Unleashing the Magic of CNN: An In-depth Exploration of Convolutional Neural Networks
 Naveen Kumar
Naveen KumarTable of contents
- INTRODUCTION
- LAYERS IN CNN
- INPUT LAYER
- HOW TO FIND THE TOTAL NUMBER OF NEURONS IN A NEURAL NETWORK
- WHAT ARE FILTERS?
- SOME TYPES OF FILTERS
- EDGE DETECTION FILTER
- Blur/Smoothing Filter
- SHARPENING FILTER
- STEPS FOR CONVOLUTION OPERATION IN THE CONVOLUTIONAL LAYER
- WHAT IS PADDING?
- WHAT IS STRIDE?
- VALID PADDING
- SAME PADDING
- ACTIVATION LAYERS
- ReLU-ACTIVATION
- SIGMOID-ACTIVATION
- Tanh-ACTIVATION
- LeakyRelu-ACTIVATION
- Elu-ACTIVATION
- POOLING LAYER
- MAX POOLING
- AVERAGE POOLING
- WHY WE USE POOLING?
- FLATTEN LAYER
- FULLY CONNECTED LAYER
- DIFFERENCE BETWEEN THE OUTPUT LAYER AND THE DENSE LAYER
- FORWARD PROPAGATION IN CONVOLUTION
- DERIVING FORWARD PROPAGATION EQUATION
- BACKWARD PROPAGATION IN CONVOLUTION
- DERIVING BACKWARD PROPAGATION EQUATION
- CONCLUSION
INTRODUCTION
In the realm of deep learning, Convolutional Neural Networks (CNN) have emerged as a game-changer, revolutionizing the field of computer vision and image analysis. With their ability to extract meaningful features from visual data, CNNs have enabled remarkable advancements in image recognition, object detection, and even autonomous driving. In this blog, we will embark on a journey to unravel the inner workings of CNNs, exploring their applications, architecture, and the incredible impact they have on our digital world.
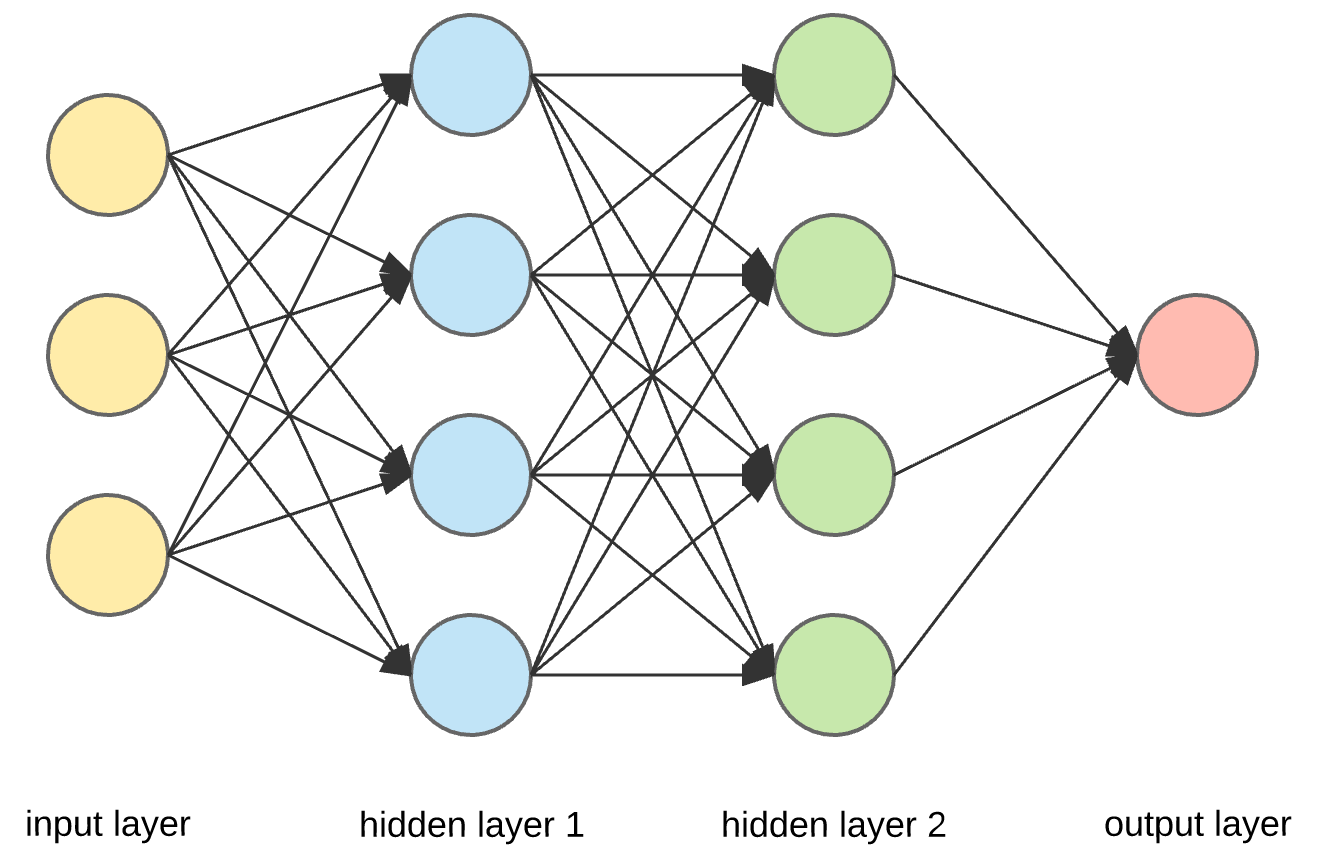
LAYERS IN CNN
Input Layer
Convolutional Layer
Activation Layer
Pooling Layer
Flatten Layer
Fully Connected Layer/Dense layer
Output Layer
INPUT LAYER
The input layer in a Convolutional Neural Network (CNN) is responsible for receiving the input data, which is typically an image or a set of images.
Mathematically,
Let's consider a grayscale image with dimensions width (W) and height (H)
The input layer will have the shape of
$$(W, H, C)$$
where
C- number of channels in the image
Example
If the image is RGB then
$$c=3$$

HOW TO FIND THE TOTAL NUMBER OF NEURONS IN A NEURAL NETWORK
FORMULA
$$neurons=WHC$$
NOTE:
The values of the input neurons represent the intensity or color values of the corresponding pixels in the image.
These values are then propagated forward through the subsequent layers of the CNN, undergoing convolutions, activations, pooling, and fully connected operations to extract meaningful features and make predictions based on the input data.
WHAT ARE FILTERS?
In CNNs, filters (also known as kernels or feature detectors) are small matrices used to extract specific features from the input data. These filters are convolved with the input image to produce feature maps, which represent the presence or activation of certain features.
SOME TYPES OF FILTERS
Edge Detection Filter (e.g., Sobel Filter)
Blur/Smoothing Filter (e.g., Gaussian Filter)
Sharpening Filter
EDGE DETECTION FILTER
This filter is used to detect edges in images by computing the gradient magnitude and orientation. It highlights regions of rapid-intensity transitions, such as edges between objects.
SOBEL FILTER
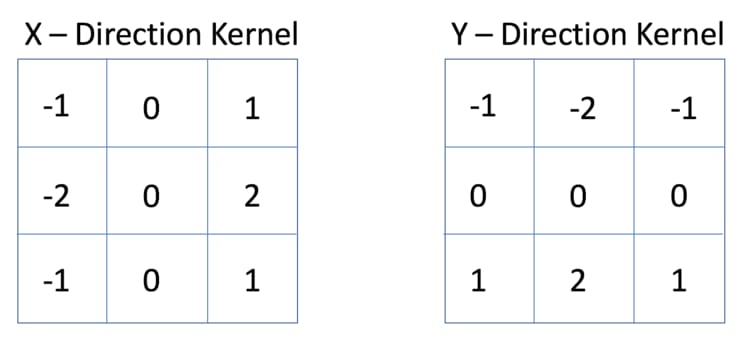
Blur/Smoothing Filter
This filter is used to blur or smooth images by averaging neighboring pixel values. It reduces noise and fine details, resulting in a more generalized representation.
GAUSSIAN FILTER

SHARPENING FILTER
This filter enhances edges and fine details in images by emphasizing the high-frequency components. It amplifies the difference between neighboring pixel values, resulting in a more detailed representation.
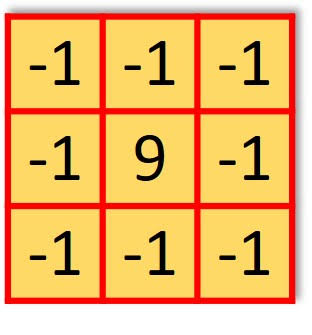
These filters are just a few examples of the many filters used in CNNs.
STEPS FOR CONVOLUTION OPERATION IN THE CONVOLUTIONAL LAYER
Filter/kernel application: A set of learnable filters or kernels, which are small matrices of weights, are applied to the input data.
Sliding window: The filters are slid or moved across the input data, typically in a small step called the stride.
Element-wise multiplication: At each position of the sliding window, element-wise multiplication is performed between the filter and the receptive field, which is the local region of the input that aligns with the filter's dimensions.
Summation: The results of the element-wise multiplication are summed up to obtain a single value in the output feature map at that position.
Repeating for all positions: The above steps are repeated for every position as the filters slide over the entire input, generating a set of feature maps as the output.
This convolution operation allows the convolutional layer to capture local patterns and features present in the input data, which are crucial for subsequent layers to learn hierarchical representations and make accurate predictions.
PROBLEMS IN CONVOLUTION
Information Loss at the Border
Output Size Reduction
As we see in the above illustration.
HOW TO OVERCOME?
To overcome by padding.
WHAT IS PADDING?
Padding in the context of Convolutional Neural Networks (CNNs) refers to the technique of adding extra border pixels to the input data before performing the convolution operation.
ADVANTAGE
Preserve spatial dimensions.
Mitigate the loss of information at the edges of the input.
TYPES OF PADDING
Valid Padding (No Padding)
Same Padding
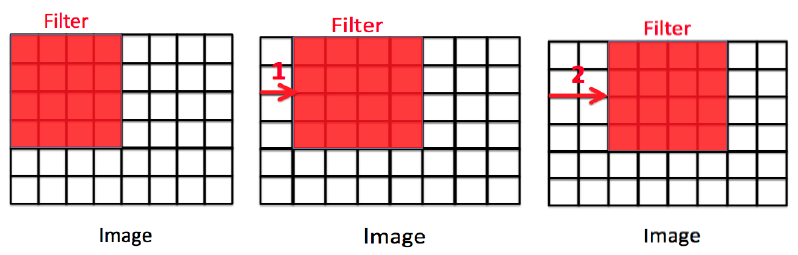
WHAT IS STRIDE?
Stride in CNNs determines the step size at which the filter moves during convolution.
An Example Figure illustrates the moving of filters for stride 1 and 2
VALID PADDING
In a valid padding, no padding is added to the input data.
The filters are only applied to positions where they fully overlap with the input.
As a result, the output feature maps have reduced spatial dimensions compared to the input.
FORMULA:
If the input is n X n and the filter size is f X f, then the output size will be
(n-f+1) X (n-f+1)
ILLUSTRATION:

NOTE:
The size of the filter should be taken as (f_odd X f_odd)
Reason:
Symmetry and Centering: An odd-sized filter allows for a symmetrical structure with a well-defined center.
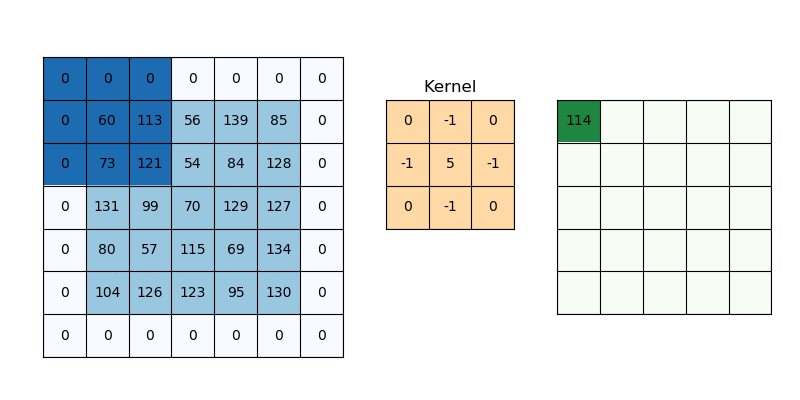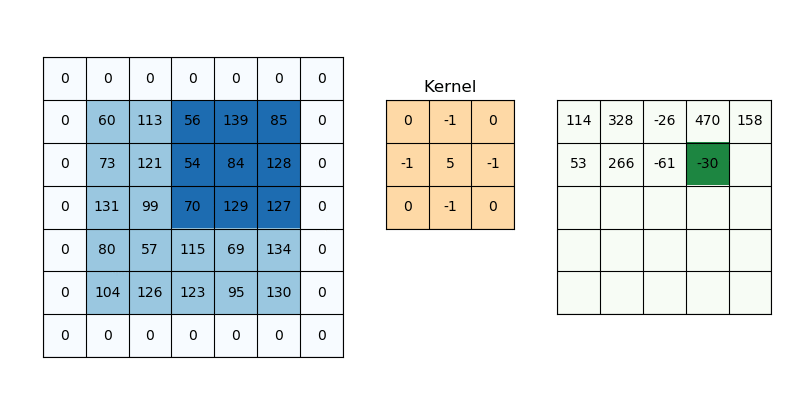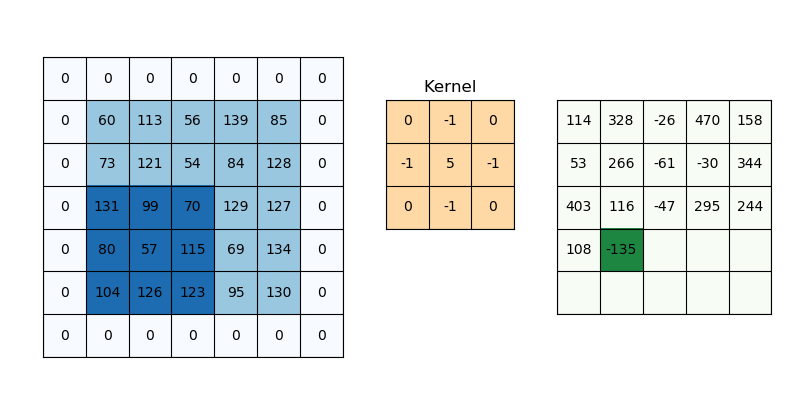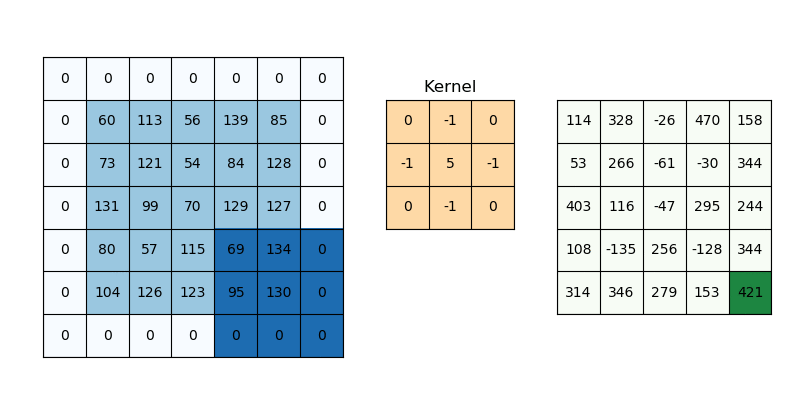
SAME PADDING
Same padding is a type of padding where the input is padded in such a way that the output feature maps have the same spatial dimensions as the input.
FORMULA
For padding p, filter size 𝑓∗𝑓 and input image size 𝑛 ∗ 𝑛 and stride ‘𝑠’ our output image dimension will be
[ {(𝑛 + 2𝑝 − 𝑓 + 1) / 𝑠} + 1] ∗ [ {(𝑛 + 2𝑝 − 𝑓 + 1) / 𝑠} + 1]ILLUSTRATION:
The example for applying 3x3 filters on zero-padded input image with stride 1
ACTIVATION LAYERS
An activation layer in a CNN applies a non-linear function element-wise to the output of the previous layer, introducing non-linearity and enabling the network to learn complex patterns in the data.
TYPES OF ACTIVATION LAYERS USED:
ReLU (Rectified Linear Unit)
Sigmoid
Tanh (Hyperbolic Tangent)
Leaky ReLU
ELU (Exponential Linear Unit)
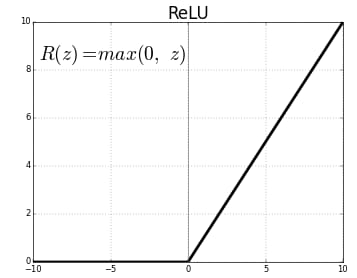
ReLU-ACTIVATION
Rectified Linear Unit
Sets negative values to zero and keeps positive values unchanged.
FUNCTION:
$$f(x) = max(0, x)$$
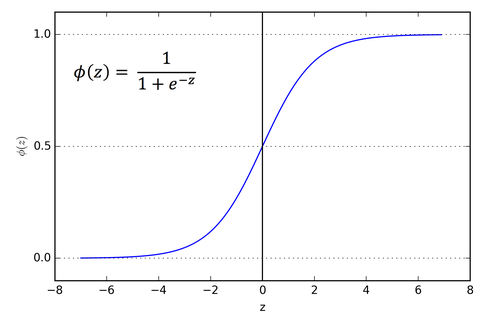
SIGMOID-ACTIVATION
- Squashes the input values between 0 and 1, providing a probability-like output.
FUNCTION:
$$f(x) = 1 / (1 + exp(-x))$$
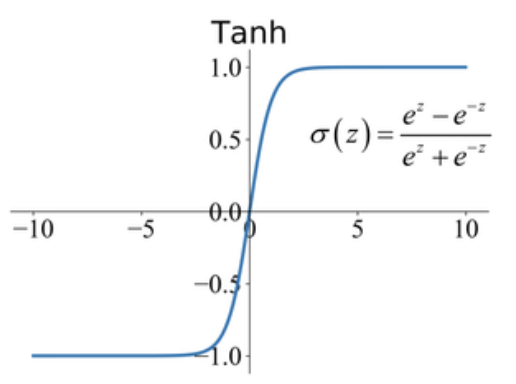
Tanh-ACTIVATION
- Squashes the input values between -1 and 1, providing a normalized output.
FUNCTION:
$$f(x) = (exp(x) - exp(-x)) / (exp(x) + exp(-x))$$
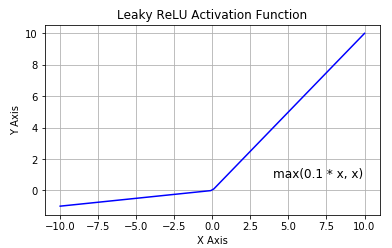
LeakyRelu-ACTIVATION
- Similar to ReLU but allows a small, non-zero gradient for negative values, preventing dead neurons.
FUNCTION:
$$f(x) = max(0.01x, x)$$
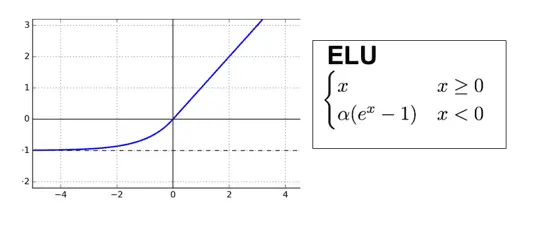
Elu-ACTIVATION
- Exponential Linear Unit
FUNCTION:
$$f(x) = x ; x > 0, and f(x) = alpha * (exp(x) - 1) ; x <= 0$$
POOLING LAYER
A pooling layer in a Convolutional Neural Network (CNN) is responsible for reducing the spatial dimensions (width and height) of the feature maps generated by the preceding convolutional layers.
Pooling layers help to extract the most important and representative features from the feature maps while reducing the computational complexity of the network.
TYPES OF POOLING LAYERS USED
Max Pooling
Average Pooling
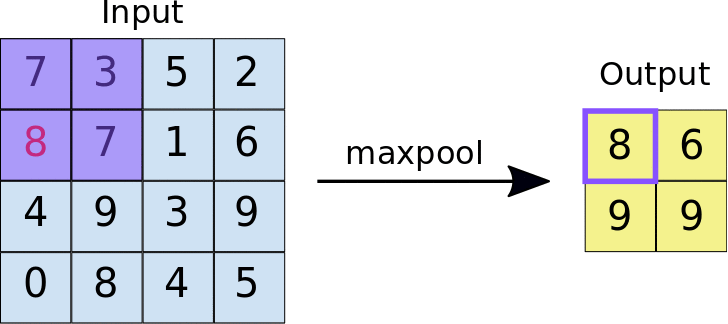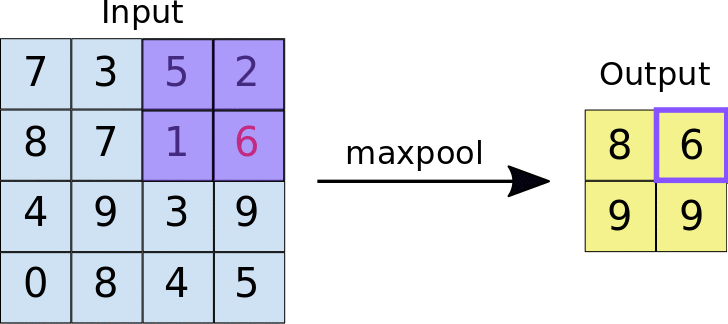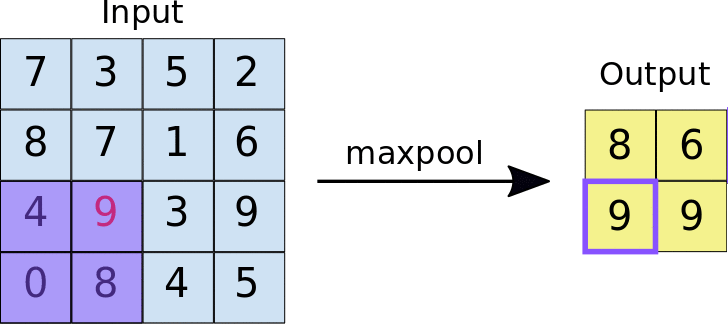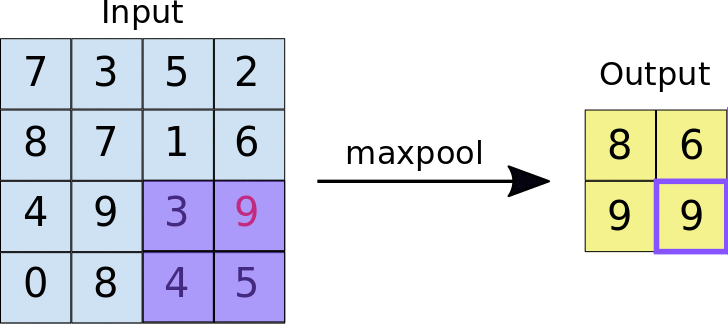
MAX POOLING
In max pooling, the maximum value within each window is selected as the representative value for that region.
ILLUSTRATION:
Applying maxPooling2D for the image with stride=2.
AVERAGE POOLING
In average pooling, the average value within each window is computed and used as the representative value.
SHAPE OF OUTPUT IMAGE AFTER POOLING:
If the input of the pooling layer is nh X nw X nc, then the output will be
$${(nh – f) / s + 1} * {(nw – f) / s + 1} X nc$$
WHY WE USE POOLING?
Dimensionality reduction: By reducing the spatial dimensions, pooling layers help to decrease the number of parameters in the network and control overfitting.
Translation invariance: Pooling layers capture the most salient features within each region, making the network more robust to translations or slight spatial variations.
Computationally efficient: Pooling reduces the computational complexity of the network by downsampling the feature maps.
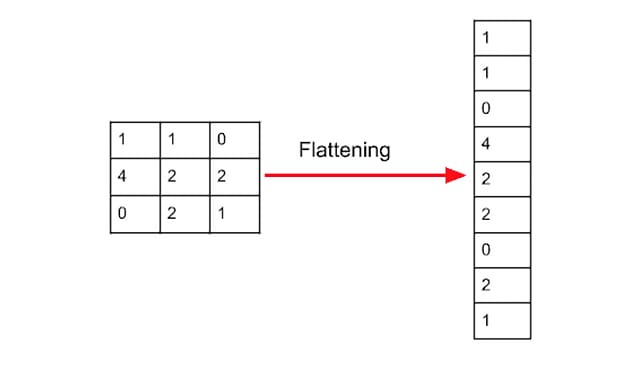
FLATTEN LAYER
The purpose of the flattening layer is to convert the multi-dimensional output of the previous layer (e.g., convolutional layer) into a one-dimensional vector that can be fed into the fully connected layers.
ILLUSTRATION OF FLATTENING
FULLY CONNECTED LAYER
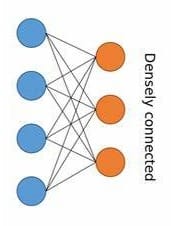
A fully connected layer, also known as a dense layer, is a type of layer in a neural network where every neuron in the layer is connected to every neuron in the previous layer. In a Convolutional Neural Network (CNN), fully connected layers are typically added after the convolutional and pooling layers to process the extracted features and make predictions.
We can use some kinds of Fully connected layers. They are,
Dense layer
Global MaxPooling layer
Global AveragePooling layer
DENSE LAYER:
A traditional fully connected layer, where each neuron is connected to every neuron in the previous layer. This layer can have any desired number of neurons.
GLOBAL MAX POOLING:
Global max pooling is a pooling operation commonly used in convolutional neural networks (CNNs). It reduces the spatial dimensions of feature maps to a single value by selecting the maximum value within each feature map.
EXAMPLE
Consider image matrix
[[2, 4, 3],
[1, 5, 6],
[8, 2, 9]]
OUTPUT
Global max pooling results in
9
GLOBAL AVERAGE POOLING
Global average pooling is a pooling operation commonly used in convolutional neural networks (CNNs). It reduces the spatial dimensions of feature maps to a single value by taking the average of all values within each feature map.
EXAMPLE
Consider image matrix
[[2, 4, 3],
[1, 5, 6],
[8, 2, 9]]
OUTPUT
Global Average pooling results in
(2 + 4 + 3 + 1 + 5 + 6 + 8 + 2 + 9) / 9=4.44
DIFFERENCE BETWEEN THE OUTPUT LAYER AND THE DENSE LAYER
| Dense Layer | Output Layer |
| Can be an intermediate layer in the network architecture | Typically the final layer of the neural network |
| Consists of multiple neurons connected to the previous layer | Contains neurons representing the predicted output values |
| May use various activation functions (e.g., ReLU, sigmoid) | The activation function depends on the specific task |
| Performs computations on the input data to learn complex representations | Produces the final predictions or outputs of the network. |
FORWARD PROPAGATION IN CONVOLUTION
Forward propagation in convolution refers to the process of passing the input data through the layers of a convolutional neural network (CNN) to generate predictions. It involves the sequential application of convolutional, activation, pooling, and fully connected layers.
During forward propagation, the input data (such as an image) is convolved with learnable filters in the convolutional layers. The convolutions produce feature maps that capture spatial patterns and local dependencies. Activation functions, such as ReLU, are then applied to introduce non-linearity and enhance the network's expressive power.
Pooling layers, such as max pooling or average pooling, are used to downsample the feature maps, reducing their spatial dimensions while preserving important information. This helps to extract the most salient features and make the network more robust to variations in object location and size.
After the convolutional and pooling layers, the feature maps are flattened into a 1D vector and passed through fully connected layers. These layers connect every neuron to the neurons in the previous layer, allowing the network to learn higher-level representations and make predictions based on the extracted features.
Finally, the output layer produces the final predictions or class probabilities, depending on the task at hand. This forward propagation process enables the CNN to process and transform the input data, progressively extracting and integrating relevant features to make accurate predictions.

DERIVING FORWARD PROPAGATION EQUATION
In forward propagation in a convolutional neural network (CNN), biases are often used along with kernels.
Biases in neural networks provide an additional value that helps the network account for variations and make more accurate predictions.
STEP 1:
Let us consider
X-Inputs(n-number of image matrix)
K-Kernels(Applying for each image)
Y-Output(Predicted value)
B-Bias
Let's take Three inputs and Two outputs which is represented by
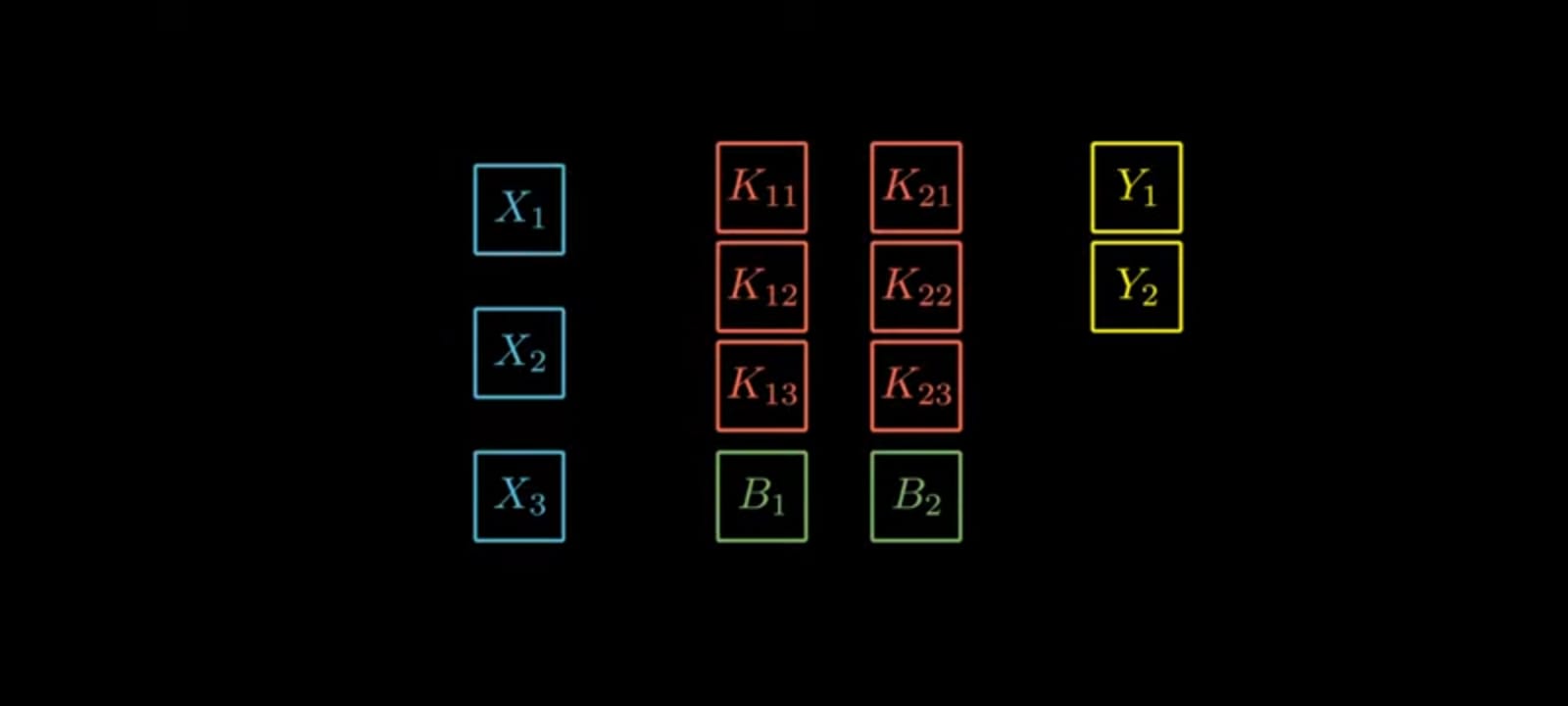
Step 2: For the outputs
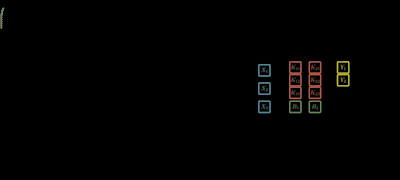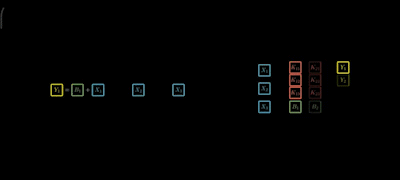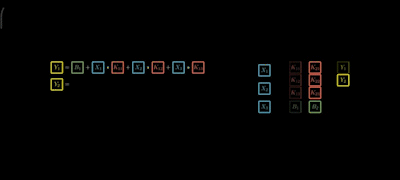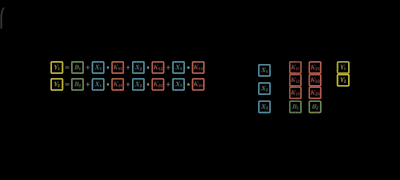
Step 3: Similarly for j -inputs and d-outputs
Note : Here *(Dot product)
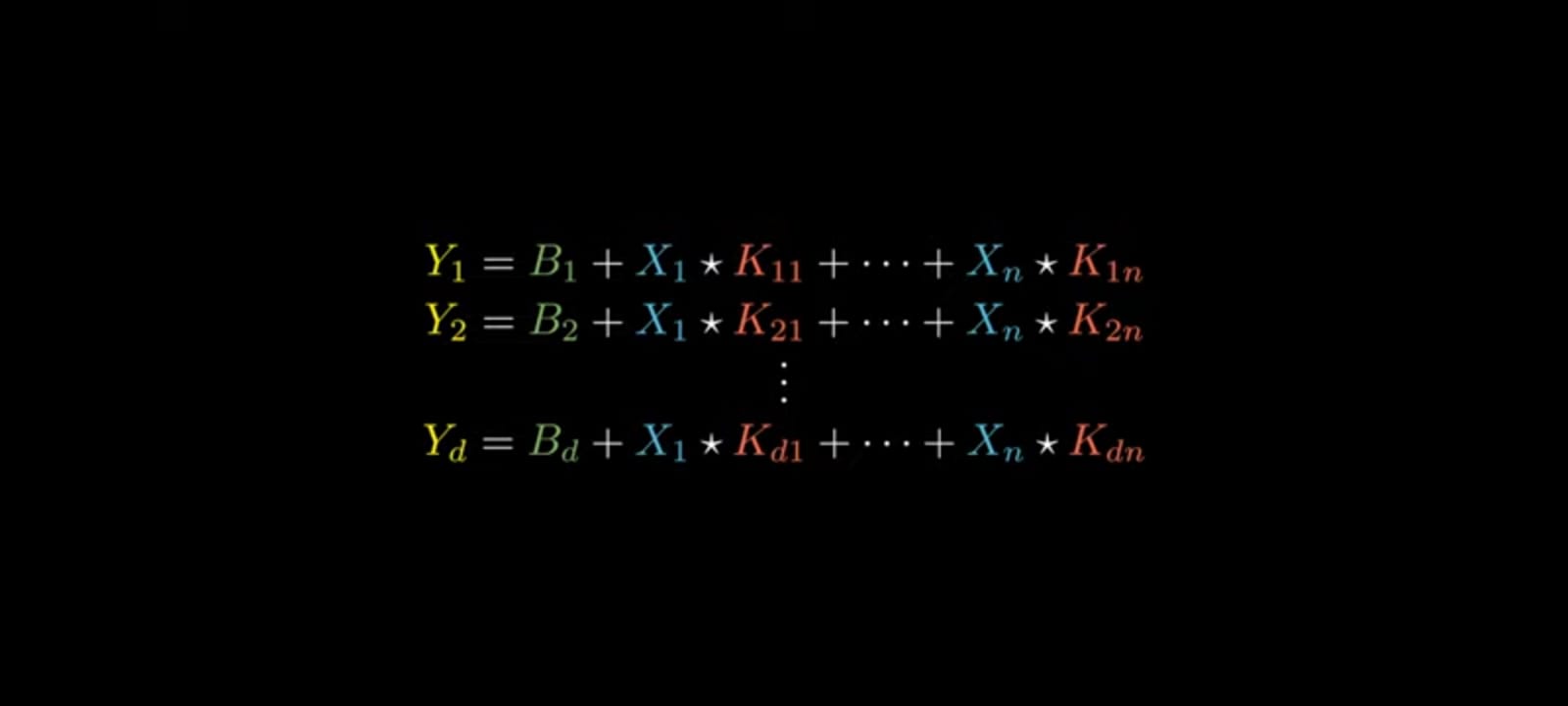
Step 4: For the above equations matrix representation is

Step 5: Final equation in general is

BACKWARD PROPAGATION IN CONVOLUTION
Backward propagation, also known as backpropagation or backdrop, is the process used in training a neural network, including convolutional neural networks (CNNs). It involves calculating and propagating gradients backward through the network to update the model's parameters and optimize its performance.
During the backward propagation process, the goal is to compute the gradients of the loss function with respect to the model's parameters. These gradients indicate how the parameters should be adjusted to minimize the difference between the network's predictions and the desired output.
DERIVING BACKWARD PROPAGATION EQUATION
Let us consider E be the error calculated after forward propagation now its iteratively backpropagate to update the weights to minimize the error.
Step 1: Representation
Consider Forward propagation equation to do backward propagation,

Error E will be Partial Differentiation with respect to,
B-Bias
Kij-Kernels
Xj-Inputs
Representation for above partial differentiation is,

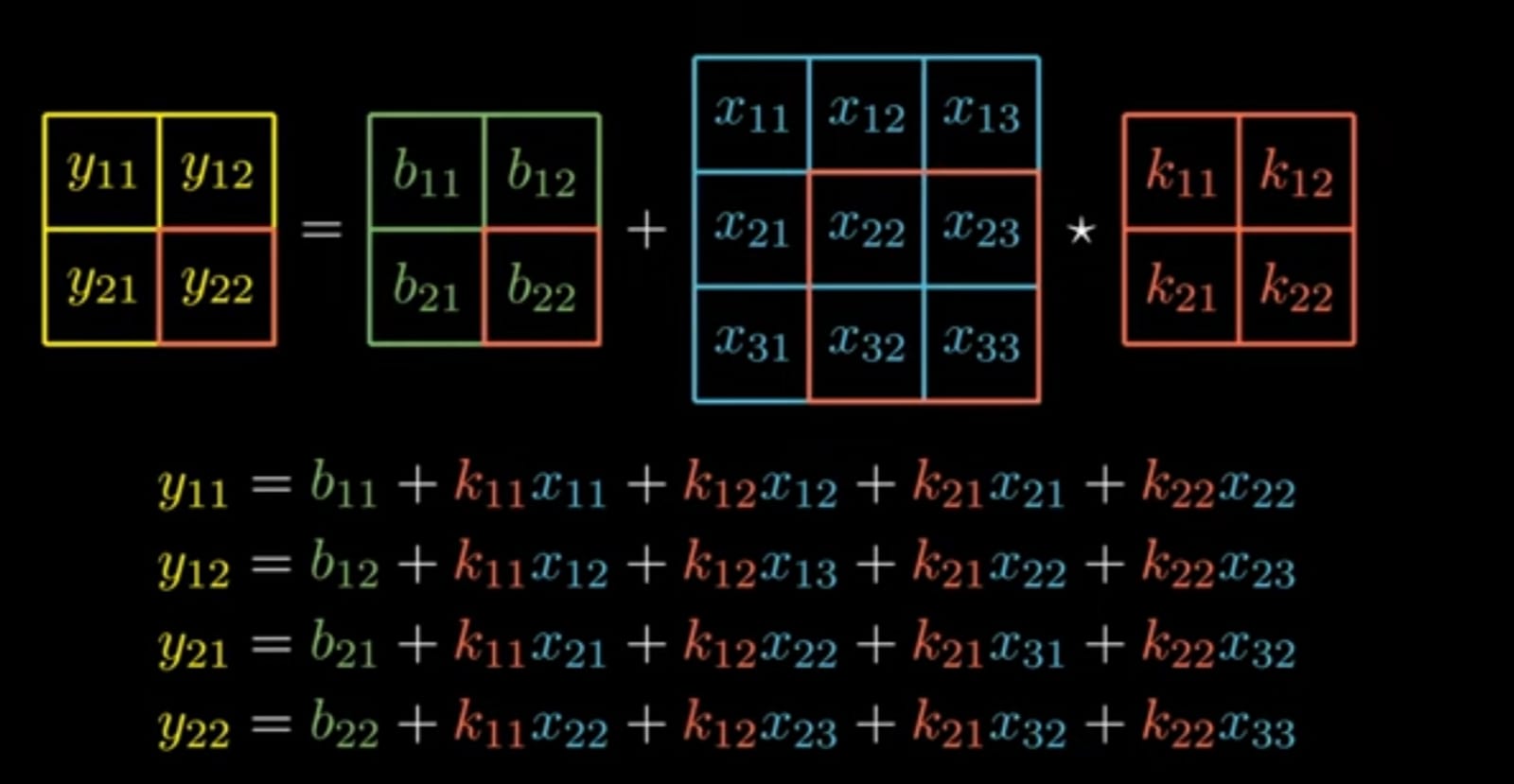
If we expand the Forward Propagation equation,
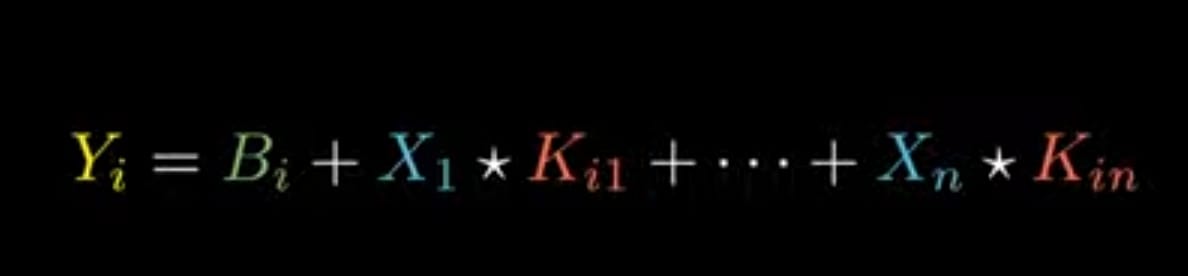
Step 2: Finding ∂E/∂Kij
From the above equation for simplicity let's take only

Note : The above representation is simplified equation taken for calculation and its corresponding matrices.
If we expand it the equations we get are,
Equation_____(A)
Applying Chain-Rule for finding ∂E/∂K_11 for above y_11
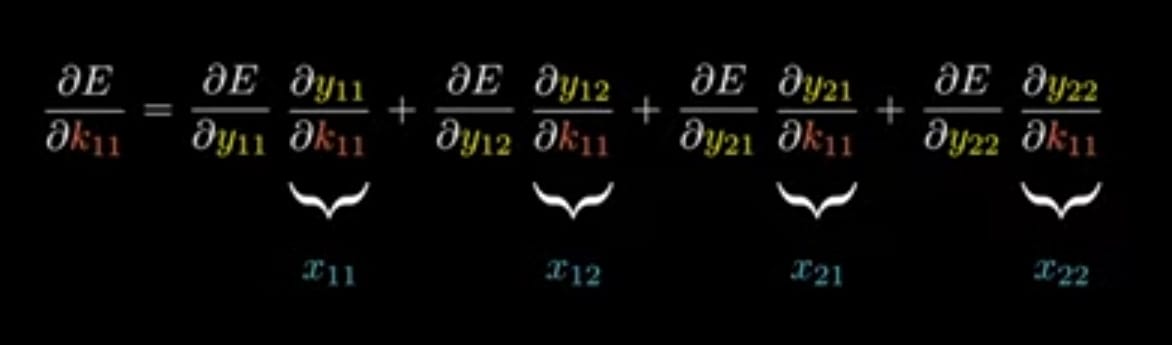
Hope above represenation understands,
Now, Similarly apply for y_11 to y_22 the equations becomes
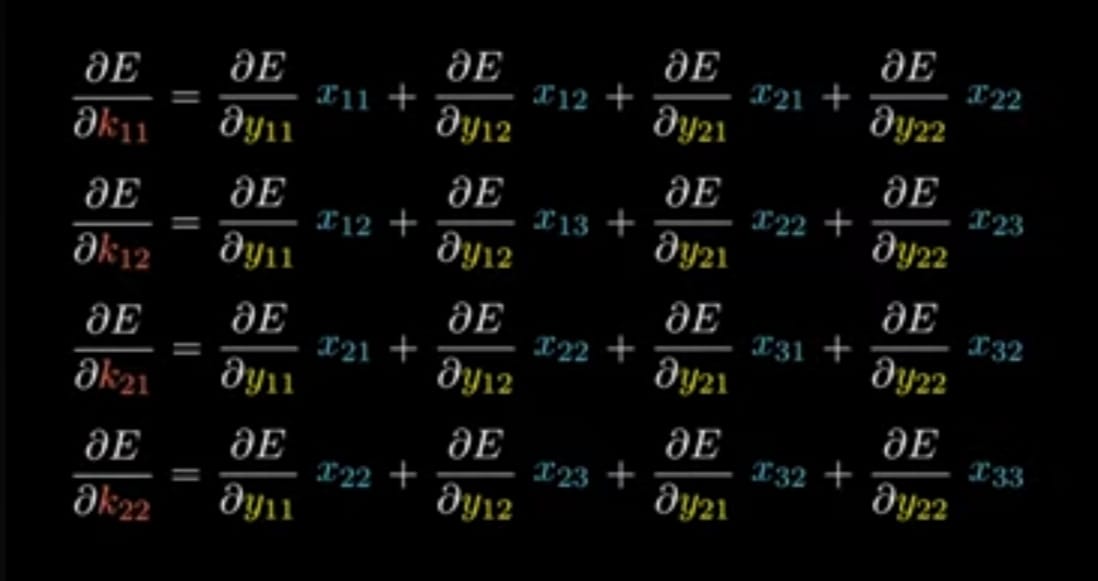
The matrices representation for above one is,
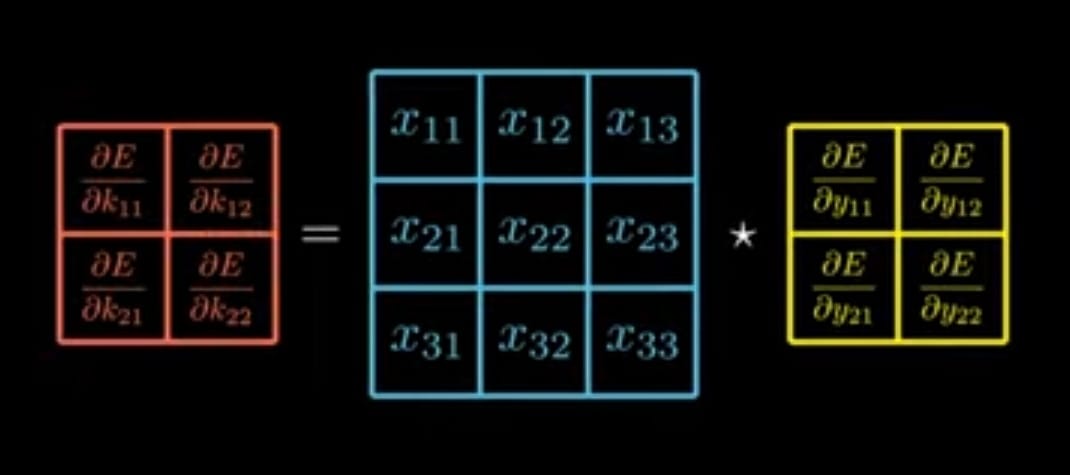
The equation for above one is

Note : The above is simplified form which is only for Yi=Bi+Xi*Ki1
Now for the actual forward propagation equation we can derive the ∂E/∂Kij which will be,
DERIVED EQUATION__(1):

Step 3: Similarly for ∂E/∂Bi
Applying chain rule for only ∂E/∂B_11
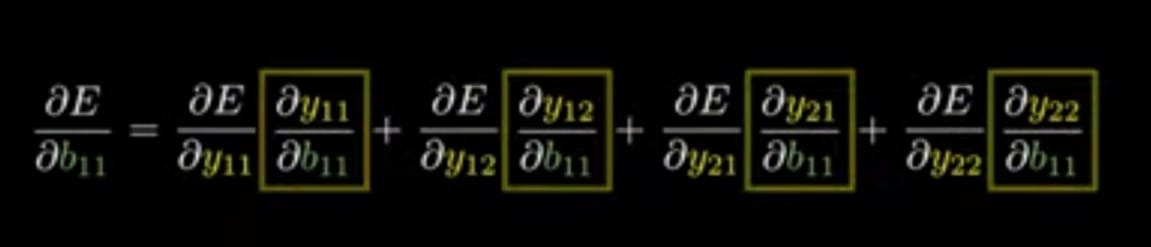
If we see in the Equation__(A),
b11 is associated only with y11,

hence for y11 to y22 we can write it as,

Note : From above representation we can clearly say that, Bias gradient is equal to output gradient.
Now for the actual forward propagation equation we can derive the ∂E/∂Bi which will be,
DERIVED EQUATION__(2):
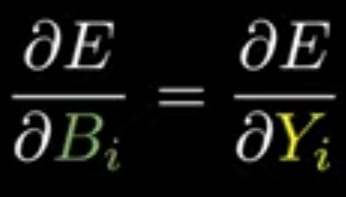
Step 4: Similarly for ∂E/∂Xj
Applying chain rule for only ∂E/∂x_11
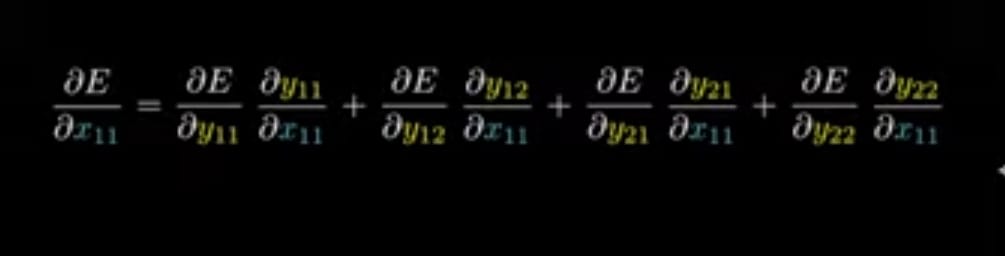
If we see in the Equation__(A),
x11 is associated only with y11
i.e
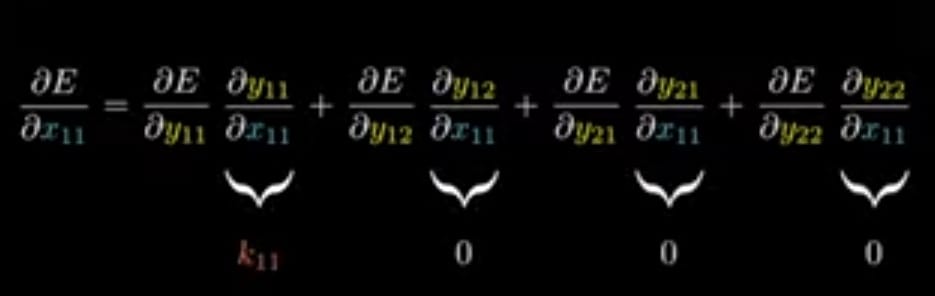
if we apply above method for y11 to y22
we get,

Matrix representation for above one is,
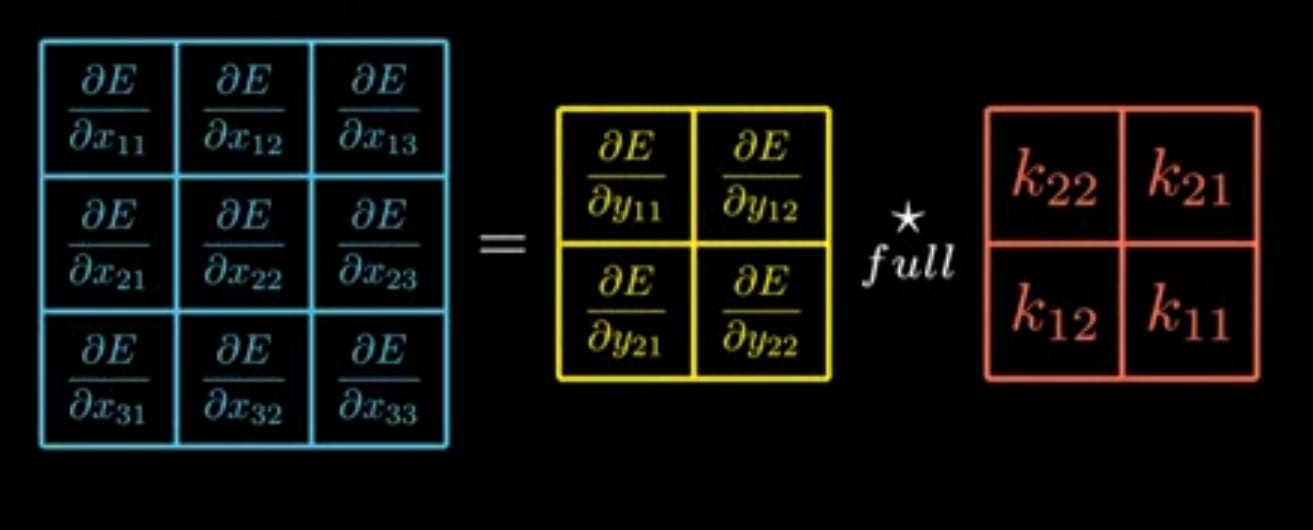
Note : In above representation we see that kernel is rotated 180 degree
In general simplified equation is,
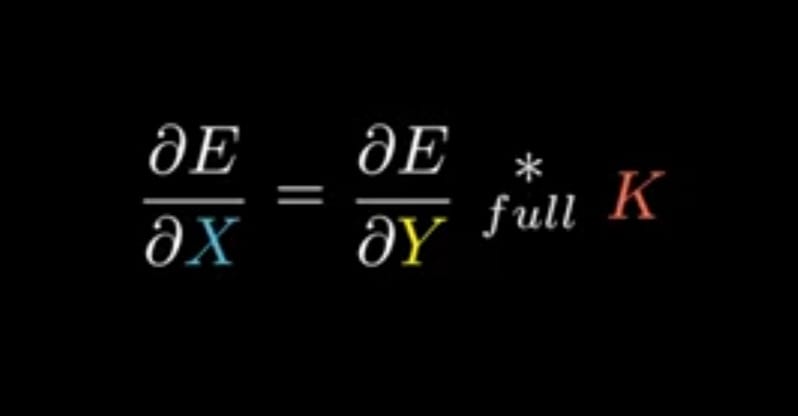
Now for the actual forward propagation equation we can derive the ∂E/∂Bi which will be,
DERIVED EQUATION__(3):
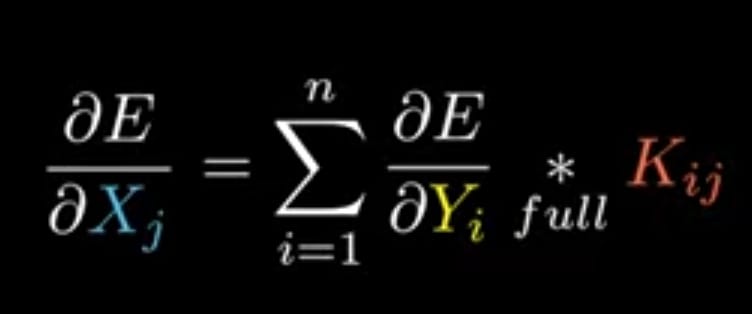
BACKPROPAGATION EQUATIONS(GRADIENT DESCENT):
From the above step 1 to step 4 we get,

The above gradients are used for updating the weights.
CONCLUSION
Convolutional Neural Networks (CNNs) have revolutionized computer vision tasks with their ability to capture spatial patterns and hierarchical representations. By leveraging convolution, activation, pooling, and fully connected layers, CNNs extract features, introduce non-linearity and make accurate predictions. CNNs have become crucial in image classification, object detection, and semantic segmentation, advancing machine understanding of visual data.
Hope You Enjoyed it!!!
Support my blog!!!
Thank you!!!
Subscribe to my newsletter
Read articles from Naveen Kumar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by