Running Steampipe on AWS Fargate
 FINN
FINN
Are you using Steampipe to query your cloud services, such as an Amazon Web Services (AWS) environment? Are you using the results for reporting, security checks, governance or other important tasks in your organization? And are you tired of having to run those queries from your local machine or an AWS Elastic Compute Cloud (EC2) instance?
In this blog post we'll delve into running Steampipe directly from inside AWS itself, without setting up an EC2 instance. Instead, we'll have Steampipe run on an AWS ECS cluster as a scheduled AWS Fargate task. This allows for periodic querying while keeping it serverless, erasing the need to maintain an underlying Virtual Machine (VM). We also cover how the Steampipe query works across all our organization's accounts, so that you can get the full picture in one step.
We are documenting our struggles and solution in this blog post with the hope of assisting our readers. There isn't much publicly available information on running cross-account Steampipe queries from AWS Fargate, and we hope to change this.
Our use case
In the Tooling and Security team at FINN, we are currently focusing on cloud governance and related tasks. One pretty common thing to do, when growing as a company and having more and more resources in AWS, is establishing a tagging policy. This means that all resources should be tagged in a certain way to allow for better budget analysis, cost optimization, and also for example the ability to enforce backups only on production resources. Some example tags could include: the resource's department, team, environment or service. And it's also possible and common to restrict the values that are allowed. For example, tags with the key environment should be either production, staging or development.
One problem with introducing a tagging policy is that there can be a ton of existing resources that don't follow these rules. Because how could they, if those rules are just being introduced? It might be possible partly to automate tagging existing resources, but depending on the tags there is probably also some manual work involved. Especially if development teams are in charge of their own Infrastructure-as-Code (IaC) projects. So to get an overview of how the adoption of the tagging policy is going across the whole organization, we want to provide a dashboard showing how the adoption is coming along. This allows us and the developers to monitor progress and make sure that the number of active resources that aren't following the tagging policy becomes smaller over time.
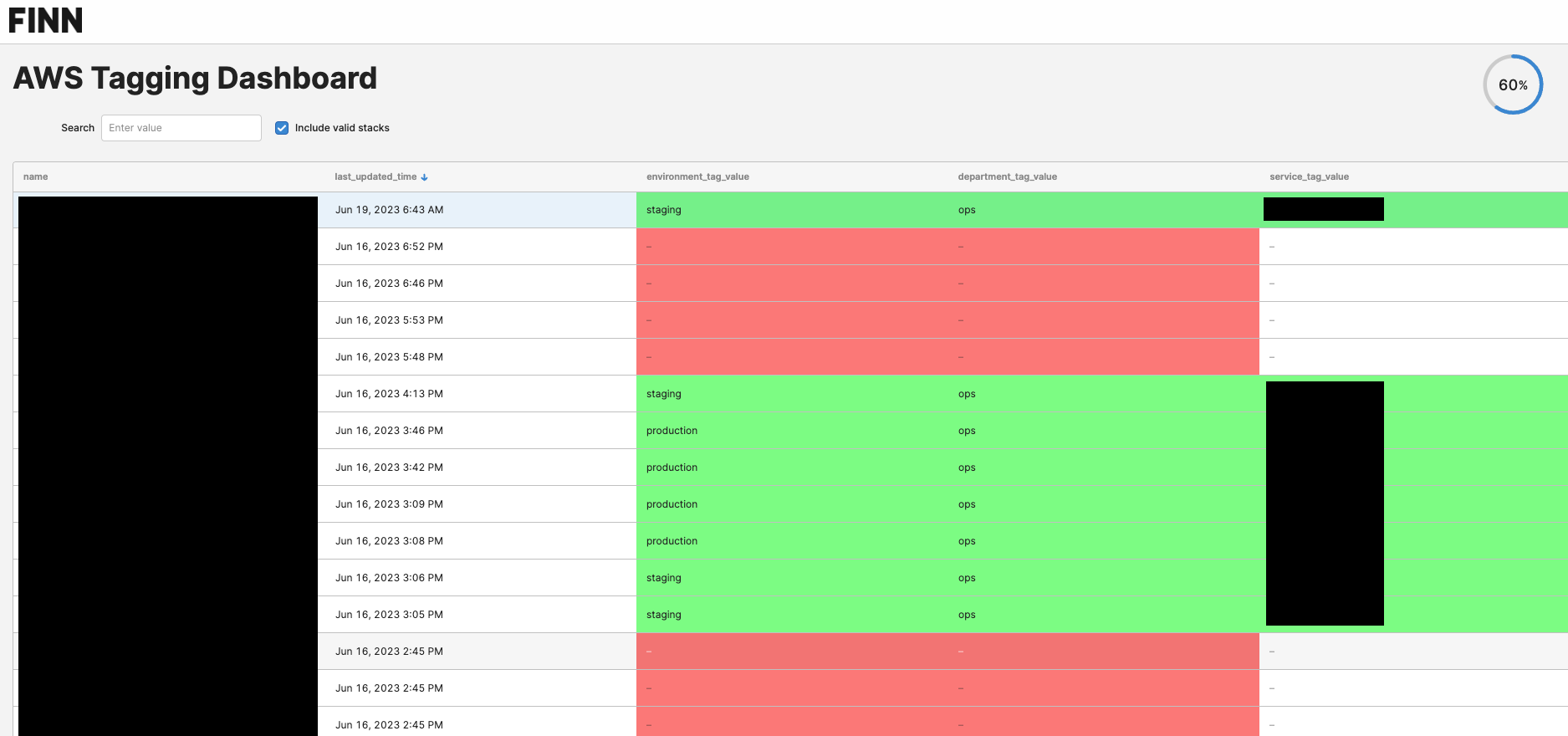
Screenshot of Tagging Dashboard
To build a dashboard like this, we need three things:
a way to obtain the numbers on how many active resources aren’t following the tagging policy
a database to store those numbers
a frontend that shows these relevant numbers In this blog article we'll focus almost exclusively on (1), namely how to obtain those numbers. But we'll quickly outline the overall approach right now.
We knew from the beginning that we can obtain the data we need using a Steampipe query. In essence, it's just one command that fetches the data across all AWS CloudFormation stacks from all accounts. We then push this data into a PostgreSQL database and visualize it in a Retool app. This approach is pretty straightforward and doesn't really make for a blog post, but the devil's in the details.
It was pretty easy to run the query locally, feed the data into the database, and then visualize the data. The question that came up was: How can we have fresh data continuously? It doesn't need to be live, but at least be refreshed hourly, or a few times a day. We will have a look at some possible alternative ways to do this in the next section.
Alternatives
As is often the case in engineering, there are many possible ways to tackle this problem.
Steampipe on an EC2 instance
The first one is running Steampipe on a designated EC2 instance. The advantage is that this is well documented and should be simple to setup. The disadvantage is that you now have one more VM running. At FINN we are trying to keep our cloud setup as serverless as possible.
Steampipe on AWS Lambda
It might also be possible to run Steampipe on AWS Lambda. We haven't tried this and there might be some issues and additional hurdles to take. For example, the image needs to implement the Lambda Runtime API. Also, if at some point we want to convert the service from a scheduled task to a long running service, then Lambda is not the right choice. The one thread limit might also pose problems.
Steampipe on AWS ECS with Fargate
Similar to running Steampipe on AWS Lambda there is the option to run it on AWS ECS with Fargate. ECS allows you to run any kind of Docker image and doesn't impose additional requirements, as Lambda does. And with Fargate you still don't have to spin up a VM for it. Thanks to the serverless design, you don't need to think about that part of the architecture. For these reasons we have decided to go with this approach and we'll cover the architecture in the next section.
Bonus: Steampipe Cloud
Also worth mentioning: Steampipe Cloud is a SaaS option that allows running queries in the cloud. It might be an option for you as well. We haven't tried it (yet).
Architecture
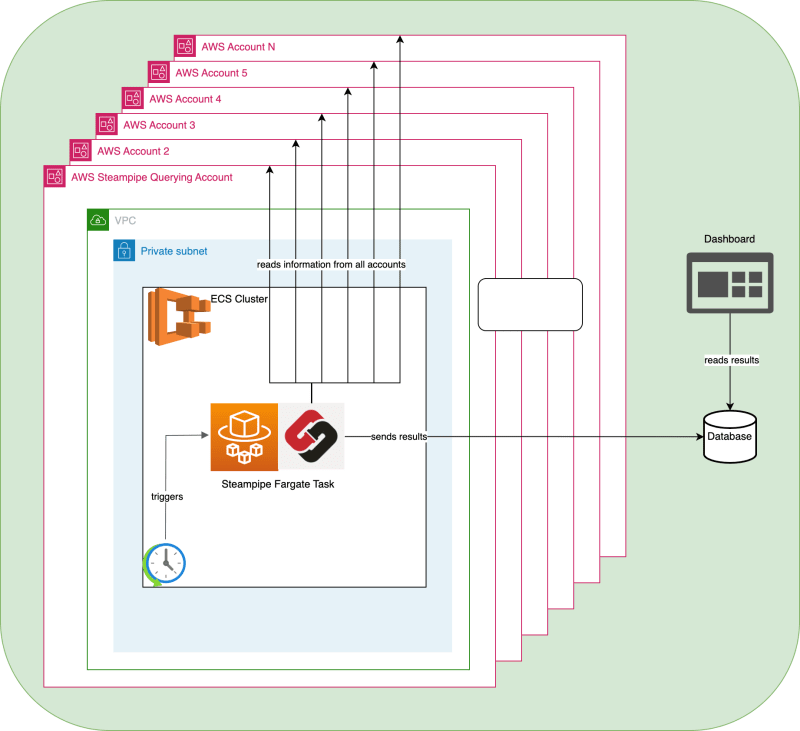
Overview of Steampipe Fargate architecture
Let's go through the main parts of the architecture as depicted in the architecture diagram. You can see a number of AWS accounts that make up our organization. In one of the accounts there is a Virtual Private Cloud (VPC) that contains a private subnet. For security reasons the ECS cluster where our tasks run, is in that private subnet. There is no need for our cluster to be reachable from the outside. Also you might notice that there is no load balancer. Our task doesn't have to be reachable from the outside, since it pushes the information based on a schedule.
The task execution is triggered by CloudWatch Events. We will later see how this can be trivially set up through a Cloud Development Kit (CDK) pattern class. When the task runs, the most interesting part of the process happens. The task role has the permission to assume a Steampipe query role in all other accounts, and also has all the necessary permissions in the account we are querying from. This allows the task to read data from across all accounts, as needed by the Steampipe query that the task runs.
In the end, the data is sent to a database. In our specific case the database lives in a different AWS account, but it can also be a database managed in a different place, so in the diagram we simplified it. A dashboard can now read the data from the database and show it to the user.
Challenges
During the implementation of this project we went through a huge amount of redeploys to debug and fix problems that came up on the live system. Describing the main challenges is thus one of the main motivations behind writing this blog post. We hope that it will save you some time and nerves to read about these challenges here, instead of having to experience them one-by-one during implementation.
Query All The Things
Since most larger (and also many smaller) organizations are using multiple AWS accounts, we want to be able to query all accounts at once. AWS even recommends using multiple accounts, so this requirement is very relevant for most AWS users. But using multiple accounts makes things more complicated when it comes to the Steampipe setup.
We recommend first trying to get Steampipe querying running locally. The Steampipe documentation has a designated page on using Steampipe CLI with AWS Organizations. There are some helper scripts that help you bootstrap the ~/.aws/config and ~/.steampipe/config/aws.spc configuration files. We will also revisit those scripts later, because they can also help us with the setup on Fargate, when we modify them a bit. For the local setup we can pretty much use them as-is. We might only need to remove the management account from the list of generated config entries.
To enable cross-account queries from your local machine, you need to do the following:
Create a cross-account role. We deploy it to all our accounts via CloudFormation StackSets.
Make sure that the role you created has policies attached that grant all the required access needed for your Steampipe queries.
Log in to AWS CLI with a role that is allowed to assume the cross-account role. We use SSO, so it's:
aws sso login --profile <yourprofile>Run
generate_config_for_cross_account_roles.shfrom the Steampipe samples repository as documented and attach the generated AWS configuration entries to your config. You might need to remove the generated entries for the management account that you are running the queries from.Run a query with
steampipe queryand make sure that there are results for all your accounts when applicable.
So far so good. This is not simple, but also not very hard to figure out, since there is ample documentation available. In the next section we'll up the ante a bit, because running this cross-account setup on AWS Fargate does not work out of the box.
Cross-account queries on ECS
One of the biggest challenges was trying to understand how Steampipe can leverage the cross-account role from an ECS/Fargate task. Since the same principles apply for both EC2-run and Fargate-run ECS tasks, we will just refer to "ECS task" from now on.
Initially, we just assumed that the "EC2 Instance" documentation would also work for ECS, and that as such we could use the IMDS parameter (for the Instance Metadata Service) in the helper script. That assumption was wrong. When you use the parameter entries, they should look like the following example in the AWS config file:
[profile sp_fooli-sandbox]
role_arn = arn:aws:iam::111111111111:role/security-audit
credential_source = Ec2InstanceMetadata
role_session_name = steampipe
But we need a different credential_source: EcsContainer.
So we modified the helper script and created a custom version for our project that always uses this credential source and also handles the management account correctly. An excerpt of the helper script:
[...]
if [ $ACCOUNT_NAME == "managementaccountname" ] ; then
cat <<EOF>>$SP_CONFIG_FILE
connection "aws_${SP_NAME}" {
plugin = "aws"
profile = "default"
regions = ${ALL_REGIONS}
}
EOF
continue
fi
# Append an entry to the AWS Creds file
cat <<EOF>>$AWS_CONFIG_FILE
[profile sp_${ACCOUNT_NAME}]
role_arn = arn:aws:iam::${ACCOUNT_ID}:role/${AUDITROLE}
credential_source = EcsContainer
role_session_name = steampipe
EOF
[...]
To give something back to Steampipe, we have created two pull requests on GitHub to:
(a) extend the script so it can output the correct configuration out of the box, and
(b) modify the documentation of the cross-account setup script to include information about running the script in ECS and fixing some minor inconsistencies in the existing sections.
You can find the PRs for documentation here and for the script itself here. If you are lucky, Steampipe has are already merged these PRs by the time you are reading this, and your life just got a bit easier :) One thing you will most likely still need to do is remove or adjust the entries for the main account that you are running Steampipe from. In our case we slightly adjusted the script to skip config generation for that account based on name.
Running it periodically
Now we've seen a lot of configuration magic. But how can we actually run and deploy Steampipe with Fargate on ECS?
Docker image
Since we decided to go with ECS, we need to build a Docker image that is then run periodically and executes the query. This is the Docker image that supports both AMD64 and ARM64 architectures:
FROM ghcr.io/turbot/steampipe:0.20.2
ARG TARGETPLATFORM
# Setup prerequisites (as root)
USER root:0
RUN apt-get update -y \
&& apt-get install -y git wget curl unzip
RUN if [ "$TARGETPLATFORM" = "linux/amd64" ]; then ARCHITECTURE=amd64; elif [ "$TARGETPLATFORM" = "linux/arm/v7" ]; then ARCHITECTURE=arm; elif [ "$TARGETPLATFORM" = "linux/arm64" ]; then ARCHITECTURE=aarch64; else ARCHITECTURE=amd64; fi && \
if [ "$ARCHITECTURE" = "amd64" ]; then curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"; else curl "https://awscli.amazonaws.com/awscli-exe-linux-aarch64.zip" -o "awscliv2.zip"; fi && \
unzip -qq awscliv2.zip && \
./aws/install && \
/usr/local/bin/aws --version
# Install the AWS and Steampipe plugins for Steampipe (as steampipe user).
USER steampipe:0
# Create workspace and copy cross-account util script
WORKDIR /workspace
COPY generate_config_for_cross_account_roles.sh .
COPY run_query.sh .
ENTRYPOINT [ "/bin/bash" ]
CMD ["./run_query.sh"]
The interesting parts about it are:
AWS CLI v2 is installed based on the chosen architecture.
It took a while to figure out that we need to include
ARG TARGETPLATFORMso that dockerx actually passes that argument in the build.Both the custom cross-account setup script and a
run_query.shscript are copied over.
The run_query.sh script performs some initialization, if needed, and runs the query:
#!/bin/bash
set -e
# Preparation if needed
if [ ! -f ~/.aws/config ]
then
echo "AWS config wasn't initialized yet. Setting up"
mkdir -p ~/.aws
./generate_config_for_cross_account_roles.sh SteampipeQueryRole ~/.aws/config
echo "Cross Account Setup complete. Installing steampipe AWS plugin"
steampipe plugin install steampipe aws
echo "Install steampipe aws plugin"
else
echo "AWS config has already been initialized. Skipping setup"
fi
echo "Running query: ${STEAMPIPE_QUERY}"
steampipe query --output json "${STEAMPIPE_QUERY}" > result.json
curl -X POST -H "Content-Type: application/json" -d @result.json ${TARGET_WEBHOOK}
In the end the data is pushed to a webhook that we can define via an environment variable (or AWS Secret). This part of the implementation is currently not very advanced, and there is some potential to extend and improve. This post covers this implementation and possible improvements in some more detail further down below.
CDK
How about deploying it? At FINN we are using AWS CDK as our go-to IaC tool. CDK actually provides a very nice pattern called ScheduledFargateTask that allows us to quickly define a Fargate task that is run on a schedule defined by us.
This is a slightly simplified stack implementation. Don't worry, we'll go through the important parts resource by resource:
class SteampipeFargateStack(Stack):
def __init__(self, scope: Construct, construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
service_name = "steampipe-fargate"
repository: ecr.IRepository = ecr.Repository(
self, f"{service_name}-ecr-repo", repository_name=service_name
)
cluster = ecs.Cluster(
self,
f"{service_name}-cluster",
cluster_name=f"{service_name}-cluster",
container_insights=True,
)
task_role = iam.Role(
self,
f"{service_name}-task-role",
role_name=f"{service_name}-task-role",
description="Allows read access to all accounts for querying via steampipe.",
assumed_by=iam.ServicePrincipal("ecs-tasks.amazonaws.com"),
inline_policies={
"AllowSteamPipeAccess": iam.PolicyDocument(
statements=[
iam.PolicyStatement(
effect=iam.Effect.ALLOW,
actions=["sts:AssumeRole"],
resources=["arn:aws:iam::*:role/SteampipeQueryRole"],
),
iam.PolicyStatement(
effect=iam.Effect.ALLOW,
actions=[
...
],
resources=["*"],
),
]
)
},
managed_policies=[
iam.ManagedPolicy.from_aws_managed_policy_name(
"job-function/ViewOnlyAccess"
)
],
)
task_definition: ecs.FargateTaskDefinition = ecs.FargateTaskDefinition(
self,
f"{service_name}-taskdefinition",
family="task",
cpu=512,
memory_limit_mib=2048,
task_role=task_role,
runtime_platform=ecs.RuntimePlatform(
operating_system_family=ecs.OperatingSystemFamily.LINUX,
cpu_architecture=ecs.CpuArchitecture.ARM64,
),
)
task_definition.add_container(
f"{service_name}",
image=ecs.ContainerImage.from_ecr_repository(
repository=repository, tag=VERSION
),
cpu=512,
memory_limit_mib=2048,
logging=ecs.LogDrivers.aws_logs(
stream_prefix=service_name, log_retention=logs.RetentionDays.ONE_MONTH
),
environment={
"STEAMPIPE_QUERY": "SELECT name, id, last_updated_time, tags, tags ->> 'environment' as environment_tag_value, tags ->> 'department' as department_tag_value, tags ->> 'service' as service_tag_value FROM aws_cloudformation_stack WHERE extract(day from current_timestamp - last_updated_time)::int < 90;",
},
)
ecs_patterns.ScheduledFargateTask(
self,
f"{service_name}-scheduled-fargate-task",
cluster=cluster,
platform_version=ecs.FargatePlatformVersion.LATEST,
scheduled_fargate_task_definition_options=ecs_patterns.ScheduledFargateTaskDefinitionOptions(
task_definition=task_definition
),
schedule=appscaling.Schedule.cron(minute="50"),
)
The first two resources are a bit boring. The repository stores our Docker image and the ECS cluster is needed to logically contain our scheduled tasks. We don't add any EC2 instances to the cluster though, as we are only running the task serverless via Fargate.
The task role is where things get interesting. This is the role that our task can assume as declared by assumed_by. The task role has some policies attached, including one that allows assuming the cross-account role called SteampipeQueryRole. The rest of the permissions are needed to actually also allow Steampipe to query information for the management account.
Next we need a task definition. Here we specify some of CPU and memory limits. Specifying those limits is very important when working with Fargate, as they define what kind of VM is used in the background. When we went with smaller limits the task actually ran into the memory limit and crashed. So 2048MB seems to be a good limit for our environment. We also decided to go with ARM64 architecture, because cost will be a bit lower and why not? In the next step, we then need to add our only container to the task definition. Here we can also define environment variables and secrets.
The last part of the stack is the most powerful. It's a pattern that creates all the necessary resources to run a scheduled Fargate task. Here we are just referencing some of the resources defined above, and set the schedule for the task to run at.
You are wondering how we are running CDK? Going into detail would go beyond the scope of this article, but to summarize it: We are using Github Actions. We connect to AWS using OpenID connect, so that we don't need to store any (secret) access keys in the Github repository settings. We then run cdk diff for PRs and cdk deploy on the protected main branch. We assume different roles for PRs (read-only) and main branch (write permissions).
Debugging Steampipe on Fargate
While running into the issues described above, we struggled to gather the information that would help us solve them. In some cases the Steampipe query in the Fargate task just ran for 8 minutes and then timed out, without any output. In this section we want to share a few tricks for finding out what's going on.
The Steampipe CLI didn't allow us to activate additional logging to the console--at least as far as we were able to tell. But it actually writes log files that we can use to find out more. So there is a simple first thing you can do, if you ever run into issues with Steampipe without any console error output: just make sure to run the following line after your steampipe query:
tail -n +1 ~/.steampipe/logs/*
If you've configured your Fargate task to write to a CloudWatch log group, you can then find all the output with an additional line with each file name in those logs. This helped us tremendously, especially when debugging issues regarding assuming the role for cross-account queries. To build upon this, it's probably also possible to just stream the newly appended lines directly to stderr. Then it will show up live while the Steampipe command is still running. We didn't spend the time to implement it in our Docker image, since we just needed it for temporary debugging.
Possible next steps
Our solution works, but it is not super sophisticated in all areas. As mentioned earlier, we could enhance it with a framework to be able to supply it with a collection of queries and sinks where the data should be sent, and also potentially specify what format it should be. It could be possible to create multiple scheduled tasks using the same Docker image. That way, each query can have a custom schedule. But if it's okay to run them all at the same cadence, then the queries could also run in the same task. That would have some benefits: Initial setup is only done once, and subsequent queries might be sped up based on the queries that came before them.
At a certain point it might make sense to actually run the task continuously and use Steampipe in its service mode. We could open up a protected interface to that Steampipe service from the outside, and could then directly perform queries from other components in our infrastructure and SaaS landscape. Or we could start up very lightweight Lambda functions that run queries against the service and push the data where it needs to go. There is probably a certain break-even point where it makes sense to run Steampipe in service mode, but we don't think we have reached it yet.
Summary
In this post we've shown how it's possible to run cross-account Steampipe queries in scheduled AWS Fargate tasks. While the initial setup didn't go super smooth early on, we hope that this blog post will provide some helpful guidance should you want to build something similar. For us the solution has been running stable for the last few weeks since taking it live. We are confident that we'll build upon this approach to tackle future challenges going forward. Also, up to this point, we didn't really have to build any software from the ground up, but just had to make sure that we were able to wire everything together correctly. Now we can benefit from great tools like Steampipe that help us understand our own cloud landscape better.
This article was written by Frederik Petersen.
Subscribe to my newsletter
Read articles from FINN directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
FINN
FINN
We make mobility fun and sustainable