How to Handle Missing Values in Your AI Project (When Less Than 5% of Data is Missing)
 Yuvraj Singh
Yuvraj Singh
I hope you are doing great, so today we will discuss an important topic in machine learning handling missing values. After going through this blog you will be completely aware about which technique to use and when to use. So without any further dealy let's get started.
Why even handle missing values ?
Today, we will examine how to deal with less than 5% missing values in some feature in our dataset, but before doing so, it is important to understand why we are even attempting to deal with the missing values. For example, would it be harmful to leave them in place, and if so, what kind of harm might they cause?.
The answer to above questions is that not removing missing values from a dataset can have several consequences, some of which are:
- Our dataset's missing values have a substantial impact on the statistical analysis of the data, which can result in wrong conclusions.
- Many machine learning algorithms cannot handle the missing data, because of which if we will try to train them on missing data then in return we will get error.
Techniques to handle missing values
The overall selection of which technique to use to handle missing values totally depends upon the percentage missing values in some feature or dataset. For example: by doing df.isnull().mean()*100 we will get percentage of missing values in all the features and in all the features which will be having 5% or less than 5% missing values in all such features we can either use CCA or Basic imputation techniques ( reccomended ).
Technique 1 : Complete case analysis
Complete Case Analysis commonly known as (CCA), is a method which is used to handle the missing values and in this method we simply remove all those rows from our dataset for which any column value is missing. There are additional prerequisites that must be met before using this approach, including the following 👇
The data must be missing at random (MCAR), and if the data is not missing at random in some cases, we won't apply the CCA technique. For example : if part of the initial or last n rows' column values are missing in such scenario we will not use CCA technique. Additionally, we must plot the histogram (density function) to determine whether or not the data in our dataset are missing at random. If the distributions are similar to one other, then the data is MCRA.
We can utilise CCA if there are fewer than 5% of missing values in a column, but we won't use it if there are more than 5% of missing data.
Code implementation
Let's now understand how to deal with missing values by simply removing them from our dataset.
import pandas as pd
# Create a sample dataset with missing values
data = {'A': [1, 2, None, 4, 5],
'B': [6, None, 8, 9, 10],
'C': [11, 12, 13, None, 15]}
df = pd.DataFrame(data)
# Print the original dataset
print("Original Dataset:")
print(df)
# Remove rows with missing values
df_removed = df.dropna()
# Print the dataset after removing missing values
print("\nDataset after removing missing values:")
print(df_removed)
Drawbacks of CCA
CCA has a few downsides that make it less popular than other approaches. Two of these drawbacks are as follows:
Our dataset might lose a significant amount of data if CCA is used.
There must not be any missing values when we deploy our model to the server because during the training pipeline the way we are dealing with missing values is by removing them but during the prediction stage if some missing values would be there then our model will simply drop that input query point and in response we will get nothing or an error.
Technique 2 : Imputing missing values
As we previously stated, there are two ways to deal with the missing values in our dataset. Now, we'll look at imputation approaches, which simply means that rather than eliminating the missing values from our dataset, we'll fill them with some value.
But before getting too far into the imputation procedures, we must first determine whether the missing data are categorical or numerical, and then we must decide whether to use univariate or multivariate imputation.
| Univariate imputation | Multivariate imputation |
| It means for imputing a missing value in some featurew we will be using the values of that feature only. | It means for imputing a missing value in some feature we will be utilizing the values of other features |
| Example of univariate imputation techniques : Mean imputation, mode imputation, median imputation or arbitrary value imputation | Example of multivariate imputation techniques : MICE algorithm, KNN imputer |
Univariate imputation techniques
Now we will discuss each and every univariate imputation techniques along with python code. Univariate techniques include : Mean, median, mode and arbitrary value imputation. First let's understand what does mean, median and mode actually means in case you don't know about it.
| Mean | Median | Mode |
| It is one of the central tendency measures that is used to determine the average value of data distribution. | One of the central tendency measures is used to determine a number that, divides the distribution of data into two equal portions when ordered in either ascending or descending order | One of the central tendency measures is used to determine the most frequently occurring value |
Now let's talk about how to put this into practice. When filling in missing numbers with the mean, median, and mode, there are 2 things which we must keep in mind
We must first divide the dataset into train, test and validation set.
We must only use the training data to find the mean, median or mode value.
Code implementation
import pandas as pd
import numpy as np
# Create a sample dataset with missing values
data = {'A': [1, 2, np.nan, 4, 5],
'B': [6, np.nan, 8, 9, 10],
'C': ['Dog', 'Cat', 'Dog', np.nan, 'Dog']}
df = pd.DataFrame(data)
# Print the original dataset
print("Original Dataset:")
print(df)
# Mean imputation
df['A'].fillna(df['A'].mean(), inplace=True)
# Median imputation
df['B'].fillna(df['B'].median(), inplace=True)
# Mode imputation
df['C'].fillna(df['C'].mode()[0], inplace=True)
Drawbacks of using mean/median/mode imputation
Mean/median imputation has three main flaws that prevent it from becoming an effective univariate numerical imputation method.
Mean and median imputation can also distort the statistical properties of the data, such as the variance and covariance.
Mean and median imputation can be time-consuming and may not be practical for large datasets with a large number of missing values.
Mean and median imputation may not be appropriate if there will be some outliers, as the mean and median are sensitive to outliers and may not accurately represent the central tendency of the data.
Filling missing values using an arbitrary value
Arbitrary value imputation is a unique technique used to replace missing values with a pre-defined arbitrary value such as -999, -1, or any other value that can be easily identified as imputed. We use this technique when the data is not MCAR in other words we can say that we use this technique when the data is Missing not at random.
However the major drawback of this technique is that it can introduce bias in the dataset, as it alters the original distribution and relationships within the data. This bias can affect subsequent analyses and modeling results.
Code implementation
import pandas as pd
import numpy as np
# Create a sample dataset with missing values
data = {'A': [1, 2, np.nan, 4, 5],
'B': [6, np.nan, 8, 9, 10],
'C': [11, 12, np.nan, np.nan, 15]}
df = pd.DataFrame(data)
# Perform arbitrary value imputation
arbitrary_value = -999
df_imputed = df.fillna(arbitrary_value)
Which technique to apply finally ?
There is no fixed answer for this question, but I can tell you what I normally do. Basically I simply create 2 copies of the dataframe one for removing the missing values and other for imputing the missing values. After donig so for all the numerical columns I compare the change in distribution and choose that technique using which the distribution is not changing a lot.
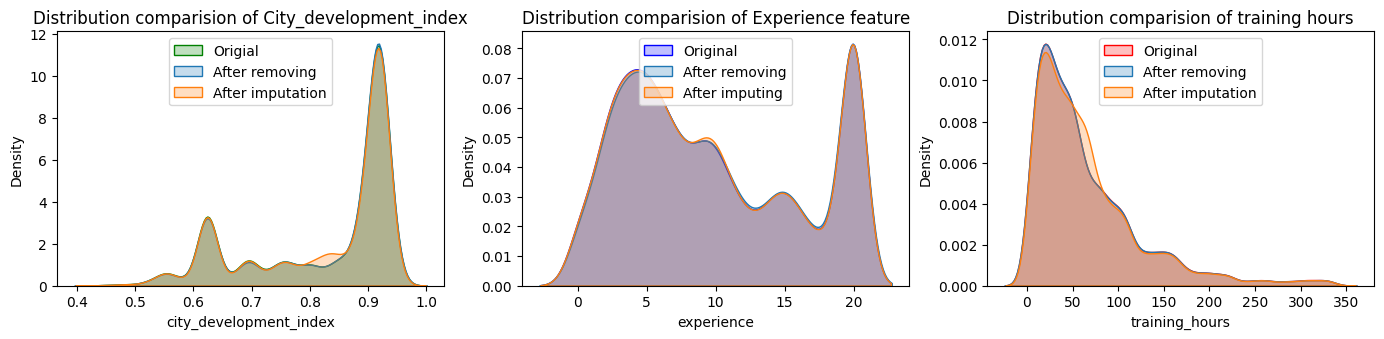
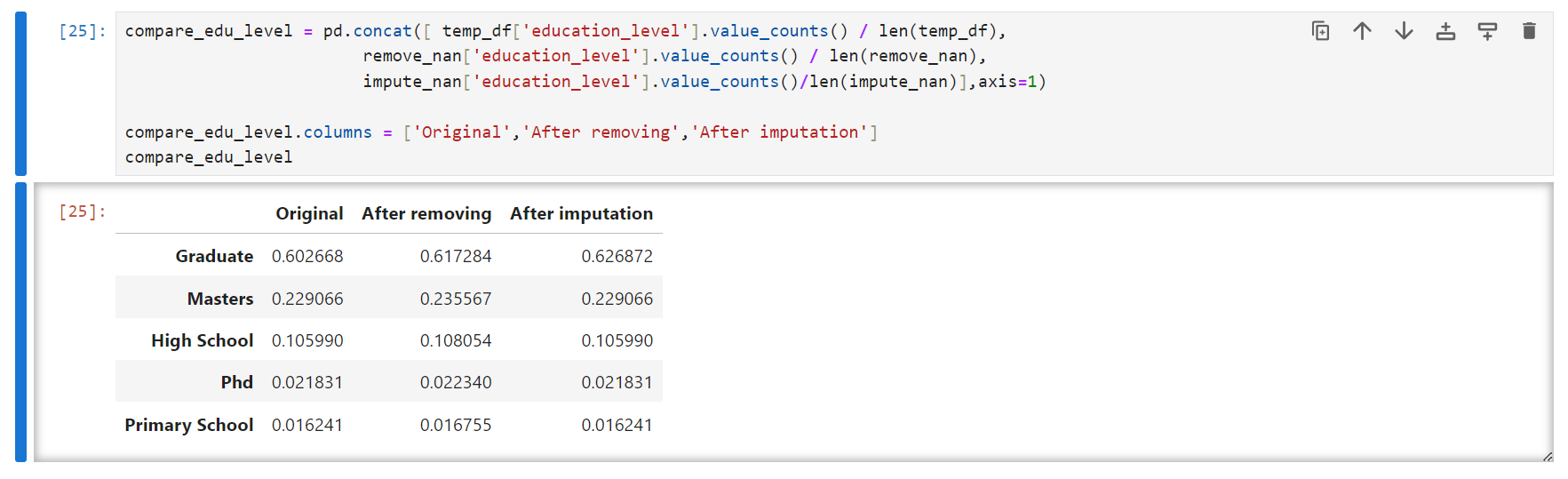
One additional thing which we must keep in mind is that, if the missing value are categorical, in such a scenario, the ratio of each category before and after the removal of missing values must be the same.
Short note
I hope you good understanding of what is feature scaling, how to implement the technique using python code and when to use which technique so if you liked this blog or have any suggestion kindly like this blog or leave a comment below it would mean a to me.
Subscribe to my newsletter
Read articles from Yuvraj Singh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Yuvraj Singh
Yuvraj Singh
With hands-on experience from my internships at Samsung R&D and Wictronix, where I worked on innovative algorithms and AI solutions, as well as my role as a Microsoft Learn Student Ambassador teaching over 250 students globally, I bring a wealth of practical knowledge to my Hashnode blog. As a three-time award-winning blogger with over 2400 unique readers, my content spans data science, machine learning, and AI, offering detailed tutorials, practical insights, and the latest research. My goal is to share valuable knowledge, drive innovation, and enhance the understanding of complex technical concepts within the data science community.