Unleashing the power of Data: Data Generation
 Warui Wanjiru
Warui Wanjiru
Introduction:
Welcome back to our data engineering journey! In our previous blog post, we explored the fundamentals of the data engineering lifecycle and the importance of viewing data engineering as a holistic practice. Today, we continue our exploration by diving deeper into the data engineering lifecycle, with a specific focus on the crucial stage of data generation. Join me as we unravel the intricacies of data generation source systems and discover the key evaluation questions that drive their selection and design.
Recap: The Data Engineering Lifecycle
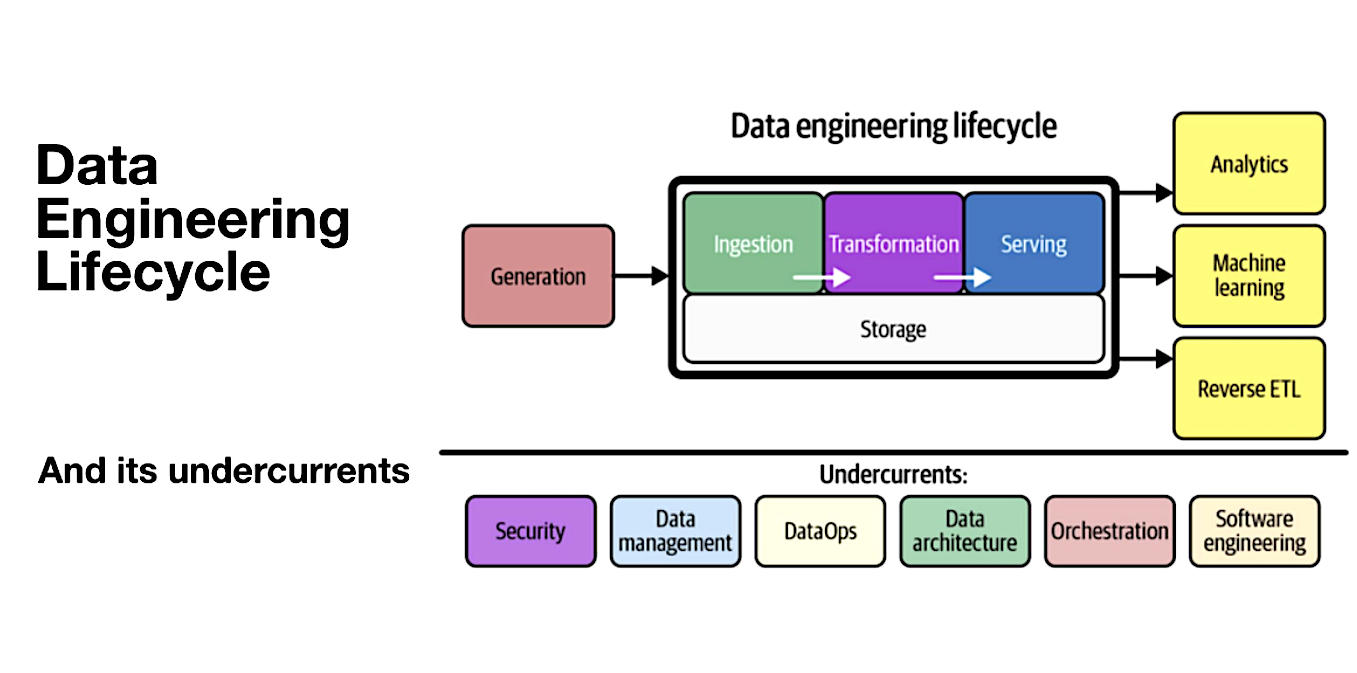
Before we embark on our exploration of data generation, let's briefly recap the overarching concept of the data engineering lifecycle. The data engineering lifecycle represents the complete journey of data, from its inception to its consumption by analysts, data scientists, ML engineers, and others. It encompasses various stages that transform raw data ingredients into valuable insights. This process involves several steps, including data generation, storage, ingestion, transformation, and serving.
(Read the in-depth blog on the Data Engineering lifecycle here.)
Understanding Data Generation Source Systems:
Data generation source systems serve as the starting point for the entire data engineering lifecycle. They are the origins from which valuable data is extracted, setting the foundation for subsequent processing and analysis. As data engineers, understanding the characteristics and nuances of these source systems is crucial for designing effective data pipelines. Let's explore the key evaluation questions that guide the selection and design of data generation source systems:
1. What are the essential characteristics of the data source?
To effectively harness the power of data, data engineers must gain a deep understanding of the source systems. Is the data generated by an application database, an IoT swarm, or another form of data generator? Each type of source system comes with its own unique characteristics and considerations, requiring tailored approaches.
2. How is data persisted in the source system?
Determining the persistence mechanism of the source system is vital. Is the data stored temporarily and quickly deleted, or does it have a long-term retention requirement? This knowledge helps data engineers design appropriate data processing and storage strategies.
- What is the rate of data generation?
The velocity at which data is generated plays a crucial role in data engineering pipelines. Data engineers need to know the rate at which data events occur (e.g., events per second) or the volume of data generated over a specific period. This information guides the optimization of data ingestion, transformation, and storage processes.
4. What level of consistency can be expected from the output data?
Data quality is paramount in any data engineering endeavor. Understanding the consistency of the output data is critical for downstream processes and analysis. Data engineers must evaluate potential data inconsistencies, such as null values or formatting issues, and implement robust data quality checks.
5. How often do errors occur?
Errors are an inevitable part of any data engineering workflow. By understanding the frequency and types of errors encountered in the source system, data engineers can proactively build error-handling mechanisms and ensure the reliability of the data pipelines.
6. Will the data contain duplicates?
Duplicate data can present challenges in data processing and analysis. Data engineers must assess whether duplicates are likely to occur in the source system and determine how to handle them effectively to maintain data integrity and avoid redundant computations.
7. Will some data values arrive late?
In real-time data scenarios, certain data values may arrive late compared to others. Understanding the potential delays and their impact on downstream processes is crucial for maintaining data coherence and accuracy. Data engineers need to design pipelines that can handle delayed data appropriately.
8. What is the schema of the ingested data?
The schema defines the structure and organization of data. Data engineers must assess whether the ingested data adheres to a fixed schema enforced by a relational database or follows a schemaless approach where the schema evolves dynamically. Understanding the schema implications facilitates proper data transformation and integration
9. How does the source system handle schema changes?
Schema evolution is inevitable, particularly in agile software development environments. Data engineers need to determine how the source system handles schema changes and how these changes are communicated to downstream stakeholders. This knowledge enables seamless integration and ensures consistent data processing.
10. How frequently should data be pulled from the source system?
Determining the frequency of data extraction from the source system is essential for maintaining up-to-date data in downstream processes. Data engineers must strike a balance between real-time requirements and the performance impact on the source system.
Discussion: Unraveling the Nuances of Data Generation Source Systems:
As data engineers evaluate and answer these key evaluation questions, they gain valuable insights into the characteristics, limitations, and potential challenges of data generation source systems. This understanding empowers data engineers to design robust data engineering pipelines that align with the specific requirements of each source system.
By acknowledging the diverse nature of source systems and their impact on the data engineering lifecycle, data engineers can proactively address potential bottlenecks and ensure the seamless flow of data from its inception to its consumption.
Conclusion:
In this installment of our data engineering series, we delved into the crucial stage of data generation and explored the key evaluation questions that guide the selection and design of data generation source systems. By thoroughly understanding the essential characteristics, rate of data generation, data consistency, schema implications, and other aspects, data engineers can build resilient and efficient data engineering pipelines.
As we continue our journey through the data engineering lifecycle, stay tuned for our next blog post, where we will continue to explore the storage stage and discuss the considerations and best practices for effectively managing and storing vast amounts of data. Happy data engineering!
Subscribe to my newsletter
Read articles from Warui Wanjiru directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Warui Wanjiru
Warui Wanjiru
I am a passionate and highly motivated Junior Data Engineer, driven by my curiosity and eagerness to explore the vast world of data. With a solid foundation in data analytics, programming, and database management, I thrive on the challenge of extracting, cleaning, transforming, and visualizing data to uncover valuable insights. My journey in the realm of data engineering has exposed me to various programming languages and tools, including Python, SQL, and Tableau. However, I don't stop there—I am constantly seeking new knowledge and skills to stay ahead of the curve. Currently, I am immersing myself in the world of Rust, harnessing its speed and efficiency prowess. Embracing this new language allows me to tackle complex data engineering tasks with even greater efficiency and effectiveness. What truly sets me apart is my genuine enthusiasm for learning and taking on new challenges. I thrive in dynamic environments that push me to think creatively and find innovative solutions. With a solid understanding of data structures and algorithms, I relish the opportunity to dive into complex datasets, unearthing patterns and unlocking actionable insights. Above all, I am dedicated to making a real impact through data engineering. I believe in the power of data to drive transformative change and improve decision-making processes. By harnessing the power of data, I strive to empower organizations to make informed choices and achieve tangible results. Let's embark on this exciting journey together, where I can contribute my authentic enthusiasm, my thirst for knowledge, and my unwavering commitment to delivering exceptional data solutions.