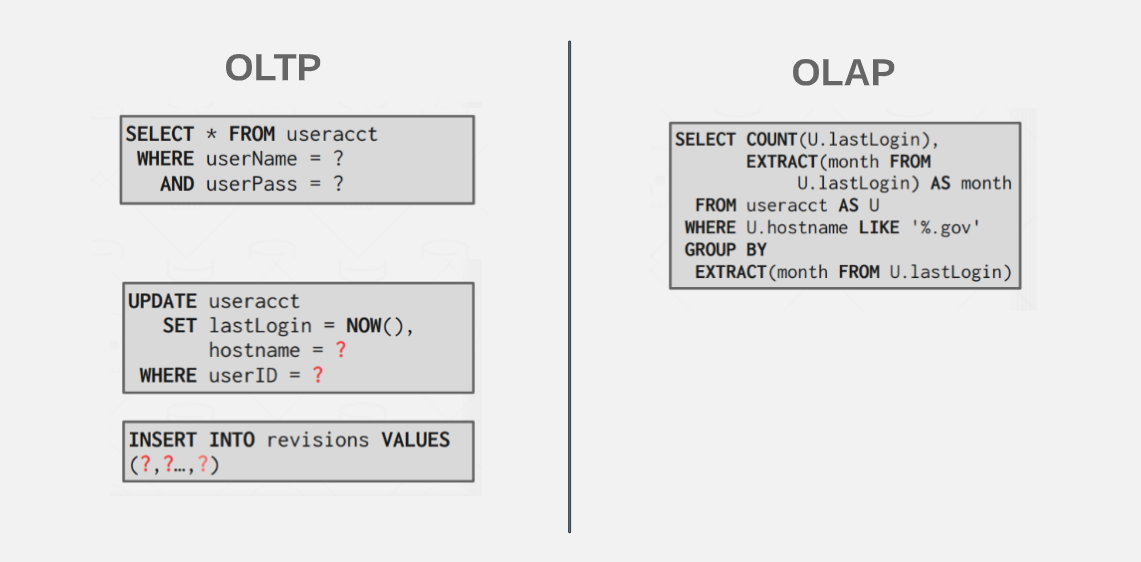
On the left side, we have everyday queries used in regular projects (OLTP workload). They are fast and simple, focusing on individual data entries.
On the right side, we have an example of complex queries used for analyzing big databases (OLAP workload). These queries provide insights by analyzing and summarizing data across multiple dimensions.
In the traditional way of organizing data ( row-based ), the data will be stored contiguously like this.
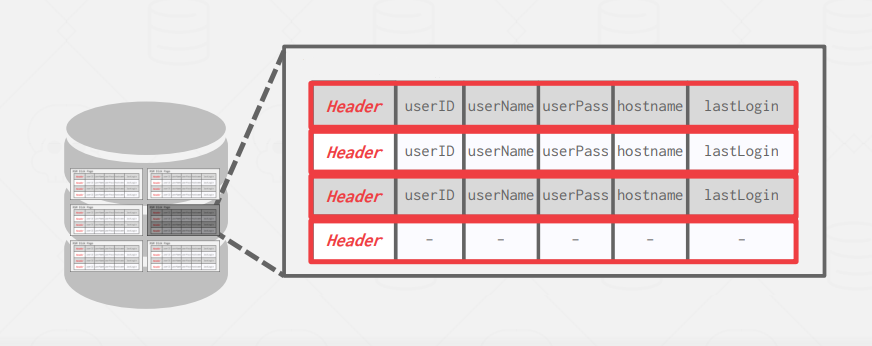
When executing the first query ( OLTP ), The DBMS ( specifically the Buffer Pool manager ) will retrieve the page containing the requested data from the disk and load it into memory.

Now this is fairly efficient as when we need one record from a page we get it ( or get the page that contains it ) without loading unneeded pages to memory, this is optimizing memory usage and improves performance.
However, when executing an OLAP query, the inefficiency of loading useless data to memory arises.

Now, it's important to remember that OLAP queries may operate on all of the database pages. With row-based storage, this means that the memory will be filled with useless data, consuming valuable resources.
Let's explore the other type for tuple storage and see how it is going to affect the query execution
The idea behind column-based databases is to store the values of a single attribute across multiple tuples contiguously on a page.
So the page only contains values for one field.
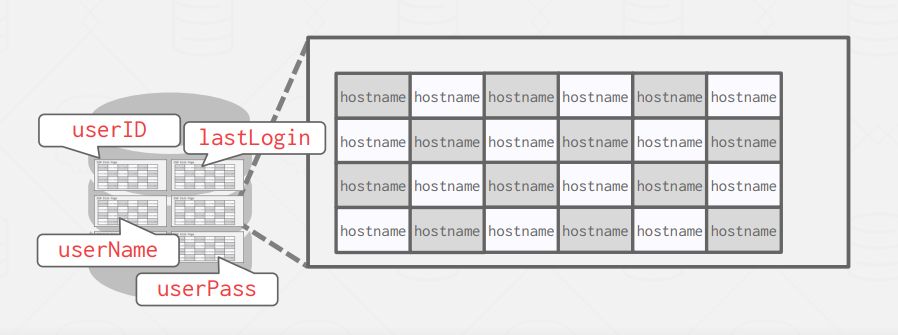
With this approach when we are trying to execute this query it will potentially need to load only two pages to memory the lastLogin field page and the hostname field page. This means a huge optimization in terms of I/O operations and memory consumption.
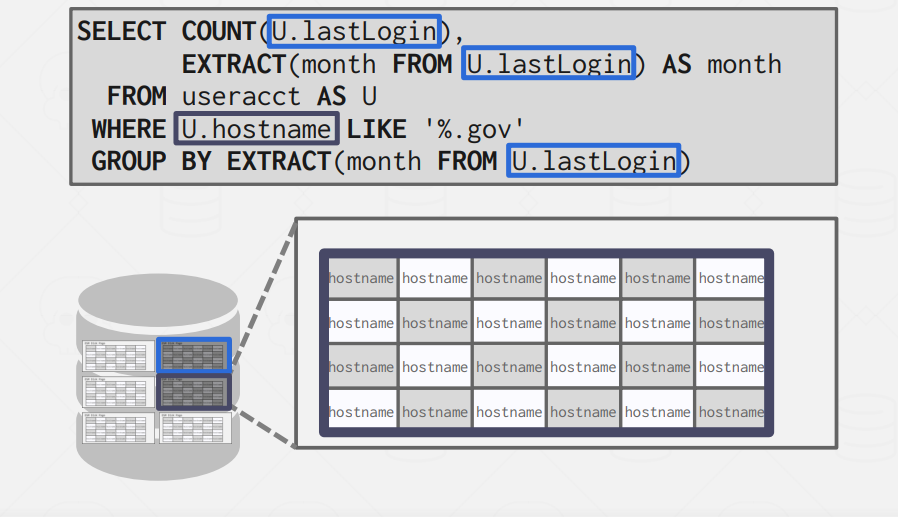
The choice between row-based and column-based storage models can greatly impact performance due to the difference in the number of I/O operations. Storing data in a column-based format allows for selective access to specific columns, reducing the amount of data read and improving query performance, especially for complex queries in OLAP workloads.
Now, let's summarize the key distinctions and characteristics of row-based and column-based storage models.
Storage Models
We have two main ways of tuple storage:
NSM, N-ary Storage Model. (AKA Row-based Storage)
DSM, Decomposition Storage Model. (AKA Column-based Storage)
NSM, n-ary storage model (Row-based Storage)
In the n-ary storage model, the DBMS stores all of the attributes for a single tuple contiguously on a single page. This approach is ideal for OLTP workloads where requests are insert-heavy and transactions tend to operate only as an individual entity. It is ideal because it takes only one fetch to be able to get all of the attributes for a single tuple.
Advantages:
Fast inserts, updates, and deletes.
Good for queries that need the entire tuple.
Disadvantages:
- Not good for scanning large portions of the table and/or a subset of the attributes
DSM, Decomposition Storage Model. (Column-based Storage)
In the decomposition storage model, the DBMS stores a single attribute (column) for all tuples contiguously in a block of data. Thus, it is also known as a “column store.” This model is ideal for OLAP workloads with many read-only queries that perform large scans over a subset of the table’s attributes.
Advantages:
Reduces the amount of I/O wasted because the DBMS only reads the data that it needs for that query.
Better query processing and data compression
Disadvantages:
- Slow for point queries, inserts, updates, and deletes because of tuple splitting/stitching.
Compression
Compression is widely used in disk-based DBMSs. Because disk I/O is (almost) always the main bottleneck. Therefore, compression in these systems improves performance, especially in read-only analytical workloads (OLAP).
The DBMS can fetch more useful tuples if they have been compressed beforehand but with a cost of greater computational overhead for compression and decompression.
In-memory DBMSs are more complicated since they do not have to fetch data from disk to execute a query.
Memory is much faster than disks, but compressing the database reduces DRAM requirements and processing.
They have to strike a balance between speed vs. compression ratio.
Compressing the database reduces DRAM requirements. It may decrease CPU costs during query execution.
Real-world Data Characteristics
If data sets are completely random bits, there would be no way to perform compression. However, there are key properties of real-world data sets that are amenable to compression:
- Attribute values in data sets often exhibit significant imbalances or
skeweddistributions.
One example of highly skewed distributions in attribute values is the popularity of movies in a streaming service. The majority of movies may have a relatively low number of views, while only a small percentage of movies may have an extremely high number of views.
This feature can ease the compression process by extracting the highly repeated values in some dictionary and replacing them with some smaller values (Like in dictionary compression).
- Data sets tend to have high
correlationbetween attributes of the same tuple.
Example of this is Zip Code to City or Order Date to Ship Date.
Compression Goals
We want a database compression scheme to have the following properties:
1. Must produce fixed-length values.
This is because the DBMS should follow word alignment and be able to access data using offsets.
2. Allow the DBMS to postpone decompression as long as possible during query execution (known as late materialization).
3. Must be a lossless scheme.
Any kind of lossy compression has to be performed at the application level.
Compression Granularity
Before implementing compression in a DBMS, it is important to determine the type of data that needs to be compressed. This decision dictates the available compression schemes. Generally, there are four levels of compression granularity:
Page-level compression: This level of compression operates on entire pages of data within the database. It treats each page as a unit and applies compression algorithms to reduce the overall size of the page.
Block-level compression: At this level, compression is applied to smaller blocks of data within a page. These blocks can vary in size and typically contain multiple tuples or records. By compressing data at the block level, further space savings can be achieved.
Tuple-level compression: Here, compression is applied individually to each tuple or record within a block. This allows for more fine-grained compression, as different tuples may have varying characteristics and compressibility.
Attribute-level compression: The most granular level of compression, attribute-level compression, focuses on compressing individual attributes or columns within tuples. This allows for maximum flexibility in terms of compression algorithms and efficiency, as each attribute can be compressed independently based on its specific characteristics.
Naive Compression
The DBMS compresses data using a general-purpose algorithm (e.g., gzip, LZO, LZ4, Snappy, Brotli, Oracle OZIP, Zstd).
Although there are several compression algorithms that the DBMS could use, engineers often choose ones that often provide lower compression ratio in exchange for faster compress/decompress.
An example of using naive compression is MySQL InnoDB. The DBMS compresses disk pages, and pad them to a power of two KBs and stored them in the buffer pool.
However, every time the DBMS tries to read data, the compressed data in the buffer pool has to be decompressed.
Since accessing data requires decompression of compressed data, this limits the scope of the compression scheme.
If the goal is to compress the entire table into one giant block, using naive compression schemes would be impossible since the whole table needs to be compressed/decompressed for every access.
Therefore, MySQL breaks the table into smaller chunks since the compression scope is limited.
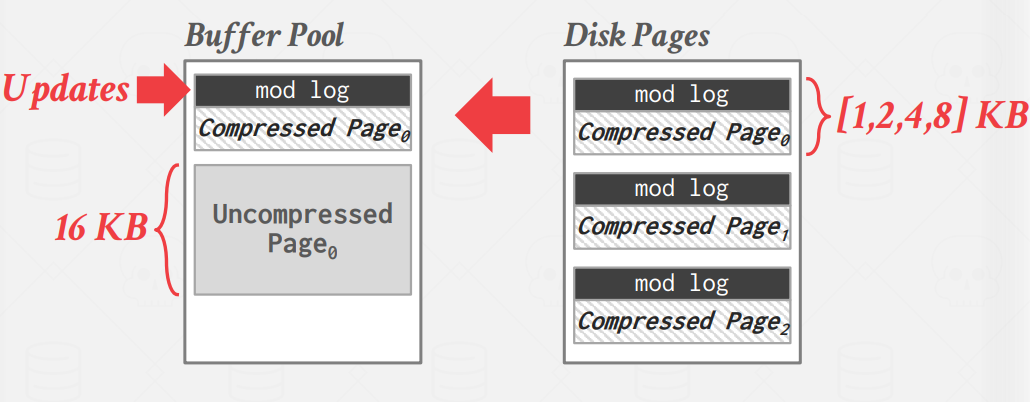
Columnar Compression
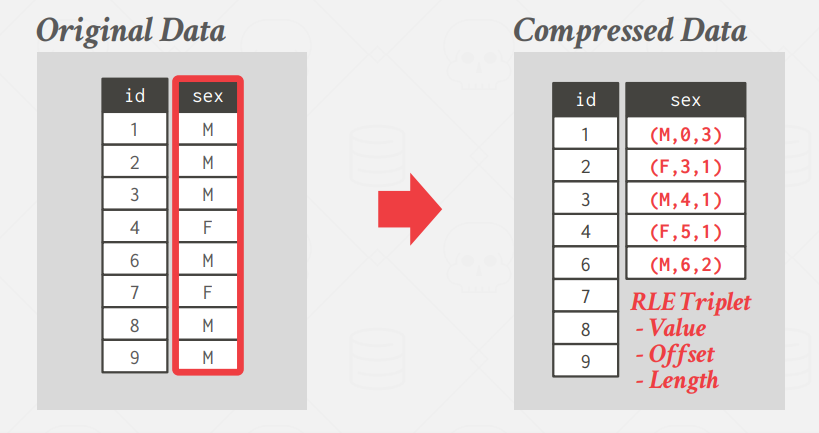
Run-Length Encoding (RLE)
RLE compresses runs of the same value in a single column into triplets:
The value of the attribute
The start position in the column segment
The number of elements in the run The DBMS should sort the columns intelligently beforehand to maximize compression opportunities. These clusters duplicate attributes and thereby increasing the compression ratio.
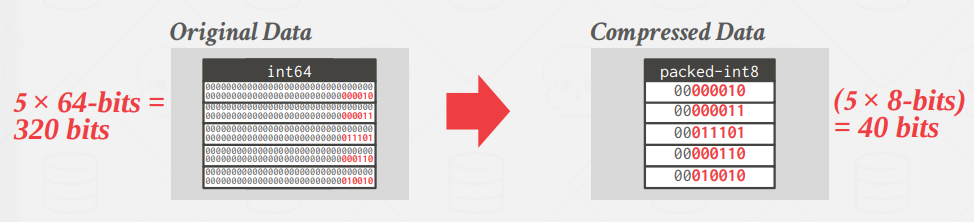
Bit-Packing Encoding
When values for an attribute are always less than the value’s declared largest size, store them as a smaller data type.
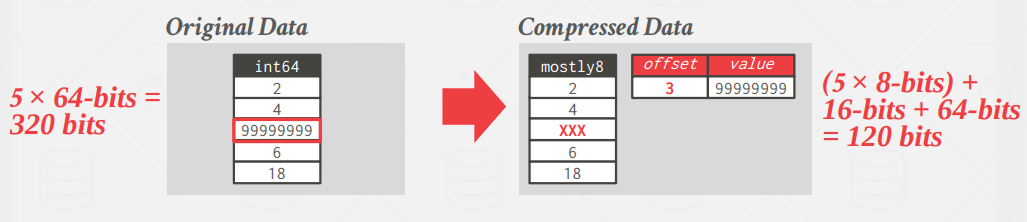
Mostly Encoding
Bit-packing variant that uses a special marker to indicate when a value exceeds the largest size and then maintains a look-up table to store them.
Bitmap Encoding
The DBMS stores a separate bitmap for each unique value for a particular attribute where an offset in the vector corresponds to a tuple.
The ith position in the bitmap corresponds to the ith tuple in the table to indicate whether that value is present or not.
The bitmap is typically segmented into chunks to avoid allocating large blocks of contiguous memory.
This approach is only practical if the value cardinality is low, since the size of the bitmap is linear to the cardinality of the attribute value.
If the cardinality of the value is high, then the bitmaps can become larger than the original data set.

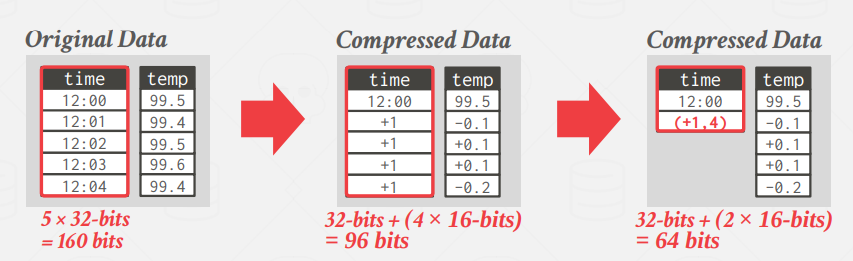
Delta Encoding
Instead of storing exact values, record the difference between values that follow each other in the same column.
The base value can be stored in-line or in a separate look-up table.
We can also use
RLEon the stored deltas to get even better compression ratios.
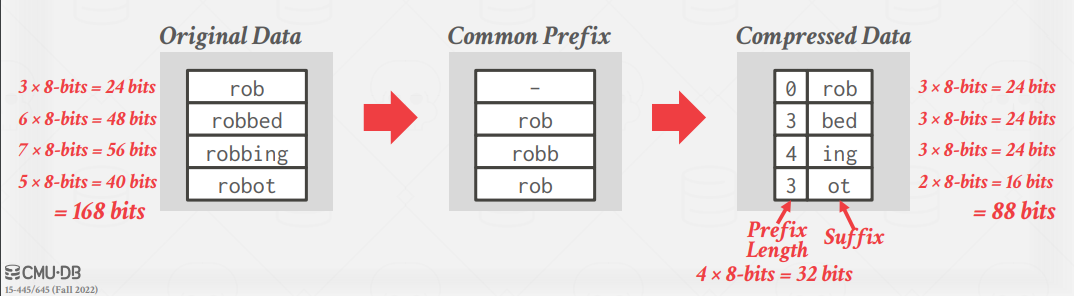
Incremental Encoding
This is a type of delta encoding avoids duplicating common prefixes/suffixes between consecutive tuples. This works best with sorted data.
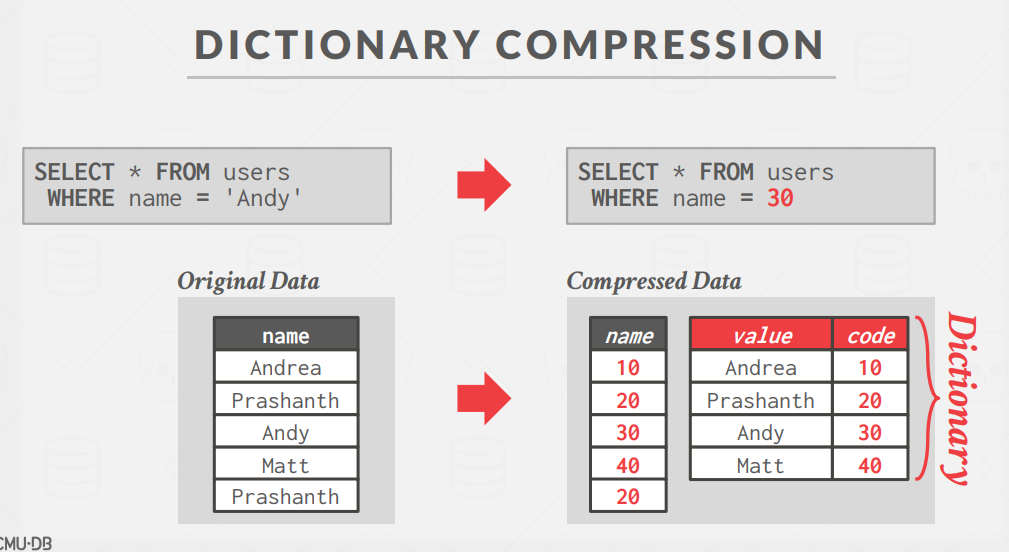
Dictionary Compression
The most common database compression scheme.
The DBMS replaces frequent patterns in values with smaller codes.
It then stores only these codes and a data structure (i.e., dictionary) that maps these codes to their original value.
A dictionary compression scheme needs to support fast encoding/decoding, as well as range queries.
Conclusion
In conclusion, the choice of storage model and compression techniques in a database system has a significant impact on its performance and efficiency. Row-based storage is suitable for OLTP workloads, offering fast inserts, updates, and deletes, while column-based storage is more efficient for OLAP workloads, optimizing query processing and data compression.
Compression plays a vital role in reducing disk I/O and optimizing storage space, with various schemes available at different levels of granularity. Understanding the specific workload requirements and data characteristics is crucial in making informed decisions about storage models and compression strategies for an efficient and scalable database system.
Resources
Subscribe to my newsletter
Read articles from Ahmad Ateya directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Ahmad Ateya
Ahmad Ateya
Software Engineer