How to use Recall to evaluate your model performance ?
 Yuvraj Singh
Yuvraj Singh
I hope you are doing great, today we will discuss an important topic for model evaluation i.e. "Recall". Before starting out let me tell you that after reading this blog you will be completely aware about what is recall, why we even use it and how to calculate it for binary or multi-class classification. So let's get started.
Why to even consider recall?
In my opinion before focusing on understanding how to calculate the recall for binary or mulit-class classification we must be aware about why do we even use recall at all ?. Why are we not satisfied with the precision ?. To answer these questions we will consider 2 scenarios and in those scenarios you will automatically understand where precision lacks.
Scenario 1 ( Cancer detection ) 🎗
Let us assume that we are building a model that based on some input features will help us to detect that whether a person is having cancer or not. Non in this scenario we need to make sure that the false negatives are as minimum as possible, because false negatives would mean that the person is actually having cancer but our model is saying a person is not having cancer and as you might guess this is not a good thing at all !!.

In other words we can say that we need to make sure that out of all the patients who actually have cancer our model should be able to maximize their cancer prediction and in this scenario precision will not be very much beneficia because by using precision we can only focus on reducing the false positives means person is not having cancer but model is predicting that person is having cancer and this is not as dangerous as false negatives.
Scenario 2 ( Email Spam - ham ) 📧
Now again let us assume that we are building a mode that based on the context written in the mail will help us to detect that whether an email is spam or not. So in such scenario our focus must be on reducing the false positives because false positives would mean that the email is not spam but model is labeling it as spam and this is not good, because there is a possibility that the mail could be important.
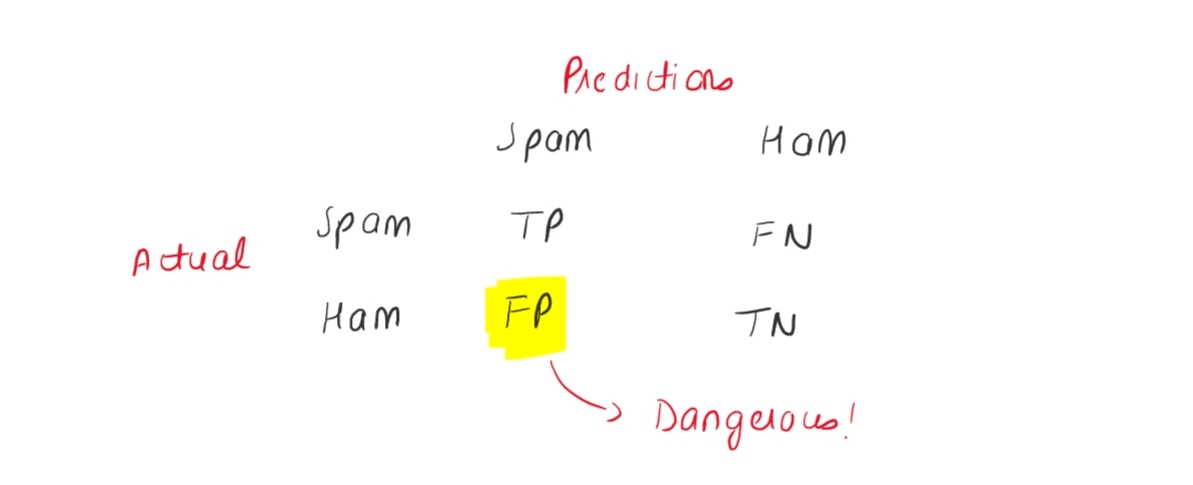
In email spam-ham case the recall will not be benificial to consider because by using recall we can only focus on reducing the false negatives that would mean that the email is actually spam but our model is saying it is not spam and as you might guess this is not a very dangerous.
Recall for binary class classification
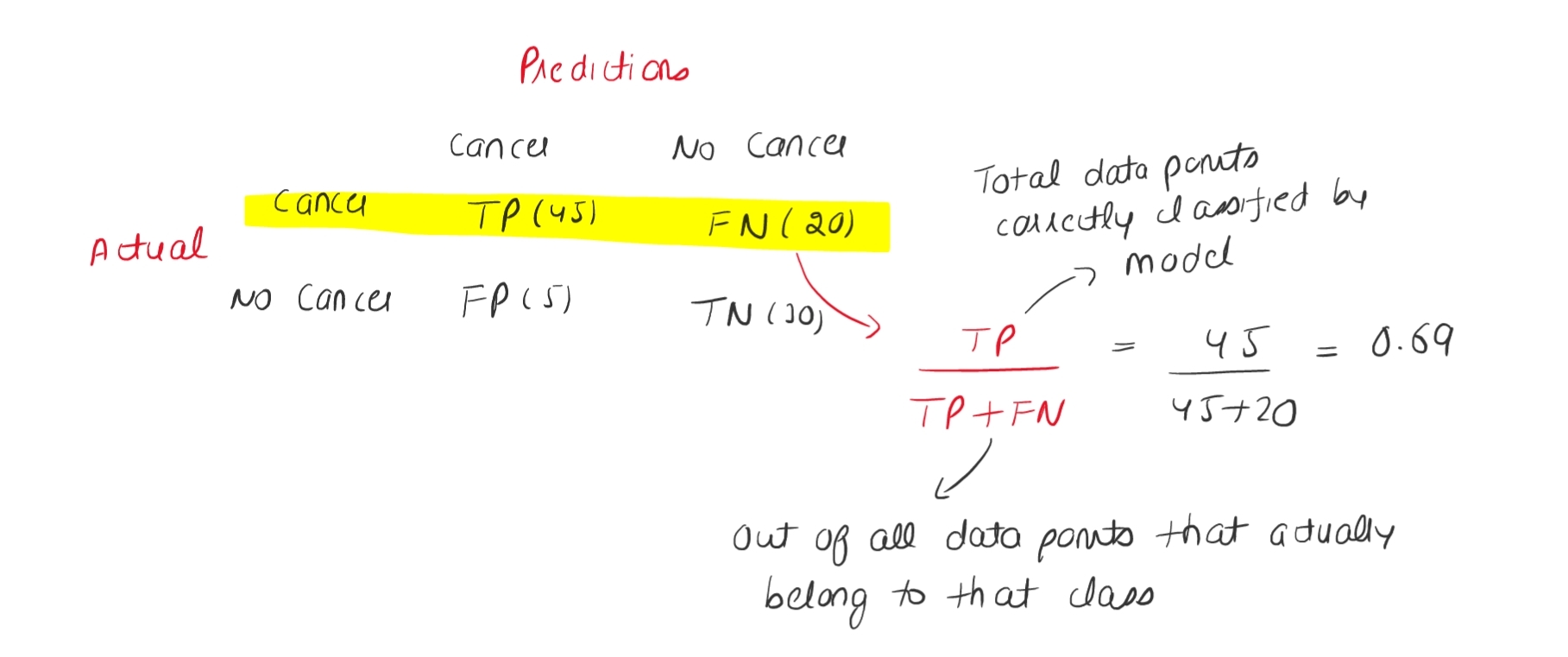
The formal definition of recall is total number of data points which are correctly classified by the model out of all the data points actually belonging to that class.
Now to actually understand the formula to calculate the recall instead of memorizing teh formula let us assume that we are building a model that based on some input features model will detect that wheter a person is having cancer or not. The confusion matrix is given below
Recall for multi-class classification
In case of binary class classification our focus in mostly on the positive class like has cancer, fraud etc but not on the negative class such as no cancer or not fraud.But in cae of multi-class classification where we have multiple classes we will not be able to use this cocept of ony choosing the positive class, because there would be no notion of positive or negative class.
To better undertand this let us assume that we are building a classification model where based on certain data input our model will assign a class to that query point (Input data). The classes are ( Apple, orange and mango ). So in such kind of scenarios we will not be having any notion of positive or negative labels.

For multi-class classification problem we will be calculating the recall for every class and wil chose the maximum recall.
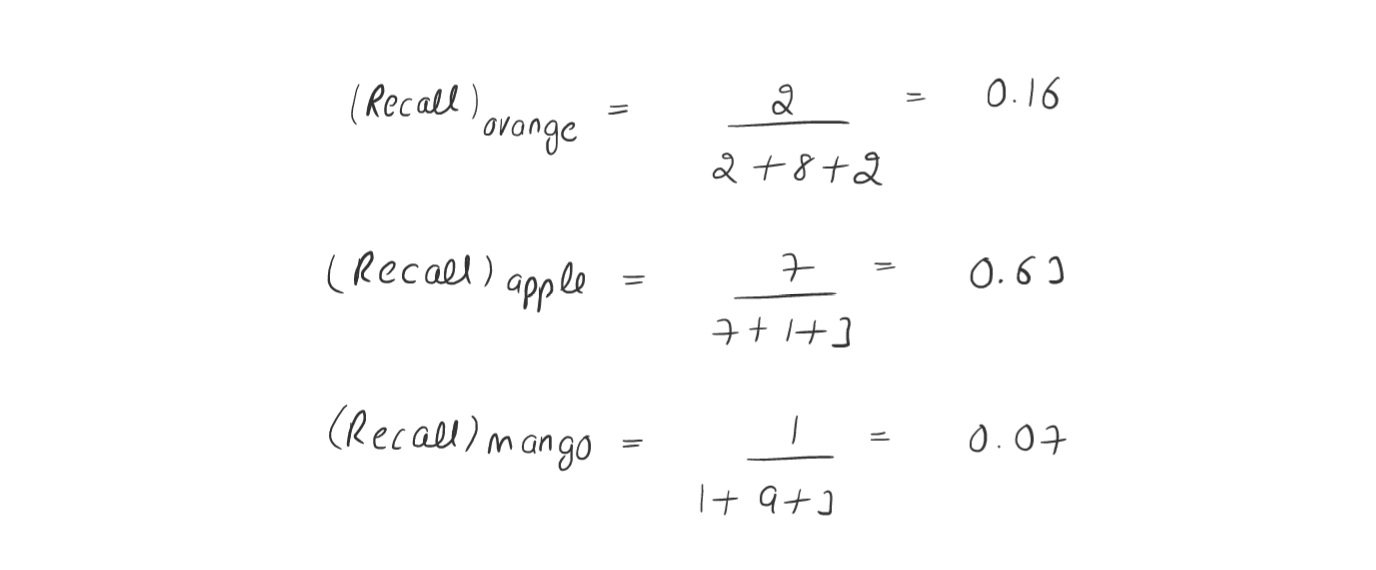
Short note
I hope you good understanding of what is recall, how to calculate it for binary or multi-class classification problems and if you liked this blog or have any suggestion kindly leave a comment below it would mean a to me.
Subscribe to my newsletter
Read articles from Yuvraj Singh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Yuvraj Singh
Yuvraj Singh
With hands-on experience from my internships at Samsung R&D and Wictronix, where I worked on innovative algorithms and AI solutions, as well as my role as a Microsoft Learn Student Ambassador teaching over 250 students globally, I bring a wealth of practical knowledge to my Hashnode blog. As a three-time award-winning blogger with over 2400 unique readers, my content spans data science, machine learning, and AI, offering detailed tutorials, practical insights, and the latest research. My goal is to share valuable knowledge, drive innovation, and enhance the understanding of complex technical concepts within the data science community.