Setting up a shared volume for your docker swarm using GlusterFs
 Mohamed Ashour
Mohamed Ashour
Working on a distributed software product before the advent of containers was quite different compared to how it is now, following the widespread adoption of containerization.
It goes without saying that for most people in the tech community, when containerization is mentioned, Docker is often one of the first things that come to mind, if not the very first. I'm not here to argue that others pioneered the concept of containerization before Docker; that might be a topic for another blog post.
Instead, I want to discuss a problem I encountered - and I'm sure others have as well - while working with Docker Swarm and needing some form of data sharing between swarm nodes. Unfortunately, this feature is not natively supported in Docker. You either have to rely on a third-party storage service that offers a robust API for your nodes to interact with, which can be quite expensive, or you can take the more challenging route and create your own shared storage solution. In this post, I'll share the latter approach that I chose to implement.
Introduction:
What is GlusterFS?

What is GlusterFS?
GlusterFS is a scalable, distributed file system that combines disk storage resources from multiple servers into a single global namespace. As an open-source solution, it offers features such as replication, quotas, geo-replication, snapshots, and more.
GlusterFS allows you to consolidate multiple nodes into one namespace, presenting various options. You can:
Create a replicated volume that ensures the availability of your data without having to worry about data loss.
Establish a distributed volume that increases storage capacity by distributing your data across multiple machines. While this option sacrifices availability, it provides more storage using the same resources.
You can learn about the various setups of Gluster from here https://docs.gluster.org/en/latest/Quick-Start-Guide/Architecture/
Let's start with our setup
First, let's envision a swarm setup consisting of three manager nodes and three worker nodes. We need the containers on the worker nodes to access the same data, regardless of their location, while maintaining data consistency. The availability of our data is of utmost importance. Therefore, we need to create a replicated GlusterFS volume that duplicates all the data across multiple replication nodes. Since we lack the resources to acquire additional machines to serve as storage pools, we will utilize our swarm machines to also function as storage pool nodes.
So, our architecture will be something like this
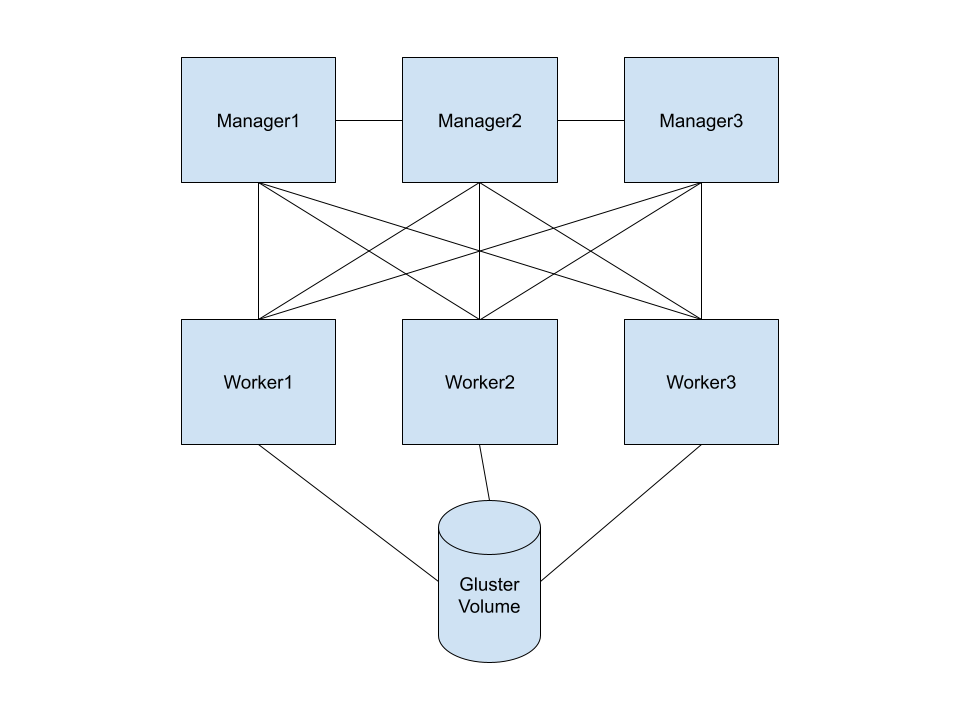
3 Swarm Managers
3 Swarm Workers
GlusterFs Volume connected to the 3 servers
Yes, I understand that this design might seem unusual at first, as it causes our workers to function as both storage pools and clients simultaneously. In this setup, they serve as replication nodes for the collected data while also acting as servers that mount the volume and read from it. However, upon further consideration, this configuration can be quite beneficial for a variety of use cases that your application might require, all without incurring any additional costs!
let's start the dirty work
let's assume we are working with a Debian-based distro, like Ubuntu
first, you will need to install GlusterFs on all three worker machines you can do this by
sudo apt update
sudo apt install software-properties-common
sudo add-apt-repository ppa:gluster/glusterfs-7
sudo apt update
sudo apt install glusterfs-server
then, you will need to start and enable the GlusterFs daemon service on all the worker machines
sudo systemctl start glusterd
sudo systemctl enable glusterd
then, make sure you generate an ssh-key on each machine
ssh-keygen -t rsa
after that, to be able to deal with all machines with their hostnames, you will need to edit the /etc/hosts for each of these machines and add the hostnames for the other nodes assigned to their IPs, like this format
<IP1> <HOSTNAME1>
<IP2> <HOSTNAME2>
Now, let's create our storage cluster, start from one of the machines and add the others using this command
sudo gluster peer probe <Hostname>
after you add the 2 nodes, run this command to make sure that all of the nodes joined the storage cluster
sudo gluster pool list
now, we will need to make a directory in all of the 3 workers to act like a brick for our volume But wait, what is a brick?? a brick is a directory that acts as a volume unit, and GlusterFs uses it in all of its storage pool nodes to know where is the data to store/deal with
so basically you will need to create this directory on each worker node, let's name it brick1 and put it under /gluster-volumes
sudo mkdir -p /gluster-volumes/brick1
Now, we are ready to create our replicated volume (let's call it demo-v ) [run this command only on the main machine]
sudo gluster volume create demo-v replica 3 <HOSTNAME1>:<BRICK_DIRECTORY> <HOSTNAME2>:<BRICK_DIRECTORY> <HOSTNAME3>:<BRICK_DIRECTORY> force
then start the volume
sudo gluster volume start demo-v
and Congrats, you have a replicated volume now that is ready to be mounted and used in any device Now, let's mount this volume on our 3 workers let's say that we will mount our volume under /our-application/logs
sudo mount.glusterfs localhost:/demo-v /our-application/logs/
then, to make it permanent, we will need to add it to our fstab file so open /etc/fstab and add this line
localhost:/demo-v /our-application/logs/ glusterfs defaults,_netdev,acl, backupvolfile-server=<HOSTNAME> 0 0
instead of the <HOSTNAME> add a hostname of one of the worker machines you have, so if you needed to get it out of the storage pool, you can still mount the volume using the other machine.
Now you can try this
touch /our-application/logs/test.txt
and check out the other workers, find the file? Congrats! you have a working replicated volume that is mounted across all of your workers.
In simpler words, this article shows how to use GlusterFS, a free and expandable file system, to share storage between Docker Swarm nodes. It guides you through installing and setting up GlusterFS, making a storage cluster, and testing if it works right.
Any questions? leave a comment!
Subscribe to my newsletter
Read articles from Mohamed Ashour directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Mohamed Ashour
Mohamed Ashour
Spending most of my time writing code, designing architecture, and creating pipelines to generate data. And the rest of it learning new things to write about.