Filter Apache Kafka Messages on the Fly with ksqlDB
 Firat Komurcu
Firat Komurcu
In this blog post, we will talk about what ksqlDB is. ksqlDB is a streaming SQL engine for Apache Kafka.
If you want to learn via video, here is the Youtube video of this blog post:
ksqlDB is scalable, elastic, fault-tolerant and supports various streaming operations like data filtering, transformations, aggregations, joins, windowing, etc. A stream is a topic but with a schema declared. Let's dive in and create a stream, publish some events, and process them on the fly.
Note: If you want to run commands along with me, you can find the files and commands in my GitHub profile.
I want to show you my Docker Compose file before we start creating a stream. Let's see what's inside our Docker Compose file. We have:
Zookeeper
Apache Kafka
ksqlDB server and client
AKHQ (Apache Kafka HQ). It's an open-source Kafka UI, and we will see the topic messages and publish some events via this UI.
---
version: '2'
services:
zookeeper:
image: confluentinc/cp-zookeeper:7.2.0
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
broker:
image: confluentinc/cp-kafka:7.2.0
hostname: broker
container_name: broker
depends_on:
- zookeeper
ports:
- "29092:29092"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker:9092,PLAINTEXT_HOST://localhost:29092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
ksqldb-server:
image: confluentinc/ksqldb-server:0.28.2
hostname: ksqldb-server
container_name: ksqldb-server
depends_on:
- broker
ports:
- "8088:8088"
environment:
KSQL_LISTENERS: http://0.0.0.0:8088
KSQL_BOOTSTRAP_SERVERS: broker:9092
KSQL_KSQL_LOGGING_PROCESSING_STREAM_AUTO_CREATE: "true"
KSQL_KSQL_LOGGING_PROCESSING_TOPIC_AUTO_CREATE: "true"
ksqldb-cli:
image: confluentinc/ksqldb-cli:0.28.2
container_name: ksqldb-cli
depends_on:
- broker
- ksqldb-server
entrypoint: /bin/sh
tty: true
akhq:
image: tchiotludo/akhq
environment:
AKHQ_CONFIGURATION: |
akhq:
connections:
docker-kafka-server:
properties:
bootstrap.servers: "broker:9092"
ports:
- 8080:8080
links:
- broker
Creating Our Initial Stream
Let's proceed to set up our ksqlDB server. To open ksqlDB, run the following command:
docker exec -it ksqldb-cli ksql http://ksqldb-server:8088
Now that we are in ksqlDB. First, let's create a stream together:
CREATE STREAM cities (
id BIGINT,
name VARCHAR,
population BIGINT
) WITH (
KAFKA_TOPIC='cities',
PARTITIONS=1,
VALUE_FORMAT='JSON'
);
Our stream is created. Let's check it with the following:
SHOW STREAMS;

And let's look at the details:
DESCRIBE cities;

Now, let's see our topic:
SHOW TOPICS;

Ok, so we have our stream and our topic. Our stream listens to our topic and creates an unbounded series of events.
Inserting Events and Querying The Stream
We can insert events in two ways: inserting an event directly into the stream or publishing data to the topic.
Let's insert data directly into the stream:
INSERT INTO cities (id, name, population) VALUES (1, 'Istanbul', 16000000);
We can query our stream in two ways. First is the pull query, where we select the data like it is a SQL database:
SELECT * FROM cities;

The other way is push query, where we listen to the stream until we stop. now, our consumer is listening to the city's stream and waiting for messages. Let's insert more data:
INSERT INTO cities (id, name, population) VALUES (2, 'Ankara', 10000000);
INSERT INTO cities (id, name, population) VALUES (3, 'Izmir', 3000000);

As we can see, our inserted data is showing up in our push query. We can use various operations like transformations, filtering, etc., with our city's stream.
Publishing Events To The Topic
Let's try the other way of inserting data by publishing it to the topic using the AKHQ Kafka UI.
{
"id": 4,
"name": "Izmir",
"population": 3000000
}

We can see the newly published data once we produce this message and check our terminal.
Advanced Use Case: Filtering, Transformations, And Complex Objects
Let's do some basic filtering by selecting the name of the cities with a population greater than 1 million:
SELECT name FROM cities WHERE population > 1000000 EMIT CHANGES;

As expected, our small city doesn't show up.
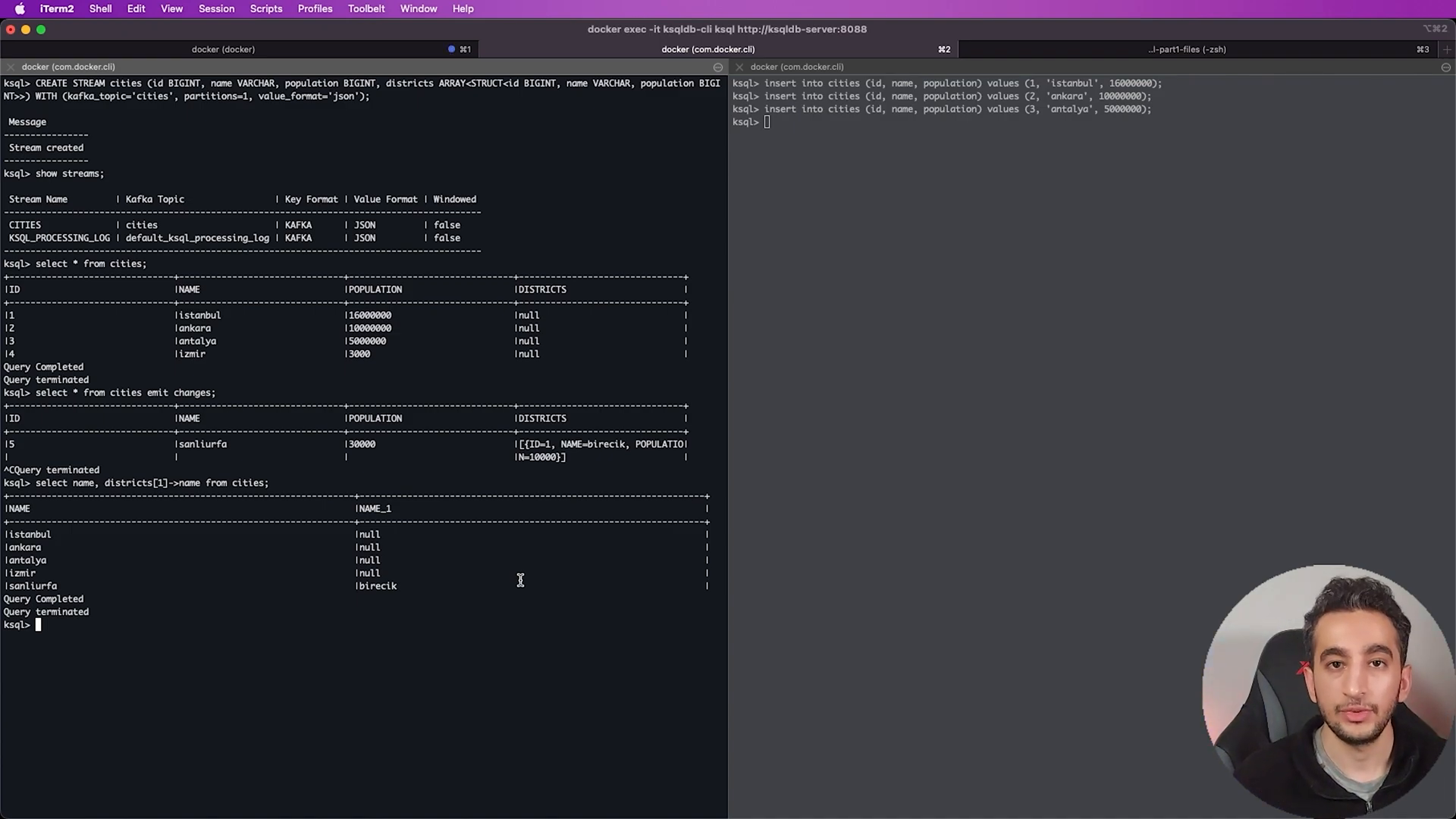
Now let's create a stream that has complex objects like arrays and structs:
CREATE STREAM cities (
id BIGINT,
name VARCHAR,
population BIGINT,
districts ARRAY<STRUCT<id BIGINT, name VARCHAR, population BIGINT>>
) WITH (
KAFKA_TOPIC='cities',
PARTITIONS=1,
VALUE_FORMAT='JSON'
);
With our new stream populated with complex objects, we can listen for even more data:
SELECT name, districts[1]->name FROM cities EMIT CHANGES;
Using ksqlDB For Preprocessing Data
For example, if we need preprocessed data from a topic, we can use KSQL DB to filter the data on the fly and sync that data to another topic.
Create a new stream, "big_cities," that listens to our "cities" stream
Filter the data based on a population greater than 1,000,000
Sync the filtered data to another topic called "big_cities"
CREATE STREAM big_cities WITH (
KAFKA_TOPIC='big_cities',
PARTITIONS=1
) AS SELECT * FROM cities WHERE population > 1000000 EMIT CHANGES;
Listen to our newly created stream:
SELECT * FROM big_cities EMIT CHANGES;
When we insert or publish data for big cities, it will show up in our filtered "big_cities" stream.

This is just the tip of the iceberg! ksqlDB has many features, but this is a good introduction to get started. Feel free to provide any feedback in the comments. See you in the next post!
May the force be with you!
References
Subscribe to my newsletter
Read articles from Firat Komurcu directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by