Fundamental Concepts on How IPFS Works
 Gino Osahon
Gino OsahonFundamental Concepts on How IPFS Works

In this article, we will learn about the different stages of how IPFS works, the different protocols and tools/concepts like Chunking, IPLD, UnixFS, IPNS Multipart, and others that are used at each of the stages. In this article, we will learn about the basics of the following:
How to import files on IPFS
Protocols
Chunking
UnixFS
IPLD
How to name files on IPFS
Protocols
CID
PATHS
IPNS
How to find files on IPFS
Protocols
Routing
DHT
Kademlia
How to fetch files on IPFS
Protocol
- Bitswap
Prerequisites
To follow along in this blog post, you should have some knowledge about
Peer 2 peer
Decentralized Networks
Distributed Networks
Hashing
Linked Data Structures
If you are not familiar with the above, it will be advisable to learn the basics by clicking the links above, before proceeding with this article on how IPFS works.
Overview
What is IPFS?

IPFS is an acronym for InterPlanetary File System, which is a protocol and network designed to create a content-addressable, peer-to-peer (P2P) method for storing, sharing, and accessing files, websites, applications, and data. The IPFS network is made up of nodes in a distributed file system.
IPFS uses a file-sharing model like BitTorrent to allow users to host and receive content. Any user in the network can serve a file by its content address, and other peers in the network can find and request that content from any node that has it.
In a P2P network, you do not need an intermediary to share and receive content with other peers in the network. When searching for content on IPFS, you would simply request it from a peer using the content identifier, and they will either respond with the content or pass along the request to peers who are 50 percent closer to the content. Eventually, someone will return with the content, if they have it saved.
IPFS aims to decentralize the web and connect people to information using content addressing instead of URLs and servers.
Read the documentation page for in-depth knowledge of IPFS.
To understand the different phases, flow, and protocols/tools that are involved in the process of how IPFS works, we would approach this article in a step-by-step manner, and try to explain each of the steps/protocols used in each phase as captured in the image below.
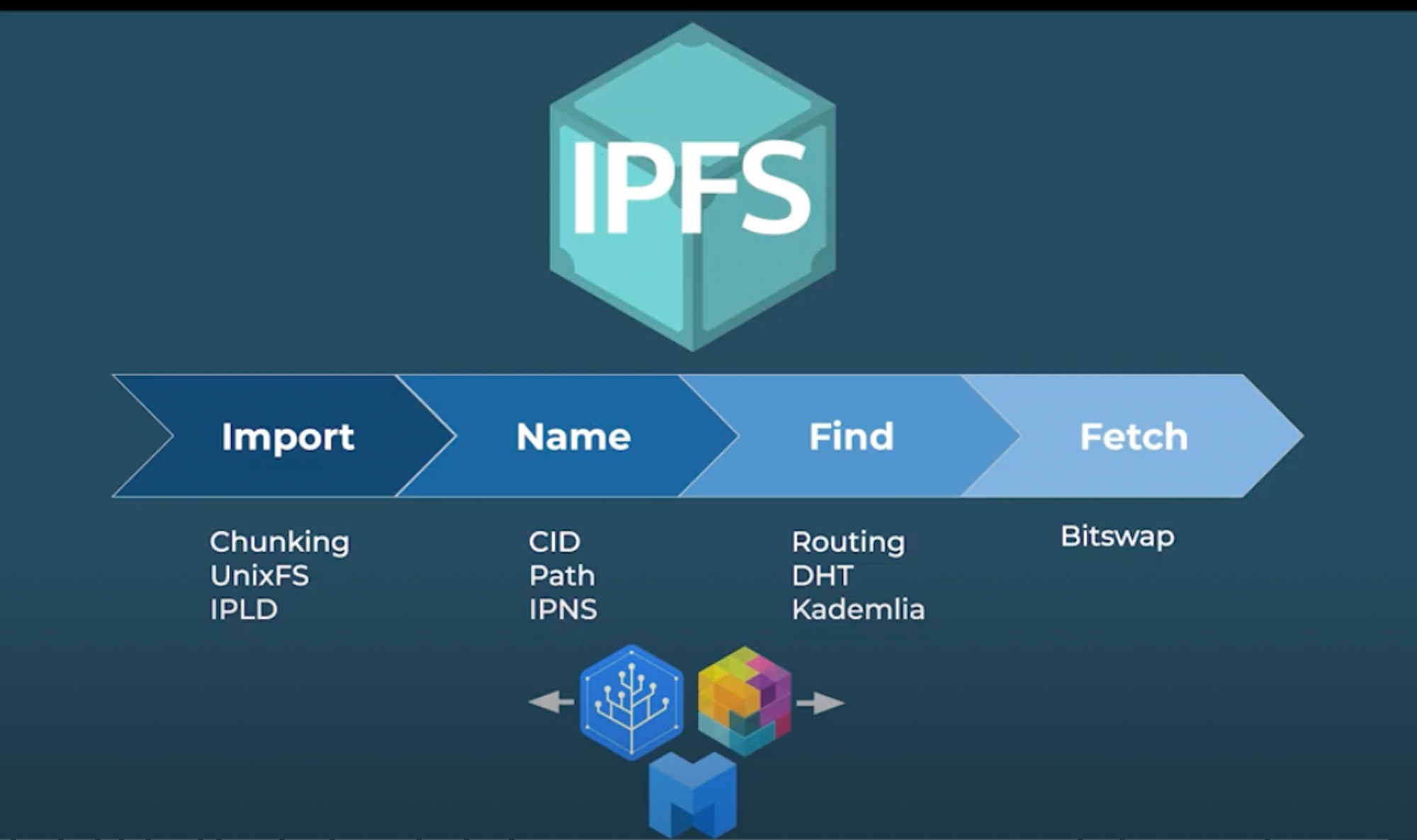
- How to import files on IPFS
When you are importing files to IPFS, there are steps that you must go through, like chunking files into pieces, compiling those pieces into files and directories, and then finally coding these files and directory objects into a data structure implemented in a Merkle DAG data structure and this is managed by IPLD. To gain a basic understanding of how we can import files on IPFS, let us learn about the following concepts:
1.1 Chunking files into smaller pieces

The first thing IPFS does when importing files is to break the file into chunks of data by using a chunking algorithm. When we upload a file to the IPFS network, IPFS takes the file, breaks it up into a collection of data chunks, spreads them across multiple blocks, and then links them together to form a single graph.
A Content Identifier (CID) is generated for each block, and the CID of multiple blocks is hashed to generate a new CID, which can be the root CID that you share with anyone that wants to access the files. The root CID is then stored on multiple nodes on the IPFS network. When anyone looks up the CID, the file can be fetched from different nodes that are currently storing it. Note that the slightest change to the file will generate a new CID, so the original content will always be available, and this ensures immutability. IPFS currently uses a size-based chunker, files are split into chunks of 256 kilobytes. You generally do not want your file chunks to be too small for performance reasons. It takes more time and overhead to download more chunks.
The concept of chunking allows for deduplication, piecewise transfer, and seeking.
Deduplication - IPFS uses the concept of deduplication to automatically save disk space. For example, when we import files, we may end up finding out that two pieces are the same. Since we’ve chunked it, we end up not storing the duplicated pieces and only storing the unique ones once. As you can see from the image below, only three pieces of the chunked files are saved because two of the chunked files are the same (Orange color).
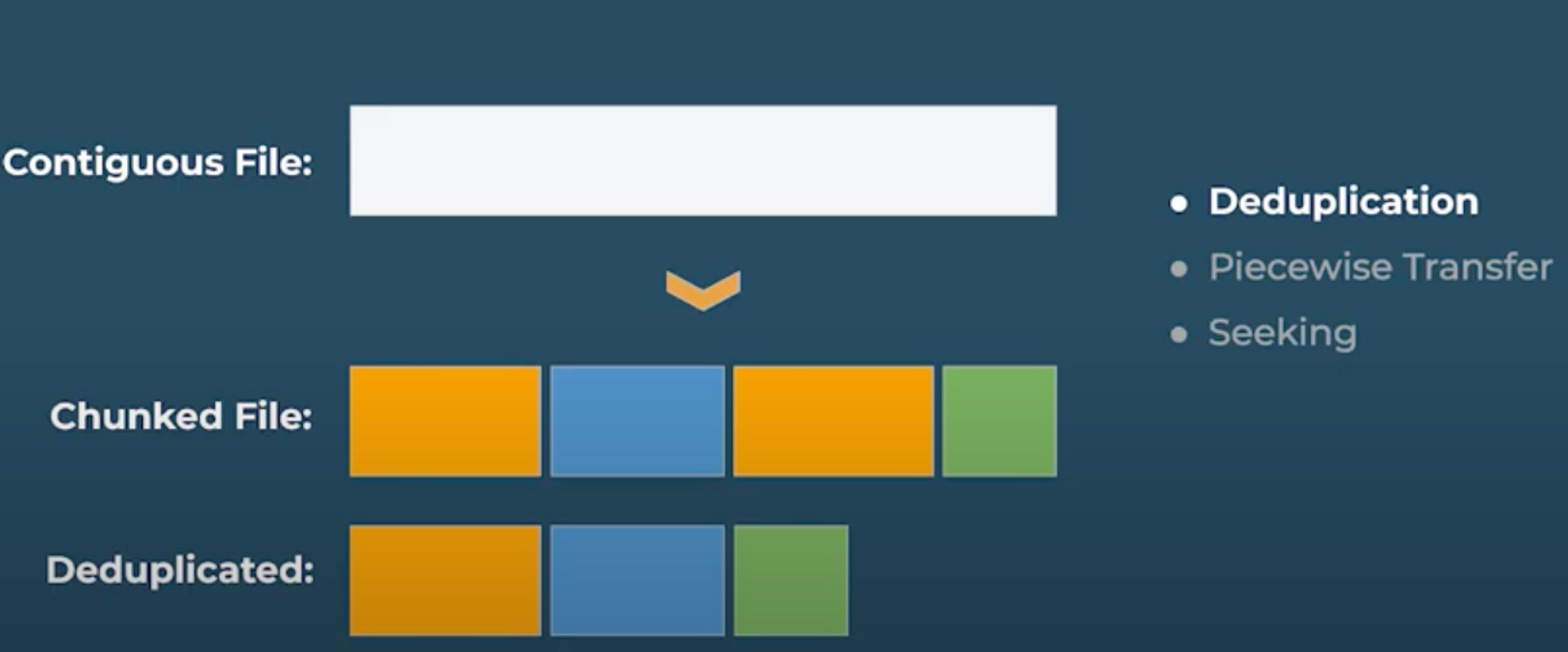
Another example is if I save a photo of my cat Lunar on the IPFS network through Piñata, I would receive a unique content identifier for that photo. If someone for any reason gets a hold of the same photo and saves it on the IPFS network, they would also receive the same hash/CID as mine. This allows multiple people to store the same content without multiplying the disk space used, which reduces overall storage and cost.
Piecewise transfer of files - This concept allows for the identification of corrupt pieces of a file without having to download the entire file. For example, we can keep fetching pieces, and immediately notice without fetching the entire files that a piece is bad, then stop and search for the correct piece from another peer on the network. This concept is way better than fetching the entire file and realizing that a piece is bad.
Seeking - Chunking allows us to seek a file, which means that instead of having to download the entire file for each of the pieces that we want, we can just bypass the pieces that we do not want and go for the pieces that we want.
1.2 UnixFS
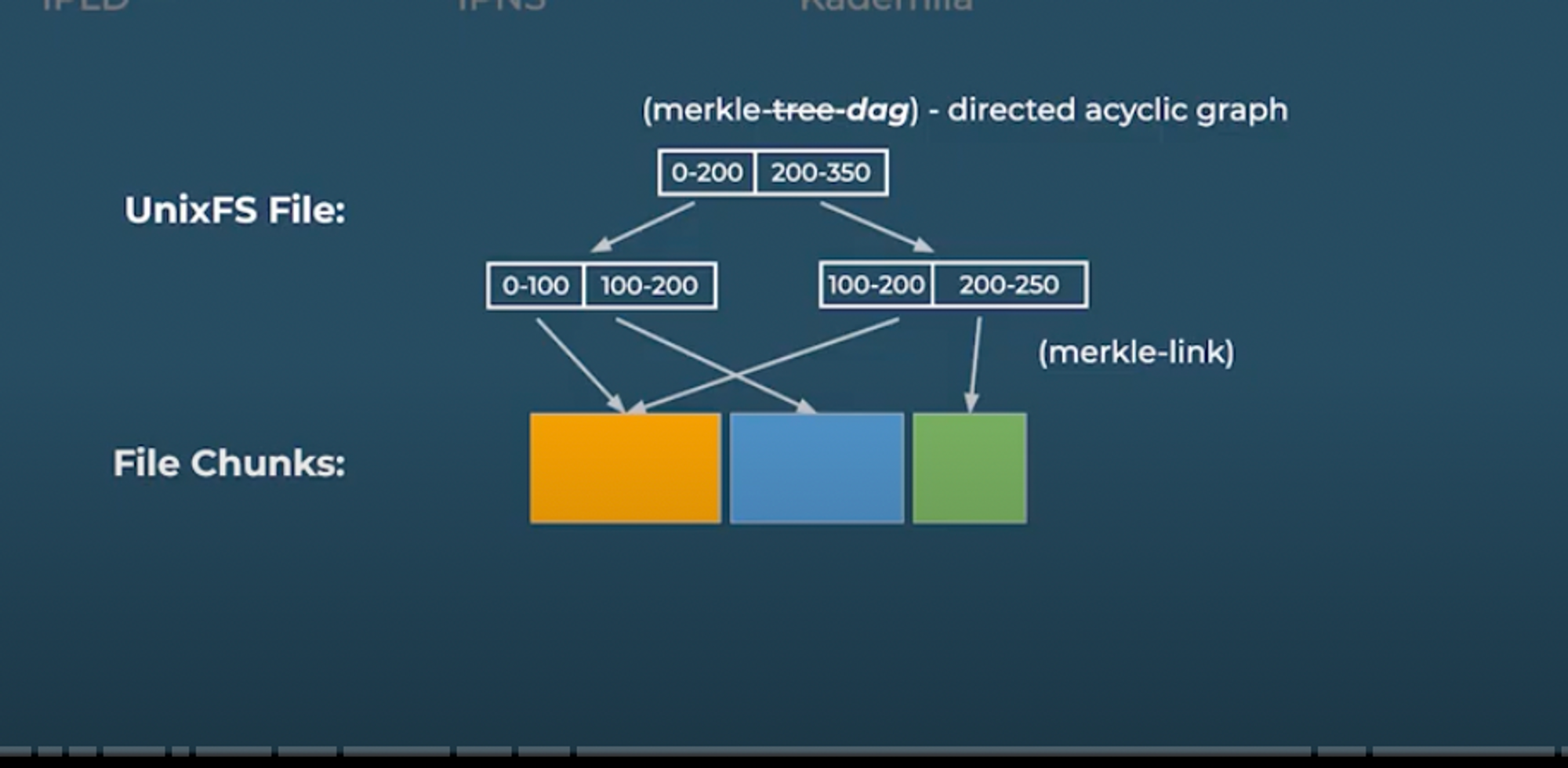
IPFS takes a file, breaks it up into a collection of data chunks, generates a content identifier, and reassembles the chunked pieces into a contiguous file through hashing, and for that IPFS creates a UnixFS file, which is actually a Merkle DAG representation of the file. IPFS UnixFS file is a directed acyclic graph (DAG) heavily inspired by the Merkle tree which keeps chunks of data connected and is used to represent a file object. It allows us to systematically organise our chunks and references similarly to a binary search tree. UnixFS solves the problem of being able to connect chunks of files together to get the original file.
A Merkle DAG is a tree where hashes point to data that points to other data using hashes, and it is different from a Merkle tree because a Merkle DAG can have two pointers pointing to the same data, as depicted in the image below. So Merkle DAG is the data structure that IPFS uses to store files, and this is what IPLD specializes in.
After creating the UnixFS files, the next step is to create a UnixFS directory, and we can do this by simply mapping file names to UnixFS files using hashes or Merkle links as depicted in the image below.
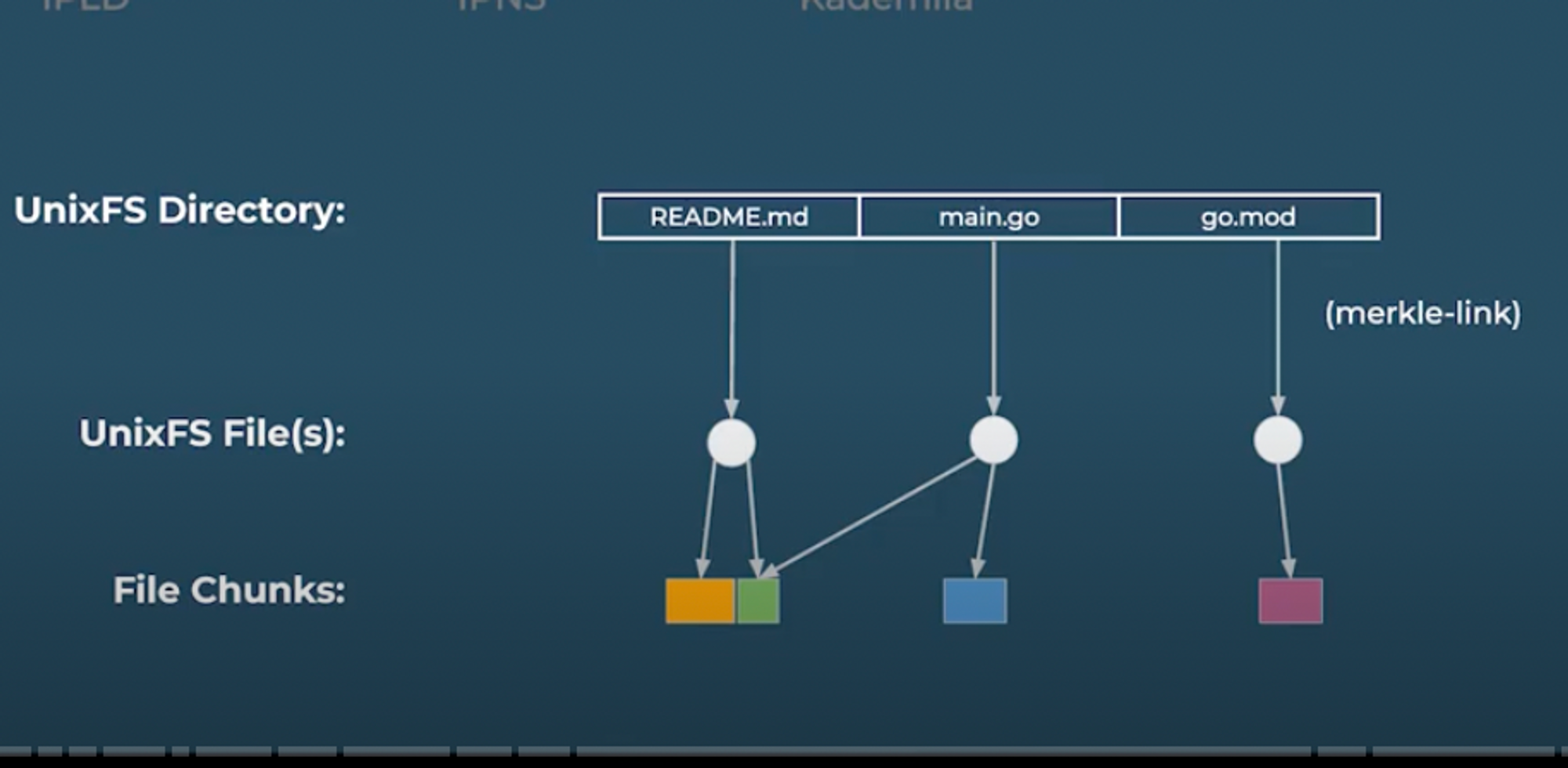
Finally, after creating these logical structures using hashes, files, data, and data structures, we need to encode them so we can transfer them on the network or save it to disk. For that, we will use IPLD.
1.3 IPLD
IPLD is an acronym for Interplanetary Linked Data. It is a meta-format for understanding, encoding, and decoding Merkle-linked data. We use IPLD on IPFS, we can also use it to understand data in Git and Ethereum because they also use linked data structures. It can be thought of as a re-usable data layer that was extracted from IPFS and can be used to build other types of content-addressed data systems. IPLD aims to be an off-the-shelf content-addressed data layer, with associated libraries, documentation, and tooling.
The original concept of IPLD was to use URLs, for example, in Linked Data Structure, you have a JSON Object, and you can use a URL to point to another JSON object, and that object can also point to another object using a URL. There is a problem with this concept as URLs have authority like a .com, and this can change when it wants to, which is something that we do not want. So IPLD uses hashes (Merkel-linked Data), instead of having URLs point to objects as it is in the Linked Data structure, we use hashes to point to other objects. Since it is using hashes, it provides immutability because hashes are immutable and also it uses less authority. Verifiability is one reason for using immutable data.
- How to name files on IPFS
After gaining some insights into the internal data structure, let’s learn about how we name things in the system. We now have objects that are stored using IPLD concepts, we need to be able to pass them around in the network, for this, we use CID or content identifiers.
When naming files, we use concepts like CIDs to actually refer to these pieces of data, we then use Paths to describe extra metadata about CIDs or the data that we are addressing. After that, we use IPNS for renewable names. So let us dive in and try to gain basic knowledge about each of the concepts just mentioned.
2.1 Content Identifier (CID)
CIDs are the most fundamental concept of the IPFS architect and are used for content addressing. You can define CID as a label used to point to material in IPFS. It does not indicate where the content is stored, but it forms a kind of address based on the content itself. CIDs are short, regardless of the size of their underlying content. It is used to name every piece of data in IPFS.
It all starts with a cryptographic hash function that matches the input of an arbitrary size to the output of a fixed size. The same data should always produce the same hash, which means it is deterministic. The cryptographic hash function is a one-way function, which means you cannot compute data from a hash, you can only compute a fixed-sized hash from arbitrary data. It also ensures uniqueness to make sure no two data can produce the same hash.
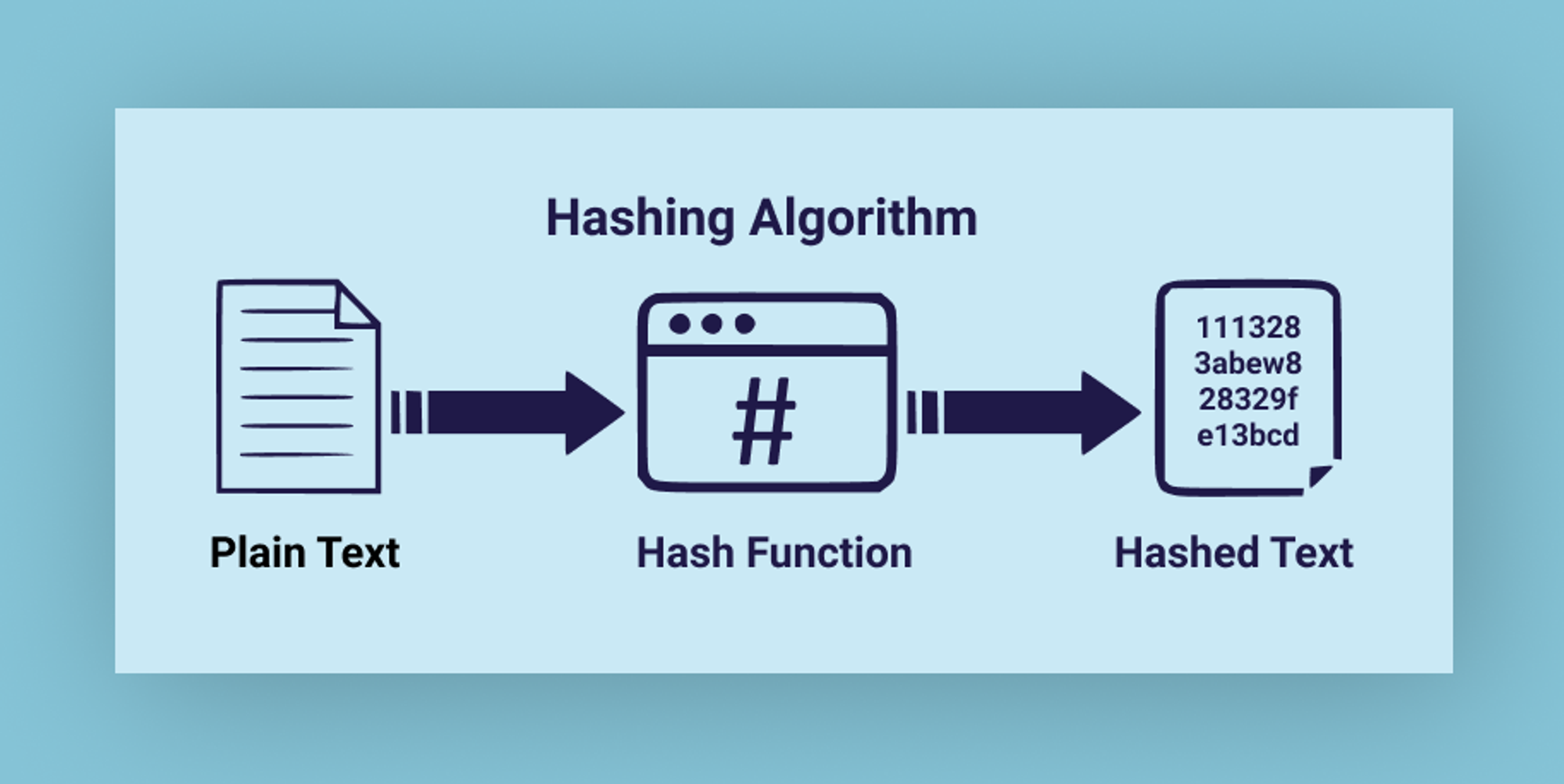
CIDs are based on the content’s cryptographic hash which means:
Any difference in the content will produce a different CID (Immutability), thereby providing integrity checking;
The same content added to two different IPFS nodes using the same settings will produce the same **CID (Deduplication).
CIDs are of two versions, CIDv0 and CIDv1. See examples below:
The above CIDs point to the same content but use two different versions of CID specification. CIDs are self-describing content addresses, they tell you the hash function used as well as the codec that can be used to interpret the binary data being linked.
CIDs give us a complete self-describing package such as
what hash function was used;
how many bytes of output we have;
what kind of data is being addressed and how we might interpret it when we find it.

CIDs build on some basic technologies for self-describing data. These include:
Multihash: A self-describing hash digest, using a pre-set number to identify the hash function used, comprising the main content of a CID.
Multicodec: A pre-set number to uniquely identify a format or protocol. Used in CIDs for the IPLD format that tells you how to decode the data when you locate it and load its bytes.
Multibase: A self-describing base-encoded string, used for the string form of a CID.
Multihash, Multicodec, Multibase, and CIDs are part of the “Multiformats” system for self-describing values.
CID can be said to be built as a concatenation of these technologies: <multibase>(<cid-version><multicodec><multihash>)
Why do we use hashes in place of URLs to link data in IPFS?
We use hashes because they are verifiable, immutable, trustless, and permanent. So if we have a CID pointing to something, it will always point to that thing, and the data it is pointing to cannot change. Any time you query data using its CID, it will always give back that data, this means, nobody can go back and change the data for a particular CID, and if they do, a new CID will be generated
Content addressing versus location-based addressing
Content addressing is where we use a hash to access content, and it allows us to verify that what we received is what we ask for by computing the hash or CID from the content itself.
CID contains a hash and metadata
Content Identifiers (content addressing) address content by content and not by where the content is located. This is equivalent to like “what is it, and not where is it”
In location Address, you can say a particular content is located on a server somewhere, so you can use the location to find and fetch the content. For example, you can say that your dog is located in a street in San Francisco, so using a map, you can trace the location and then use that location to go find your dog.
Location addressing is what we have in Web 2.0, it tells us where the content is stored.
Contents addressing describe the data you are looking for while location addressing tells you where to find the data.
Problems with location addressing
For example using the cat analogy, we can say go find my cat, and you trace the location and when you get there, you see a cat. You will not know if that is the actual cat, or if someone has come to swap the cat before you got there, so in location addressing, the content in that location can change, and the URL will still point to the new content. This way, you can end up not getting the actual content that you want. But with content addressing since CID is generated from hashing the file, changing the file changes its hash, and consequently its CID which is used as an address. You can verify that the file received is the same as what you requested by comparing the CID generated from the content and checking to see that it matches the CID with which you requested the file.
2.2 PATH

IPFS uses paths, and not URIs/URLs. It does not use URLs because Like URLs, paths are namespaced, and unlike URLs, paths are recursive.
Example - /ipfs/Qmfoo/welcome.txt
/ipns/QmBar/index.html
Unlike URLs, paths are recursive.
This example is a way to describe a Git URL for a piece of content - /dns/github.com/tcp/22/ssh/git
You cannot compose multiple protocols on URLs, but with Path, you can compose multiple protocols, and this is why IPFS uses Path.
versus git+ssh:/github.com:22 (not composable)
2.3 IPNS
IPNS is an acronym for InterPlanetary Name System. Content addressing in IPFS is by nature immutable. When you add a file to IPFS, it creates a hash from the data with which the CID is constructed. Changing a file changes its hash, and consequently its CID which is used as an address.
There are many situations where content-addressed data needs to be regularly updated. For example, when publishing a website that frequently changes, it would be impractical to share a new CID every time you update the website with mutable pointers, you can share the address of the pointer once, and update the pointer – to the new CID – every time you publish a change.
The InterPlanetary Name System (IPNS) is a system for creating such mutable pointers to CIDs known as names or IPNS names. IPNS names can be thought of as links that can be updated over time while retaining the verifiability of content addressing.
Example: /ipns/QmMyKey -> /ipfs/QmSomething New
IPNS allows you to map public keys to paths.
Example: /ipns/QmMyKey -> /ipfs/QmFoo (signed)
3.0 Finding files on IPFS
Now that we have covered how to import and name files on IPFS, it is time to talk about finding files on IPFS, which includes the following concepts:
ROUTING
DHT
KADEMLIA
ROUTING - We use routing or content routing to find content on IPFS. We start by taking the CID of the content, and then use the routing system to do the work that is needed to find out the set of people on the P2P network that currently have the content we are looking for. So we find a set of people that have the file, and request for them to send the file to us, and we can then verify if the sent file is what we actually requested.
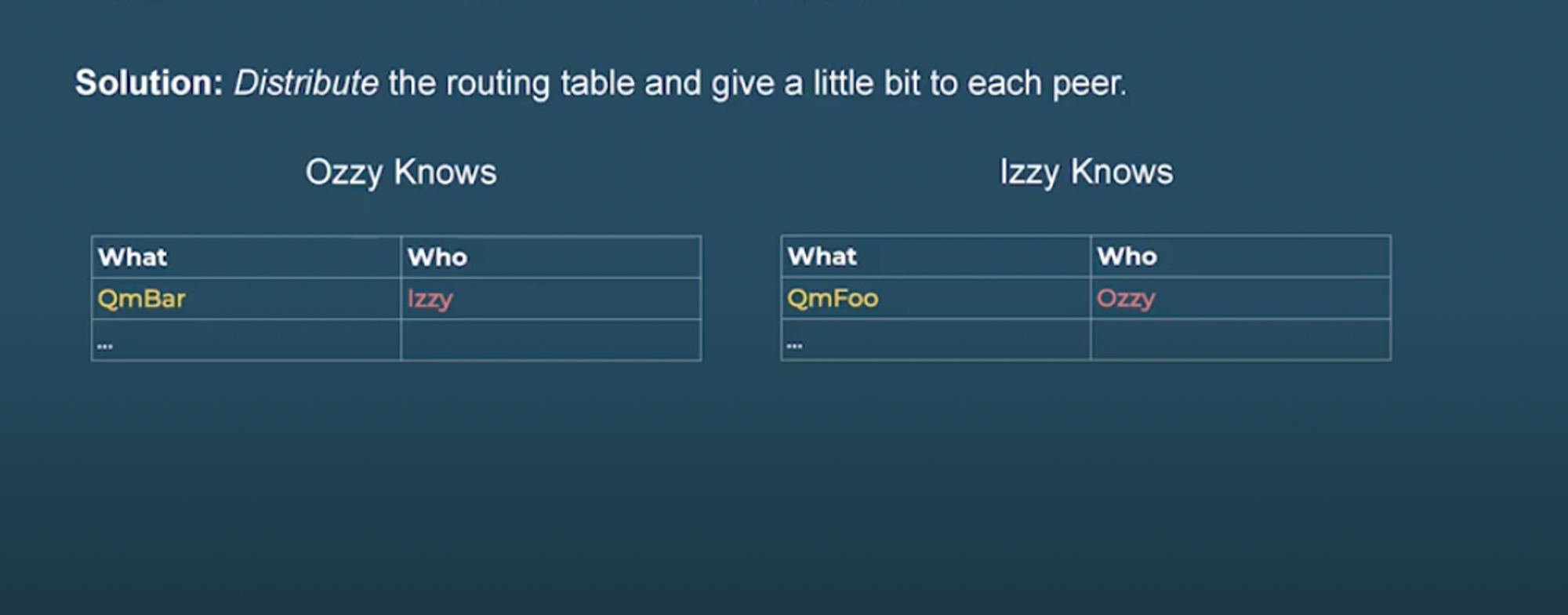
We can implement this concept by keeping a routing table.
WHAT WHO
QmFoo Qzzy
QmBar Izzy
A routing table is a set of rules used to decide where data traveling over a network should go. All IP-enabled devices, including routers and switches, use routing tables. Every IPFS peer maintains a routing table with links to other peers in the network and the content that they have. IPFS relies on Kademlia to define what should and should not go into the routing table:
When we connect to a peer, check if it qualifies to be added to our routing table;
If it qualifies, determine how close the new peer is to us to figure out which bucket it should go into;
Attempt to put the peer in the bucket;
If we ever fail to connect to a peer in our routing table, drop them from the routing table.
We have a massive table that keeps track of which peer has this thing or these things are held by this set of peers. There is a problem though because a single peer cannot hold this routing table, maybe at the moment they could, but when the data gets really big and runs into millions and millions of data on the routing table, no one peer will be able to hold the table. To solve this problem, we use a distributed routing/hashing table, which is about taking the routing table, and then distributing it to all peers in the network in such a way that each peer can store some bit of the routing table.
Distributed Hash Table (DHT)
A distributed hash table (DHT) is a distributed system for mapping keys to values. In IPFS, the DHT is used as the fundamental component of the content routing system and acts like a cross between a catalog and a navigation system. It maps what the user is looking for to the peer that is storing the matching content. Think of it as a huge table that stores who has what data.
How to know who has what piece of the routing table
Before you need to find who has a piece of content, you first need to find the set of peers that has the routing table. This problem can be solved by using Kademlia (deterministically distributing the routing table).
KADEMLIA is based on two key features:
The distance Metric - is peer X closer to content C than peer Y?
The Query Algorithm - Given the distance metric, how do we get to find the peers closest to C. The query algorithm uses the distance metric to find peers that are close to a particular content.
Ask the closest peers you know for closer peers to the content, and remember the closest peers. Every time you reach out to a peer that knows peers who are closer to content, you are always halfway from the content. So the first you reach out, you are halfway to the content, and those peers you reach out to will locate other peers that are halfway closer to the content, this happens until you get to the content.
4.0 - FETCHING FILES ON IPFS
BITSWAP - This is how we actually fetch data on IPFS.
The way this works is by keeping a WANT LIST. A want list is literally just a list of things that you want. You then tell everyone on the network about the list of things that you want. After that, they then swap their want list with you. After receiving what the other peer wants, you check and see which item on the list you have, and the other peer also check to see which of the received items on the list he has, and they both exchange/swap, or send items to the other peer. Once you receive your content, you do resource checking to verify the authenticity of the content received. Resource integrity checking is one way to verify/ensure that the data you received is what you actually requested.
The idea is to calculate an identifier for the data, from the data itself. The identifier is called the hash, and you use cryptography when calculating the hash to ensure that it has some properties like uniqueness and determinism. Once you get the hash, you can share it with the rest of the world, and when someone gets a hold of the data, they also calculate the hash, and they check that it matches. If the hash matches correctly, they know that the data is accurate or is what they requested. If the hashes do not match,
it means someone has tampered with the data.
Bitswap is all about the fact that I send you a list of things that I want, and you send me a list of things that you want.
So far, we have been able to cover the following steps on how IPFS works:
Importing files
Naming files
Finding files
Fetching files
Resources
Subscribe to my newsletter
Read articles from Gino Osahon directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by