Design of Fault-Tolerant Virtual Machines
 Samuel Sorial
Samuel SorialTable of contents
In some situations where failure is caused by a hardware failure, it's useful to have replication in hand. There are other types of failures that can't be resolved with replication, such as software bugs or network issues. In this article, we deal with hardware failure in order to build fault-tolerant virtual machines. Discussing how VMware built their vSphere to make their virtual machines fault-tolerant.
Replication Schemes
One interesting replication method is doing it in a primary backup scheme. In which a backup is always ready to take the primary's role when the primary is down. In this case, keeping the state of the primary and backup in sync is crucial. And outside world doesn't notice the switch from primary to backup in case of a failure.
State Transfer
In this scheme, the state of the primary is sent over the network to the backup. Including all CPU, memory, and I/O state, which uses too much bandwidth. Also, there's some complexity in taking checkpoints and applying them correctly without hurting the user experience.
Replicated State Machine
In this scheme, primary and backup start with the same state, applying the same instructions in the same order, which guarantees to have the same state in both of them. However, execution has some indeterministic operations that invalidate our theory. Like get time operation, for sure it will give 2 different outputs because it gets executed on primary before backup.
Indeteremnistic operations limitation can be resolved by applying the protocol at the Virtual Machine level because every operation is monitored by the virtual machine, it can capture those operations and outputs, and pass them to the backup which uses them instead of re-executing those indeterministic operations.
This scheme has lower bandwidth requirements than state transfer, which makes it ideal for physically separated machines, providing stronger fault tolerance.
FT Design
The basic setup of FT is to have primary-backup machines, sharing access to a shared disk in the same network. With a logging channel between them, only primary announces about its presence. Nobody knows about the backup other than the primary and clustering service that detects failures and deals with them.
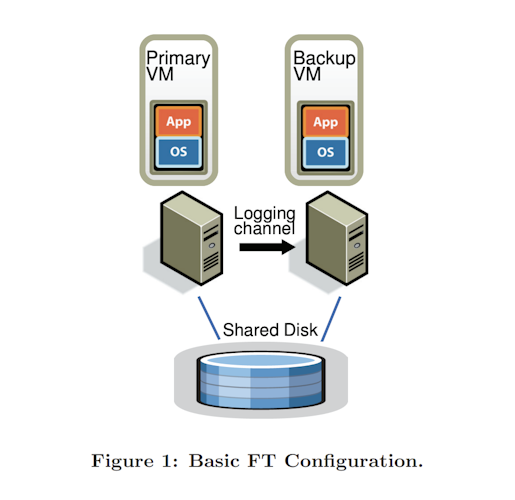
All the inputs that the primary receives are forwarded to the backup, and only the primary output is shown to the client. The hypervisor drops the output of the backup unless it's promoted to become primary. Also, the design takes care of the split-brain problem cleverly.
Note: This article discusses the implementation that supports uni-processors only (the original paper was published in 2010). Currently, vSphere supports multi-processors too.
Deterministic Replay
Even the execution of the simplest useful program that you can imagine is not 100% deterministic, events happen all time, and indeterministic operations are commonly used, those are the real challenge when implementing deterministic replay protocol. It can be handled by: capturing all input and non-determinism, applying those in the same order on the backup, and doing so without hurting performance.
To do so, the backup machine has to be lagging 1 message behind the primary, to allow the primary hypervisor to capture interrupts, and send them along with the operation that it interrupted.
Note that not all operations are forwarded, only the input and non-deterministic operations with their output, which reduces the bandwidth needed for FT to run correctly.
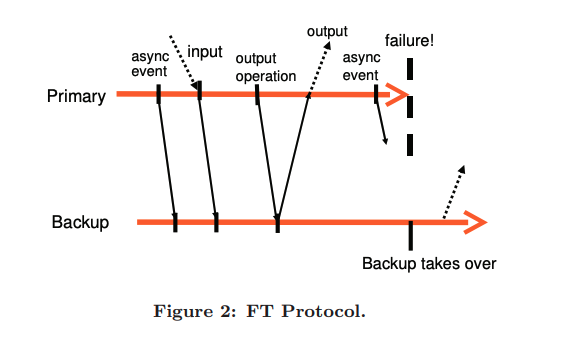
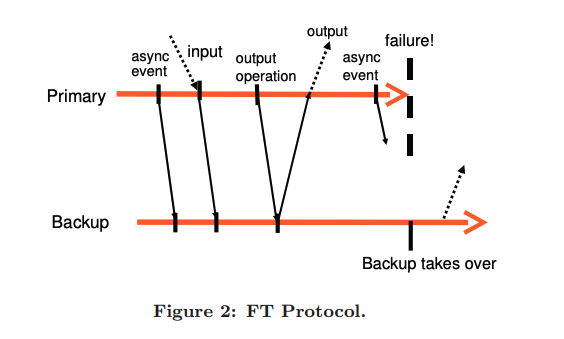
FT Protocol
Using the logging channel, the primary can send the deterministic replay operations to the backup, backup executes those operations in real-time which gives the same state. It's crucial to add some roles that guarantee our fault tolerance.
Output Requirement: if backup takes over a failure of the primary, the backup will continue executing in a way that's consistent with all outputs that the primary sent to the client.
When the backup starts taking over the primary, it's expected to have some indeterminism while executing commands with a slightly different state, but as long as it's consistent with the primary's previous outputs, it's acceptable.
Imagine a scenario where a primary just executed output and failed, it didn't send that in the logging channel, so the backup will execute commands and go live sending the output to the client. If the output is the same network protocols can deal with it. But what happens if the backup had some indeterministic operation (interrupt) before sending output? This might affect the output, hence sending 2 different outputs to the client for the same operation!
To solve the previous problem, the output requirement is enhanced by allowing the primary to send output after it had already sent that on the logging channel, and the backup acknowledged it has received it.
Detecting Failures
There are two main ways of detecting a failure of primary/backup. The traditional way is to use heartbeats, the other way is to monitor the traffic of the logging channel and detect if there are no logs/acks from a specific machine. As interrupts happen often, it's not expected from the primary to stop sending logs for a long time!
Both of those ways are suspectable to the split-brain problem, where the machines are separated from each other and each one thinks it's the master. To prevent this issue, the shared disk is used to coordinate who is becoming primary. To become primary, the machine tries to test-and-set a value atomically. If this operation fails, then there's already a primary performing, and this machine will halt itself.
Implementation
Starting & Restarting VMs
In order to make this replication scheme correct, it's crucial to find a suitable way to start VMs from the same state. This can be used to start primary and backup at the beginning of the execution, and any later need to start a new backup in case of primary failure.
For VMware, they adapted their VMotion product that allows migration of running VM on a remote server, but without destroying the VM that's being cloned. Also, a clustering service is responsible for choosing which machine to be started as a new backup, any machine that has access to the shared storage can be chosen. This machine typically is ready and started replaying within a few minutes.
Managing The Logging Channel
The logging channel can be optimized to reduce any latencies in execution. One way to do so is to have a large buffer for entries on each machine. As the primary executes operations, it adds entries to that buffer, and similarly, the backup consumes entries from its buffer. Primary flushes content as soon as possible, and backup reads those entries to its buffer when they arrive, sending back acknowledgments.
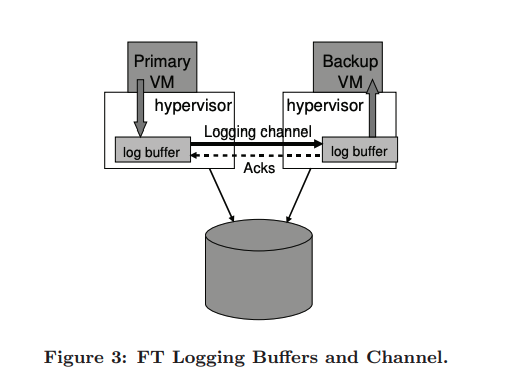
If the backup faces an empty buffer, it stops execution immediately, to prevent any indeterminism. Later, it starts again when it has any available entries, this stop doesn't affect the clients because it's not on the primary. However, on the primary side, if it faces a full buffer, it must stop execution until that buffer is flushed. This stop slows down the primary VM when it produces entries at a higher rate than the backup consumes them, and it affects the clients waiting for the response.
We don't want to stop the primary too much, so both machines should run on nearly the same hardware giving the same speed. In addition to avoiding those delays, we don't need the buffer to be too big. As this lags the backup when it decides to take over the primary. Since it needs to replay all entries on the buffer before start producing output.
To keep sure that both machines are working at the same speed, some data is sent in heartbeats that enable the usage of a feedback loop, in which machines try to reach the same CPU speed. If the backup is lagging, the primary slows down execution until it reaches nearly < 100ms.
Operations & I/O
In general, most operations are only initiated on primary, then FT will send proper instructions to the logging channel to replicate it on backup. The only operation that's done independently is VMotion. They can be moved to other hosts without the need to replicate on another machine. For primary, the backup must disconnect from the source and then re-connect to the new destination. For the backup, VMotion requires all I/O operations to be completed before switching. However, there is no easy way to cause all I/Os to be done at this point since the backup keeps replaying what's done on the primary. This problem is resolved by requesting to stop the primary I/Os via the logging channel at the end of the clone and resuming it after finalizing this migration.
For disk operations, given that they are non-blocking, they can execute in parallel. Accessing the same disk locations can lead to in-determinism. Also, the implementation uses DMA to/from VMs. To prevent any unwanted behavior, it detects any I/O races and forces those racing to execute sequentially in the same way on the backup.
For network operations, the code that asynchronously updates VM ring buffers with incoming packets was modified to force the guest to trap to the hypervisor where it can log updates and apply them to VM. To optimize networking, it's crucial to reduce the delay for transmitted packets. The key is to reduce the time needed to send and ack log entries. The way to achieve it is to do that without any thread context switch, by allowing functions to be registered with a TCP stack that will be called from a deferred-execution context whenever a TCP packet is received.
Design Alternatives
Shared VS Non-shared Disk
The default design uses a shared disk, so the disk is naturally accessible when there's a failure on the primary. Also, the shared disk is used externally, so only the primary VM can do actual writes to the disk.
Another way to implement FT protocol is to use the non-shared disk. In this, each VM does all writes to its virtual disk, and in this case, the disk is considered part of the machine state that needs to be replicated. This can be useful in situations where a disk can not be shared between machines and removes the output requirement that we mentioned earlier. Also, this allows machines to run in totally separate locations, improving our FT.
One main disadvantage of it is that disk needs to keep in sync when the machines start, adding more complexity to VMotion.
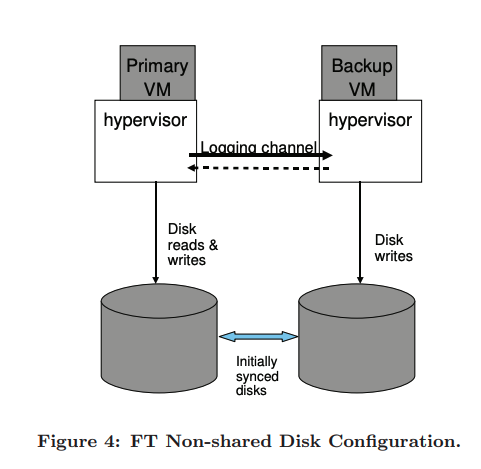
If this scheme is used, our default solution to split-brain is not usable because they don't share disk, so another third-party service is used to determine which machine becomes primary.
Executing Disk reads on Backup
In the default implementation, backup never reads from its virtual disk, since it's considered an input, it should get it from the logging channel sent by the primary. An alternative to it is to allow backup to read from disk, reducing entires of logging channel and reducing bandwidth needs for it, however, this requires sync with primary to keep sure it finishes its read before the backup or we will have indeterminism. Also, failed disk read operations might be a huge problem, because an operation that succeeds on primary is not guaranteed to succeed on backup. Also, if the primary operation fails, it needs to sync the memory to backup too!
Also, there might be some concurrency problems, but they can be detected and handled correctly. This way is more suitable for situations where bandwidth is a bottleneck.
References
This case study is created after careful reading of: The design of a practical system for fault-tolerant virtual machines, if you think there's anything wrong please contact me.
- Andrew, T., Keshav, S., & Freedman, M. J. (2010). The design of a practical system for fault-tolerant virtual machines. ACM SIGOPS Operating Systems Review, 44(2), 18-35. https://doi.org/10.1145/1899928.1899932
Subscribe to my newsletter
Read articles from Samuel Sorial directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Samuel Sorial
Samuel Sorial
A software engineer who is enthusiast about back-end engineering and system design with a flexible mindset. I love playing with frameworks and moving between the languages just like an artist playing