Chapter #3: Streamlining AniBrain's Data Pipeline - Enhancing Reliability and Efficiency
 AniBrain Dev
AniBrain DevTable of contents

TL;DR: As part of the broader initiative to transition AniBrain's data pipeline to the cloud, a new database relationship model has been created to pave the way for improved performance and reliability.
Background
Maintaining AniBrain's database has always been a challenging task. Currently, I use pipelines to extract and transform anime/manga data from AniList, Kitsu, and MyAnimeList (MAL). These sources provide metadata and necessary properties for the recommendation engine. Initially, I had set up an automated process, but changes in the MAL API caused the pipeline to break, resulting in the inclusion of incorrect data in the database. To address this, I switched to manually running the pipeline on a local dev database and thoroughly testing the data before importing it to the production environment. This approach ensures that everything functions as intended, and aside from the extra time requirements, has been a success. I am currently focused on reclaiming my time and maintaining confidence in the pipeline. This will enable me to dedicate more effort to building new features and ensuring consistent updates to the database.
Problem
AniBrain's current data pipeline consists of fetching data from three sources, transforming that data, and using it in production. At a high level, it looks like this:

The current data pipeline encounters several issues that hinder its efficiency:
Unreliable MyAnimeList API: The API frequently encounters errors during data fetching (in my experience), despite employing caution with request limits. This inconsistency leads to frequent failures.
Reliability concerns with Kitsu API: While Kitsu's API is relatively reliable, transient errors occasionally disrupt data fetching for newly released seasons. Consequently, the pipeline needs to be rerun to ensure data accuracy.
Lack of storage for raw results: Currently, there is no storage mechanism for raw results. As a result, mistakes made during data pre-processing, ML modeling, or data post-processing necessitate re-querying each data source and restarting the process. Additionally, relevant data that may not be immediately applicable to the AniBrain site is dropped to optimize storage.
Solution
To address these challenges and improve the data pipeline, I've decided on the following solutions:
Consolidating data sources: AniList has been chosen as the sole data source, enhancing API reliability. While this decision results in the loss of synopsis data from MyAnimeList and Kitsu, the impact on the current recommendation engine is negligible.
Introducing three databases: To capture snapshots of anime/manga information at different pipeline stages, AniBrain will employ three databases: "raw," "staging," and "prod." The raw database stores AniList's raw responses, the staging database houses data that has undergone pre-processing, ML model inference, and post-processing, while the prod database stores data exclusively required for the AniBrain site. The new pipeline will look like this:
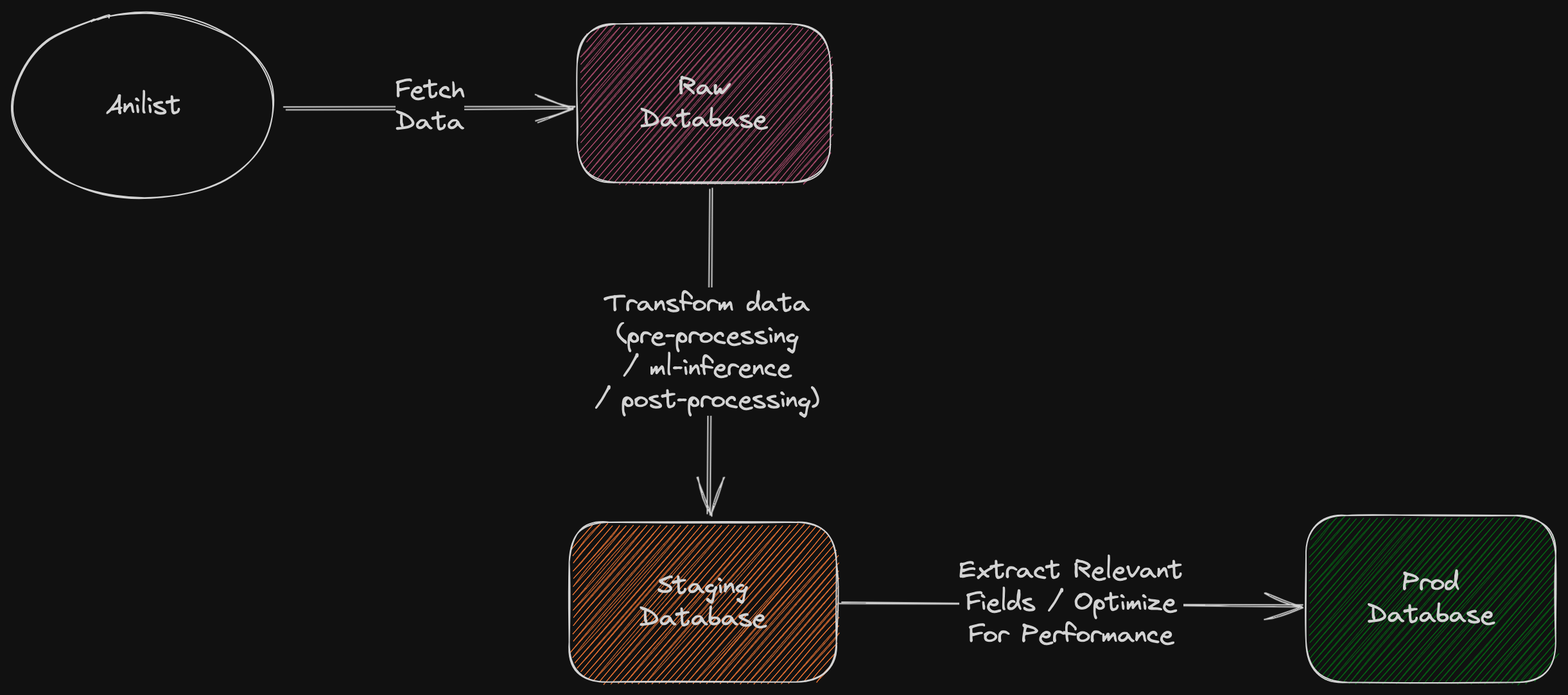
Actions Taken
To work towards these changes, the following actions have been taken:
Creation of an extraction-transform-load (ETL) pipeline for the raw database.
Implementation of error monitoring via Sentry and pipeline monitoring via Cronitor for the raw database pipeline.
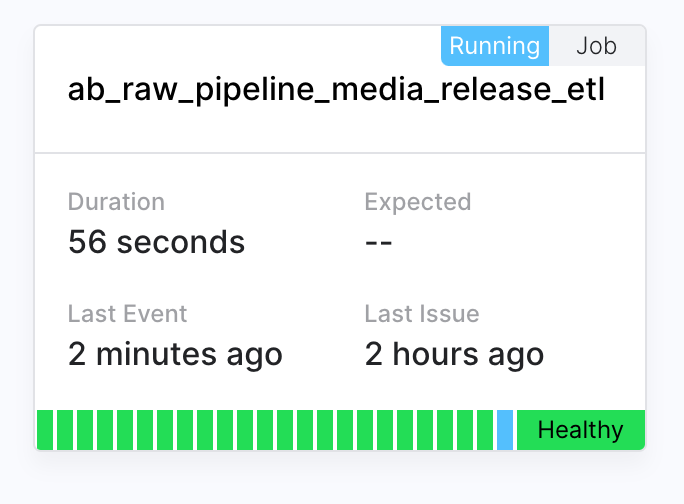
Initiation of a one-off cloud job to populate the raw database with anime and manga data released between 1910 and 2023.
Documentation of the raw database pipeline.
Next Steps
To work towards the solution described above, I've outlined the following next steps:
Establish a cron job for the raw database pipeline.
Development of a staging database pipeline.
Conclusion
By refining the data pipeline and enhancing reliability, AniBrain aims to streamline its operations, reduce errors, and improve efficiency. The consolidation of data sources and the introduction of dedicated databases at different pipeline stages will enable AniBrain to maintain an accurate and up-to-date database, empowering me to focus on building new features.
Subscribe to my newsletter
Read articles from AniBrain Dev directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
AniBrain Dev
AniBrain Dev
Creator of www.anibrain.ai