Understanding Transformers - Word Embeddings from Theory to Code
 Deepanshu Sachdeva
Deepanshu SachdevaTransformers is a deep learning model architecture introduced in the paper “Attention is All You Need” by Vaswani et al. It has gained significant popularity for its effectiveness in various natural language processing tasks.
The first step in training a transformer model is Input Embeddings, we are all aware of the infamous “One Hot Encoding”, where each word is represented as a binary vector with a dimension equal to the vocabulary size, with a value of 1 indicating the presence of that word and 0 otherwise. However, one-hot encoded vectors are sparse and do not capture the semantic relationships between words.
To capture the semantic relationships and to reduce the computation of using redundant — sparsity, we can use what is known as “learned word embeddings”, i.e an unsupervised learning method to learn the semantic relationships within words, for example the word “women” and “queen” should have a significant correlation and will help the tasks such as paraphrasing and machine to machine translation.
There are major two types of word embeddings —
Word2Vec
1. Calculated Bag of Words (CBOW)
2. Skip GramGlove
In this article, we will discuss Word2Vec’s Calculated Bag of Words in complete detail.
CBOW (Calculated Bag of Words) Like images, words also have some features, for example — domain, gender, plurality or verb tense. If you can reprsent the words in terms of these features as a quantity i.e a features a quantitative matrix, then using this matrix we can compare different words with each other and based on these features we can calculate the similarity between them. This feature matrix is nothing but the weights in a neural network.
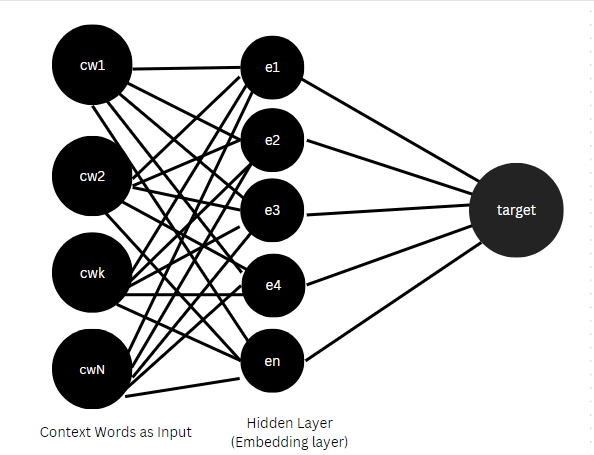
Neural Network to Learn Word Embeddings
Preparing DataThis algorithm uses sliding window technique to capture context of the “target” words. In this technique a corpus of n number of sentences is used, a window size is defined, where for each window in each sentence a target word is picked one by one, with the remaining words in the window as context to that target word. This way the training data is formulated where the input is the context words as an array, and the output is the target word. In learning this context, i.e after training the neural network, we develop a feature matrix that is considered to be the learned embedding, the size of the embedding matrix is (vocab size, embedding dimensions).

Here the embedding dimensions is a hyperparameter, which represents various features of the word as discussed.
We will be using Tensorflow to perform this unsupervised learning task,
import tensorflow as tf
import numpy as np
from tensorflow.keras.preprocessing.sequence import pad_sequences
Here, I am using some sample sentences, but generally the network is trained on a large corpus, preferably from Wikipidea.
# Example sentences
sentences = [
["I", "love", "chocolate"],
["I", "love", "ice", "cream"],
["I", "enjoy", "playing", "tennis"]
]
Now, we need to create our vocabulary from the sentences given, after that we need to map them to indexes so that we can later pass indexes (numbers) in the network, we will also keep a index to word mapping as well for inference.
# Create vocabulary
vocab = set([word for sentence in sentences for word in sentence])
word2idx = {word: idx for idx, word in enumerate(vocab)}
idx2word = {idx: word for idx, word in enumerate(vocab)}
vocab_size = len(vocab)
Now, comes the formulation of training data, using sliding window technique, we will use it to make sets of context words with target words.
# Generate training data
window_size = 4
train_data = []
for sentence in sentences:
for i, target_word in enumerate(sentence):
context_words = [sentence[j] for j in range(max(0, i - window_size), min(i + window_size + 1,len(sentence) )) if j>=0 and j != i]
train_data.append((context_words, target_word))
print(train_data)
Now, some pre-processing to map them to numbers using the dictionary that we created previously. We are using pad_sequences function to convert a list of lists to a numpy array of arrays.
# Generate input and output pairs for CBOW
train_inputs, train_labels = [], []
for context_words, target_word in train_data:
context_idxs = [word2idx[word] for word in context_words]
train_inputs.append(context_idxs)
train_labels.append(word2idx[target_word])
# print(train_inputs, train_labels)
# Convert to numpy arrays
train_inputs = pad_sequences(train_inputs, maxlen=window_size*2)
train_labels = np.array(train_labels)
Now, we define the model architecture, which is very preliminary intended only to learn the word embeddings by minimizing the loss between the predicted target word index and original target word index, here embedding_dim is a hyperparameter, and it represents number of features for each word as discussed, this helps us create an embedding matrix of size (vocab_size, embedding_dim), where each row in the matrix represents the word embeddings for each word in the vocabulary.
# Define CBOW model
embedding_dim = 10
cbow_model = tf.keras.Sequential([
tf.keras.layers.Embedding(input_dim=vocab_size, output_dim=embedding_dim, input_length=window_size*2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(units=vocab_size, activation='softmax')
])
Now, we train the model on the training data, which in turn learns the embedding that we wish to use.
# Compile and train the CBOW model
cbow_model.compile(optimizer='adam', loss='sparse_categorical_crossentropy')
cbow_model.fit(train_inputs, train_labels, epochs=10, verbose=1)
Now, that your model is trained, you can separate out the word embedding i.e the weights learned.
# Get the learned word embeddings
word_embeddings = cbow_model.get_weights()[0]
# Print the word embeddings
for i, embedding in enumerate(word_embeddings):
word = idx2word[i]
print(f"Word: {word}, Embedding: {embedding}")
and Voila! we have trained our personal word embedding model, it is just trained on a few sentences, so it will give poor results, for better results, you can just increase the number of sentences and you will be good to go!
Happy Learning!
#Generative Ai Use Cases #Natural Language Process #Python #Word Embeddings #ChatGPT
Subscribe to my newsletter
Read articles from Deepanshu Sachdeva directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by