Data Science's Missing Link: Effective approaches for Handling Missing Data
 Sharmishtha Bharti
Sharmishtha Bharti
Hide and Seek with data?
Let's assume we have a dataset of consumer data from an online retailer. The dataset contains several different parameters, including age, gender, location, and past purchases. An observation is made that some entries lack information for the "Location" attribute.
Further investigation reveals that the cause of missing data is due to consumers who chose not to enter their location during registration. The business opted to respect consumers' privacy by allowing them to choose whether or not to enter their location.
This results in Missing Data in the dataset. When you don't have data stored for specific variables or participants, you have missing data, also known as missing values. Data loss can occur for a variety of reasons, including incorrect data entry, device failures, lost files, and more.
Without the necessary data, conducting accurate analysis and making informed decisions becomes a tedious and much more challenging task. Data serves as the foundation for any analysis, and missing or incomplete data can hinder the process.
To make sure the dataset is complete and representative of the population or sample being studied, it is crucial to address missing data. Data that is missing frequently has important information. If not handled appropriately, it may also introduce bias into your analysis. It may affect how well machine learning and predictive modeling systems function. Results might be incorrect and misleading if missing data is ignored or incomplete information is filled in using the wrong techniques.
Before learning about the techniques to handle missing data, we need to know the types of missing data. Missing data is broadly classified into :
Missing Completely At Random (MCAR) - In this category, both observable and unobserved data are unrelated to the missingness of the data. The missingness happens randomly and is independent of any variable or data pattern.
Missing At Random (MAR) - The missingness in MAR correlates with the observable data but not the unobserved data. The dataset's other variables affect the missingness but not the actual missing values.
Missing Not At Random (MNAR) - The unobserved data in MNAR are related to the missingness. The missing values may be connected to the missing values themselves since they are systematically different from the observed data.
Consider the dataset Housing Prices Competition, taking, for example, the "test.csv", we can find the missing values using Python by using :
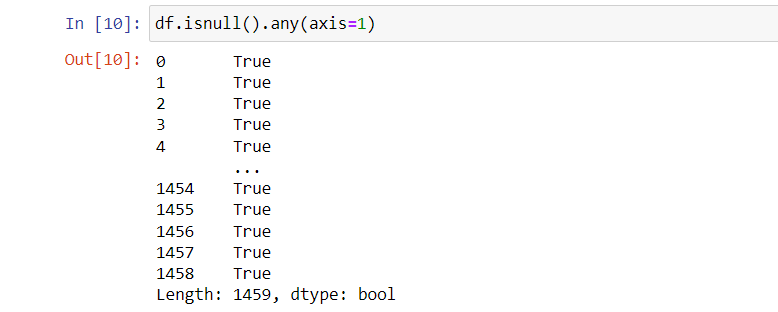
This helps us figure out which rows have a missing value and which rows do not. We can see that there are 1459 values that are missing in the dataset consisting of 80 columns. This can also be calculated using the shape attribute.
No matter the type of missing data, the problems concerning missing data need to be addressed and taken care of. The main strategies followed for handling missing data include Deletion Techniques like listwise deletion or Imputation Techniques like Regression imputation.
We can delete the missing values from the above dataset using dropna(). Using the dropna() attribute provided by Pandas is the quickest and easiest approach to remove all missing values. It will merely eliminate every row in your data frame that has an empty value.
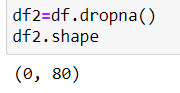
Using another variable df2, we drop the missing values from the dataset. The 0 denotes the number of missing values and 80 denotes the number of columns. This is easy for a small dataset but may not be efficient for a larger one.
Thus, advanced techniques for handling missing data including Pattern Recognition and Data augmentation techniques need to be applied to such datasets for improved efficiency and accurate removal of missing values.
Utilizing computer algorithms to identify data regularities and patterns is known as pattern recognition. It aids in the analysis of both data anomalies and data regularities. It has been used in a variety of industries, including seismic analysis, picture analysis, and computer vision. In this method, pattern recognition systems are trained using labeled training data. Each input value that is utilized to generate a pattern-based output has a label associated with it. Pattern recognition can be used to identify unknown items and uncover partially hidden patterns.
By producing fake data or imputing values for the missing data points, data augmentation techniques can aid in the discovery of missing data by expanding the size and diversity of the dataset. Techniques like Interpolation and Random Sampling are the most used data augmentation methods. In Python, you can estimate unknown data points between two known data points by using the interpolation approach. It is frequently used to use the values that are previously known to fill in any missing entries in a table or dataset. This method is primarily employed in image processing, but it also has applications in financial analysis.
A few tips to handle missing data:
Determine the missing values in your dataset: Begin by determining and comprehending the missing values in your dataset. Search your data for placeholders such as "NA," "NaN," or empty cells.
Establish the cause of the absence: Look for the cause of any missing data. It could be caused by several things, like incorrect data entry, broken equipment, or survey respondents who don't respond. You can choose the best course of action for handling missing data by being aware of the cause.
Eliminate missing data: You may eliminate the rows or columns with missing values if the data is sparse and randomly distributed. Be careful because this strategy could lead to prejudice and information loss.
Imputation using mean or median: If the missing values are numerical, you may want to think about imputing them using the mean or median of the existing data. The missing values in this method are assumed to be roughly comparable to the observed values.
Imputation using the mode: For categorical data, the mode, which reflects the value that appears the most frequently in the dataset, can be used to fill in missing values.
Apply predictive models: If your dataset has a significant quantity of missing data, you can apply machine learning methods or predictive models to infer missing values from other factors. Though it could take more work, this method can be more accurate.
Multiple Imputations: Multiple imputations is another sophisticated technique that entails building numerous plausibly imputed datasets from statistical models. This method accounts for the uncertainty involved with imputed missing values.
Flag values: Consider labeling or flagging missing values to set them apart from observed values. This will enable you to monitor any gaps in your analysis and interpretation.
These techniques of handling missing data are applied in a variety of fields ranging from Medical Research to Financial Data Analysis to even Environmental Analysis. In any data analysis or research effort, handling missing data is a crucial step. It is vital to deal with missing values properly because their existence can affect the precision and dependability of the results.
Subscribe to my newsletter
Read articles from Sharmishtha Bharti directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Sharmishtha Bharti
Sharmishtha Bharti
With a strong background in coding, databases, and machine learning and a thirst to learn more, I'm an aspiring data analyst who is currently pursuing her final year of college in Computer Science.