Postgres Just in time compilation and worker processes
 Nirjal Paudel
Nirjal PaudelBoth Just In Time compiler or JIT and worker processes could be news to you. By the end of this article, you would be able to understand the picture I have provided.
For this article, I have created a couple of Postgres tables with huge rows, each of the rows has a relationship with another table. The relationship between them is many-to-one. One of the tables is a product and the other table is a store. Many products have one store referenced by the store_id column. Here is a rough command for SQL `CREATE TABLE` statement
CREATE TABLE store (
id SERIAL PRIMARY KEY,
name VARCHAR(255),
address VARCHAR(255),
phone_number VARCHAR(15)
);
CREATE TABLE product (
id SERIAL PRIMARY KEY,
name VARCHAR(255),
price DECIMAL(10,2),
description TEXT,
store_id INT,
FOREIGN KEY (store_id) REFERENCES store (id)
);
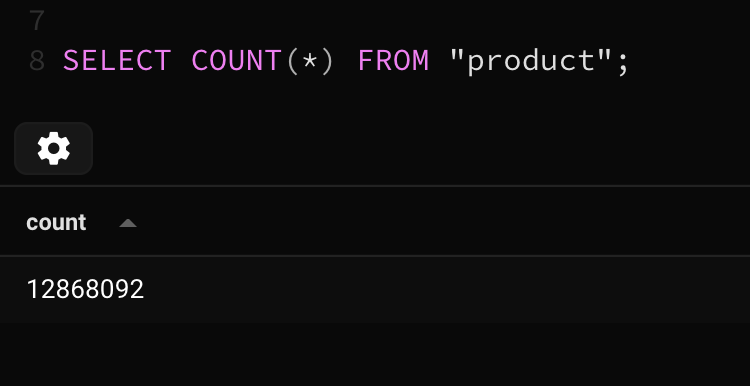
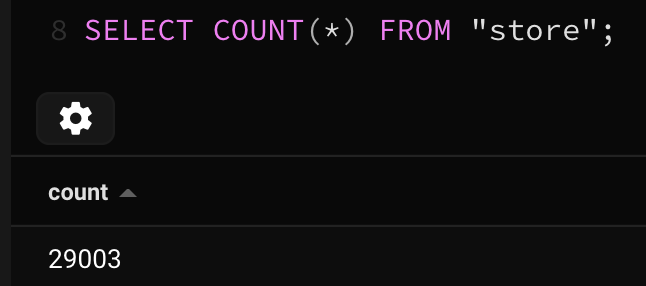
I have around 29k stores and around 12 million products. Here is the count of the both
I haven't placed any indexing structure for the product table. Now let's interact with the product table.
WHERE clause and Count:
EXPLAIN ANALYSE SELECT COUNT(*) FROM "product"
WHERE "price" < 10;
The result of EXPLAIN ANALYZE shows the following info
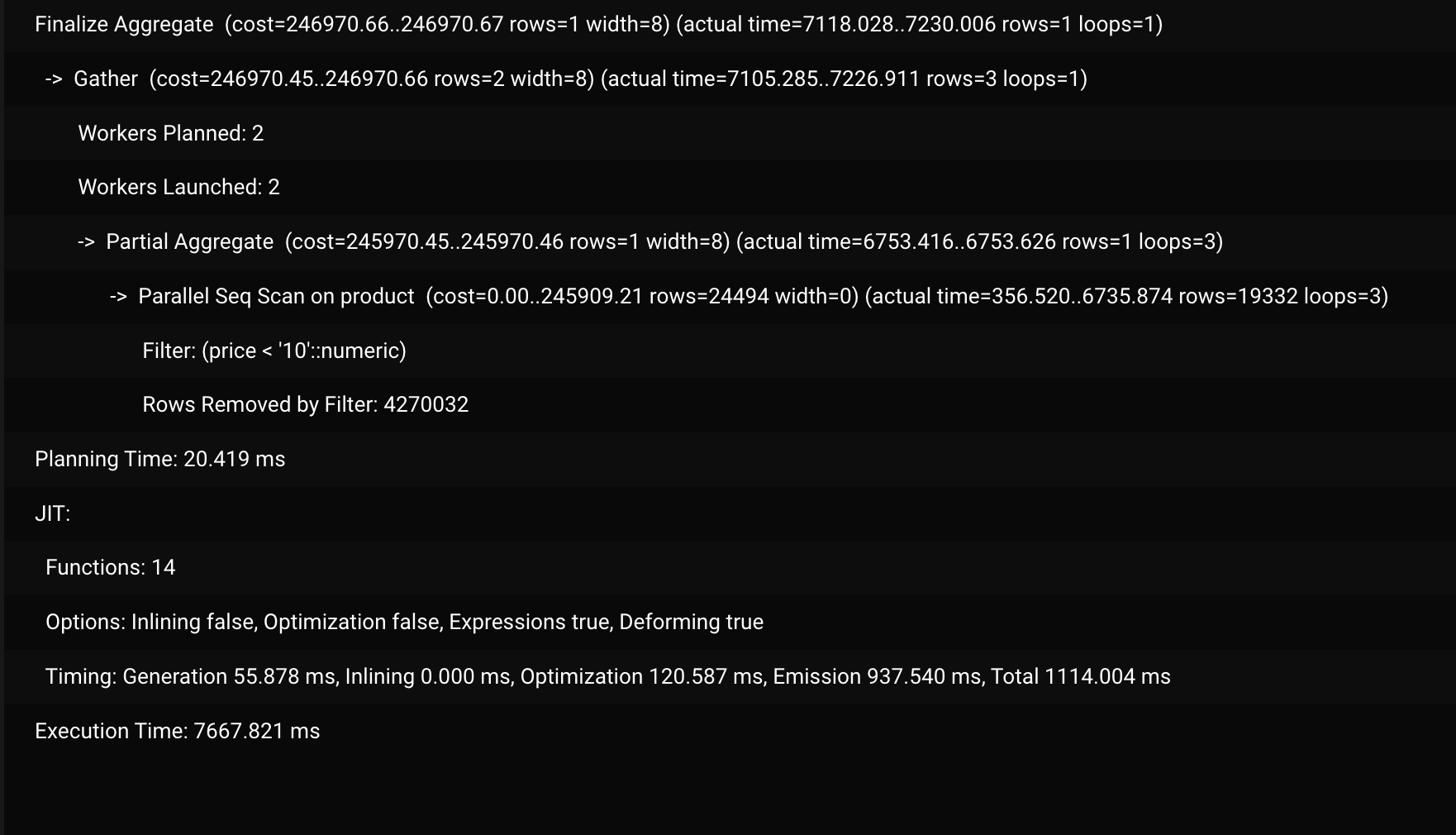
Planning stage/JIT:
The planning stage for the command used the Just In Time compilation. I think every analytical serverless function should use this. Due to JIT compilation, the planning phase time is almost doubled.
Just In Time Compilation (JIT)
Suggestions:
Use JIT for analytical queries.
Use JIT for complex sorting queries.
Execution stage/Worker process:
The execution stage of the query is executed using 2 workers, each of the worker processes scans the table from opposite ends. Each worker is filtering the rows and count results were gathered and a final aggregation was done to get the final count.
On worker process:
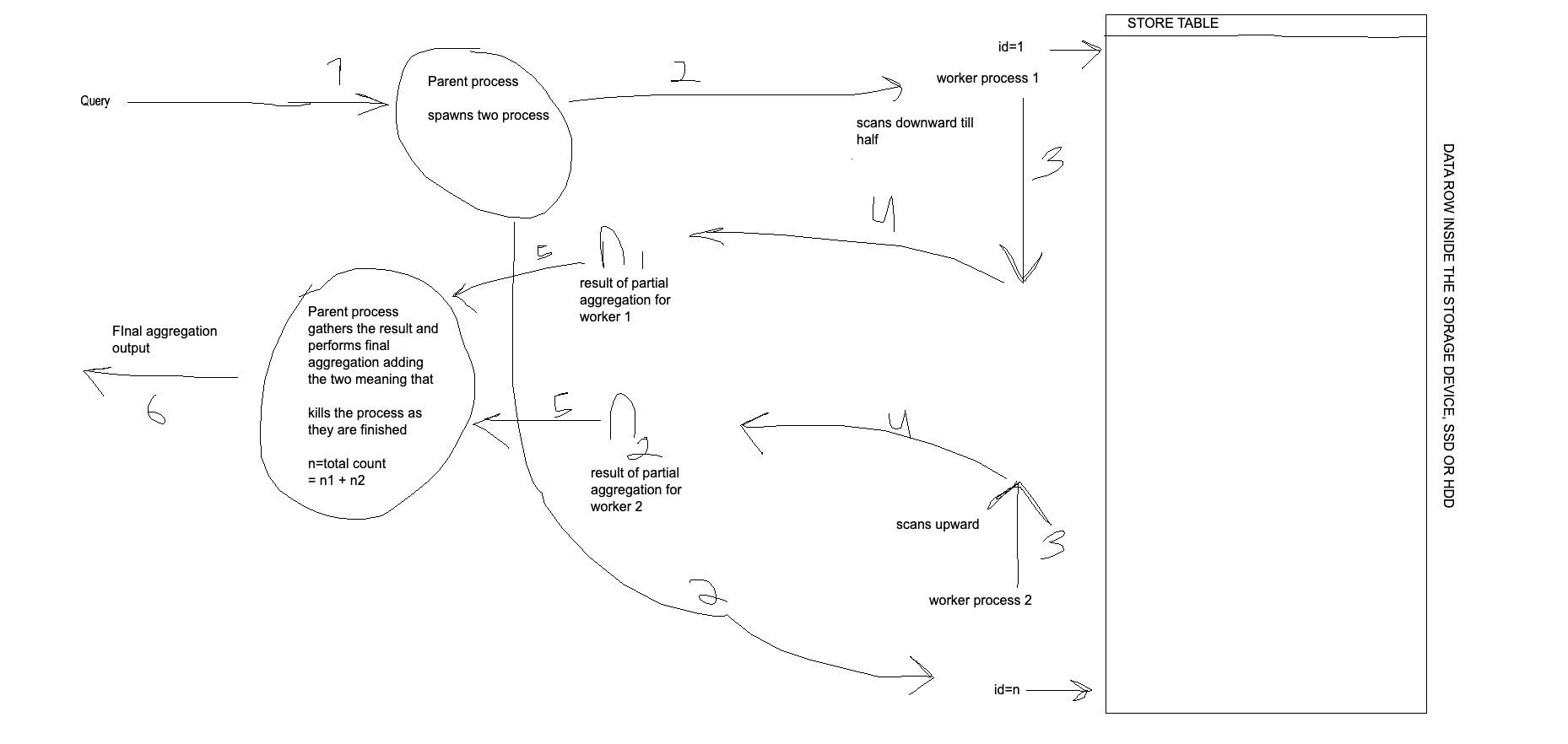
The worker process strategy used spawns 2 process that parallel scans the product and returns the matching rows, here the worker uses the gather node and has done the here partial and the final aggregation used is the COUNT aggregation. Here is a graphic that can help you understand the working principle.
Whats in the picture
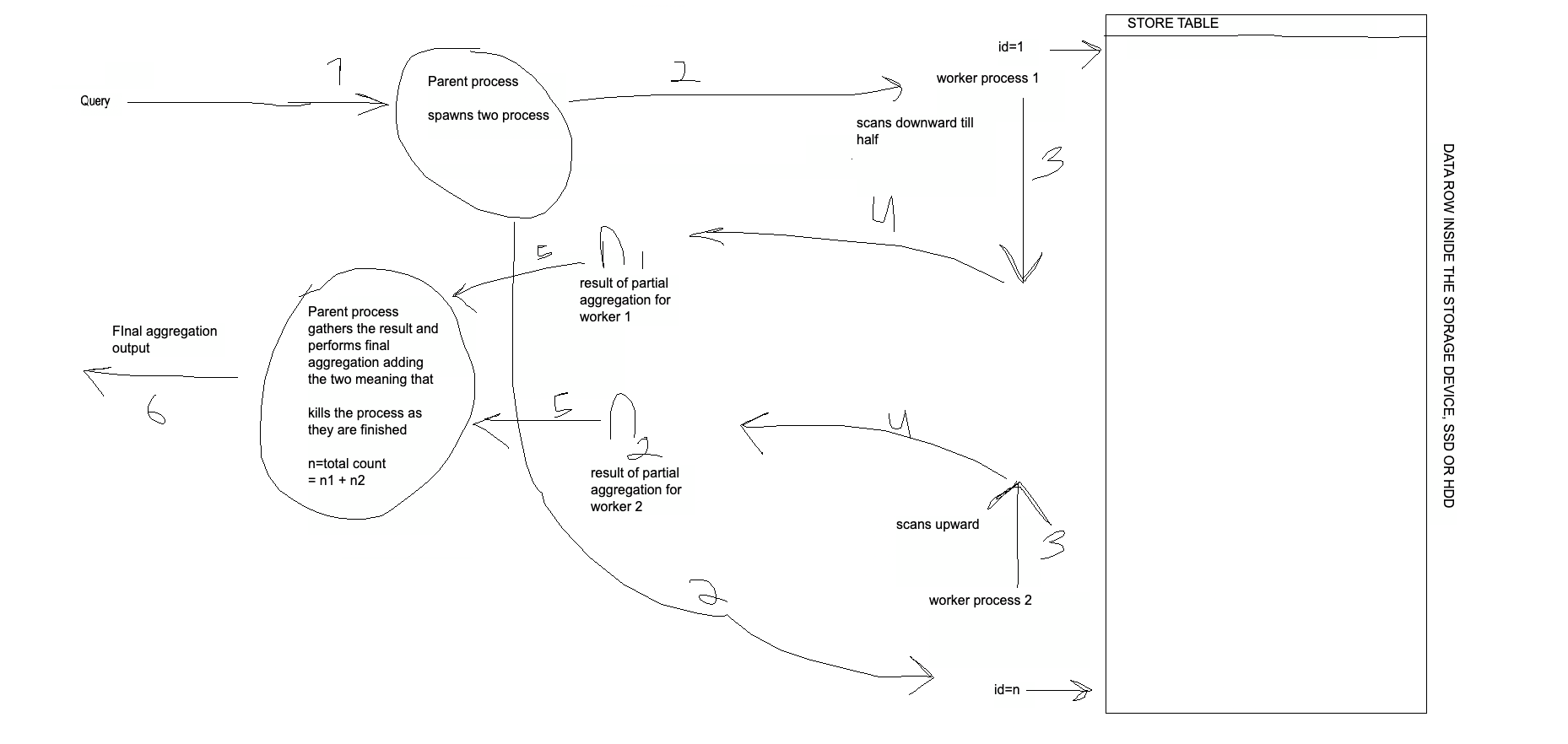
I hope you can clearly understand the picture now, but here are the steps involved.
The parent process spawns two processes.
Two processes work from either end of the table
The processing or scanning takes place in our case, it scans via the native CPU code generated due to JIT compilation.
The result is partially aggregated meaning total count is generated.
The count is handed over to the parent process by the worker process.
The 2 worker processes are killed and their result is combined and the output is given to the user.
Now you might be wondering what if we increase the total number of workers in the query, let's do that. Note that this will increase the execution speed of the query but as more processes are used, it will use more memory. Lets me increase the max_parallel_workers and max_parallel_workers_per_gather parameter to and 4 respectively to get more workers to do the task. Learn about them more here.
How does the Postgres parallel worker work
My PC is 8 core CPU PC and my CS knowledge says that my computer shouldn't lag till 8 worker processes. Managing process is also time-consuming as launching and killing a process is a time-consuming and expensive time as well. But hey, I am postgres with docker and other background apps are running simultaneously as well. So leaving the theory aside lets make the hands dirty.
I ran the following query
-- the value x is the total worker allowed
SET max_parallel_workers = x;
SET max_parallel_workers_per_gather = x;
EXPLAIN ANALYSE SELECT COUNT(*) FROM "product" WHERE "price" < 10
Upon running the query I got the following results
| Total Worker allowed | Workers Launched | Planning Time | Execution Time |
| 0 | 0 | 16.883 ms | 19566.353 ms ~ 19s |
| 1 | 1 | 20 ms | 10182.869 ms ~ 10s |
| 2 | 2 | 21.393 ms | 7347.291 ms ~ 7s |
| 3 | 3 | 23.972 ms | 6713.247 ms ~ 6s |
| 4 | 4 | 20.096 ms | 6654.102 ms ~ 6s |
| 5 | 5 | 19.418 ms | 7037.768ms ~ 7s |
| 6 | 5 | 20.402 ms | 6662.773ms ~ 6s |
| 7 | 5 | 19.183ms | 6428.286ms ~ 6s |
| 8 | 5 | 4.169 ms: Plan was cached from the previous execution | 6254.108ms ~ 6s |
Postgres query planner is a clever piece of tool and it detected that the execution time was not going to be much better after 5 worker processes and stopped spawning more worker processes when it reached the value of x greater than 5. Even when I was allowed to go more than 5 workers per execution, I didn't do that and insisted on using 5 worker processes.
BIG BUT
Here's a big but for y'all. The query I used is pretty simple, right? count the total, so let me spice things up a little bit more with the following query.
EXPLAIN ANALYSE
SELECT id FROM "product" WHERE "price" > 10
ORDER BY store_id DESC
LIMIT 1000
The query provided below is more "complex" as it has sorting and limiting in it and the query planner looks like this with no worker. Not only that the querying condition has changed as well resulting in more data to look for.
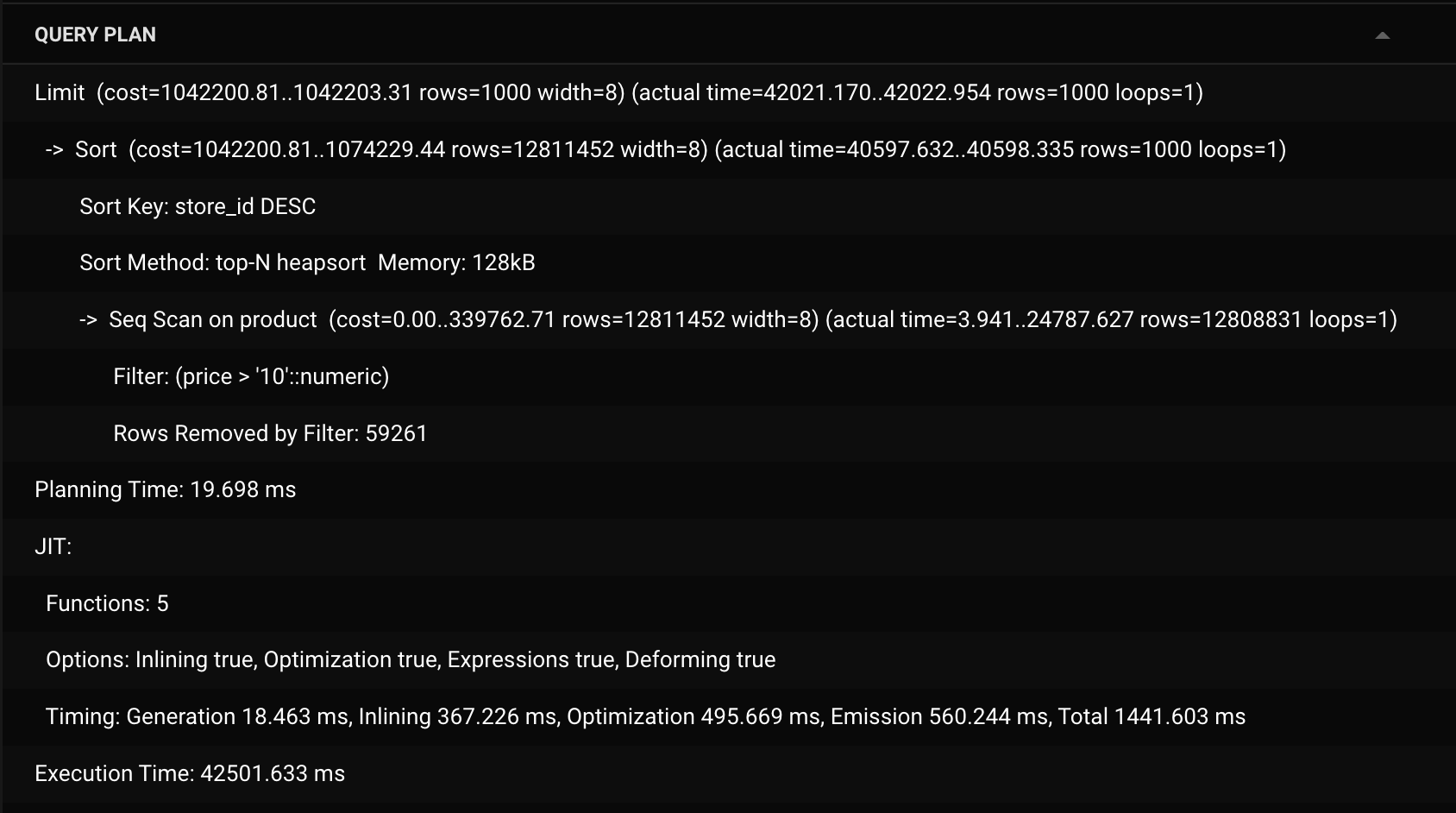
Here I forced the query planner to not use worker processes.
Planning stage:
The planning stage remains almost all the same with JIT enforced but here the parameters of the JIT is changed. Options like optimizations, and expressions are set to true. The overall number of functions is changed as well. Planning time is consistent.
Execution stage:
I forced only one worker to be used at this time. To see all the activities it performs, here parallel seq scan is used. Top-N heapsort is used, it shares the time complexity of heapsort but only sorts the top N members( for our case it's 1000 ) and finally limit happens.
Now let's add workers to the picture
Gather Merge node is used as it is expected to be used for queries with sorting enabled.
Here is the result for various query times.
| Total Worker allowed | Worker used | Planning time | Execution Time |
| 0 | 0 | 19.698 ms | 42501.633ms ~ 42s |
| 1 | 1 | 11.999 ms | 22632.546 ~ 22s |
| 2 | 2 | 40.938 ms | 16720.326ms ~ 16s |
| 3 | 3 | 18.647 ms | 14.177.078ms ~ 14s |
| 4 | 4 | 19.740 ms | 14125.600ms ~ 14s |
| 5 | 5 | 21.546 ms | 13756ms ~ 13s |
| 6 | 5 | 18.094 ms | 13838ms ~ 13s |
| 7 | 5 | 17.109ms | 14415ms ~ 14s |
As you can see that using the worker process has significantly decreased the planning time by almost half compared to not being used in both queries. This is a general introduction to worker processes and JIT in Postgresql but do you still with 5 workers used, the query is considered really slow. This is due to the use of seq scan to filter the product table. In the next writing, I would help you on how to improve on that with an introduction to index in Postgres and its type. Until then, you can follow me on my LinkedIn here. My Linkedin Profile.
Subscribe to my newsletter
Read articles from Nirjal Paudel directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Nirjal Paudel
Nirjal Paudel
I am a skilled software developer with experience in both front-end and back-end development. I have a Bachelor's degree in Computer Science and have worked on various projects, ranging from building responsive websites to developing complex web applications. I am proficient in programming languages such as JavaScript, Python, and Java, and have experience with frameworks such as React, Node.js, and Django. Additionally, I am experienced in database design and management using technologies like MySQL and MongoDB. I am passionate about software development and am always eager to learn and implement new technologies.