Outliers in Machine Learning: What You Need to Know
 Yuvraj Singh
Yuvraj SinghTable of contents

I hope you are doing great, so today we will discuss an important topic in machine learning handling outliers. After going through this blog you will be completely aware about what are outliers, why we even need to handle them, what could be the reasons behind their presence and what are the types of outliers and in the next blog we will discuss all the ways to visualize and deal with them, but for this blog without any further dealy let's get started.
Introduction to Outliers
Out of all the projects I have completed thus far, I have encountered outliers in almost every one. In the following discussion, we will explore techniques to handle outliers. However, I want to share my experience to emphasize that when working with custom datasets instead of relying on Kaggle datasets, you will likely encounter outliers consistently. Before delving into methods to identify and address outliers, let's first clarify what outliers are.
Outliers are instances or data points that signifincantly different from the other data points in our dataset. To gain a clearer understanding of this definition, please refer to the diagram below
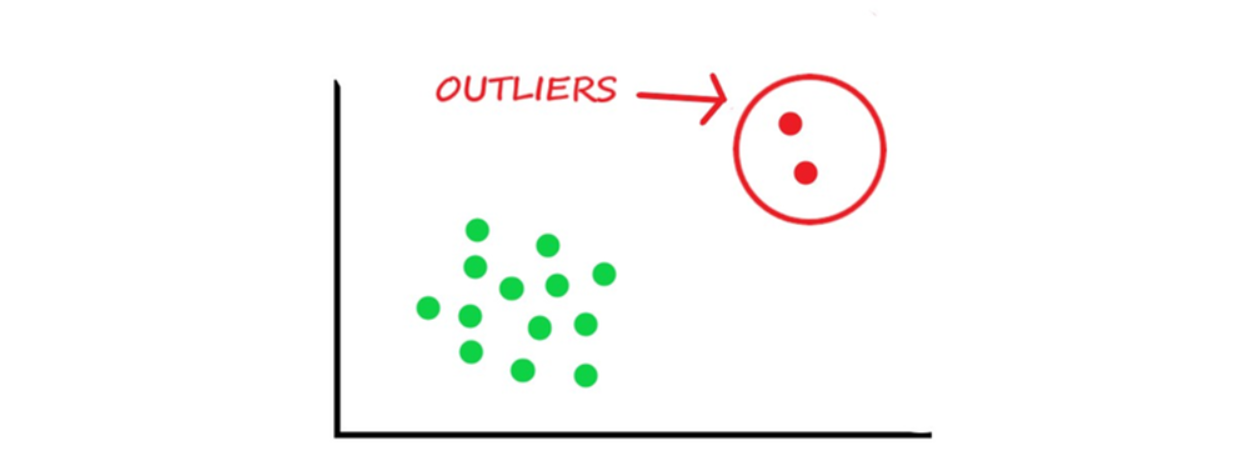
Common Causes of Outliers
It is crucial to have an understanding of the reasons behind the presence of outliers in our dataset in order to handle them effectively. Without knowledge of the reasons, employing incorrect techniques may result in the loss of important information. Therefore, let's explore all the possible reasons behind the presence of outliers in our data.
Reason 1 : Measurement errors
One of the most common reasons for the presence of outliers in our dataset is measurement errors. For example, let's consider a scenario where a sensor is designed to measure the moisture level within a range of 0% to 100%. However, if the sensor malfunctions, it might generate inaccurate readings that deviate from this range. These erroneous readings could be excessively high or low, which does not reflect the actual moisture levels in the environment.
Reason 2 : Data entry errors
Even if our data collection process goes smoothly, there is still a possibility of outliers being introduced into our dataset, often due to data entry errors. These errors occur when human operators or automated systems incorrectly enter or record data. Here's an example to illustrate the impact of data entry errors:
Let's consider a scenario where a company is gathering data on the ages of its customers. During the data entry process, which involves manual input by employees, a data entry operator accidentally enters 350 instead of the correct age of 35 for a customer. Similarly, they mistakenly enter 8 instead of 28 for another customer.
Reason 3 : Natural variation in the data
Natural variation in data is another factor that can contribute to the presence of outliers. Natural variation refers to intrinsic variability within the data. Here's an example to illustrate how natural variation can result in outliers:
Let's consider a scenario where we want to determine the average salary of employees in a company. In this situation, it is expected that most employees will have salaries within a similar range. However, there may also be a few high-ranking executives or top-performing employees who earn exceptionally high salaries. These high salary values would be considered outliers within the dataset due to the natural variation in salaries.
Reason 4: Data processing issues
Not being conscious of the techniques used for data processing can also result in the introduction of outliers in our dataset. To better understand this, let's consider a scenario where we are addressing missing values in a particular feature using mean imputation. However, after imputing the missing values with the mean value, we suddenly observe a significant presence of outliers in that feature.
The introduction of outliers occurred due to a significant change in the data distribution. It's important to remember that using simple univariate imputation techniques for features with more than 5% missing values can lead to a substantial alteration in the distribution, consequently introducing outliers.
Why to even focus on outliers ?
If you are aware of a disease, you automatically look for a cure. Similarly, before delving into our discussion on how to deal with outliers, let's first understand why we should focus on outliers. There are several important reasons that compel us to handle outliers, including:
Outliers impact the statistical power of our analysis.
Outliers significantly hinder the performance of machine learning algorithms such as KNN, linear regression, and more.
Outliers make it difficult to assess the performance of algorithms using regression evaluation metrics such as MAE, MSE, or RMSE.
Types of Outliers
Global Outlier
A global outlier, also known as a univariate outlier, is an observation that is significantly different from all other observations in a dataset. It is an extreme value that stands out from the rest of the data points. Here's an example:
Suppose you have a dataset of housing prices in a city, and most of the prices range between $200,000 and $500,000. However, there is one house listed at $2 million. This house's price is much higher compared to all the other prices in the dataset, making it a global outlier.
Conditional Outlier
A conditional outlier, also known as a contextual outlier, is an observation that is unusual when considering a specific condition or context. It may not be an extreme value in the entire dataset, but it stands out within a particular subgroup or condition. Here's an example:
Consider a dataset of student scores on a math exam. The scores range from 0 to 100, and most students' scores fall between 60 and 80. However, within a specific subgroup, such as students who attended extra tutoring sessions, one student scored 95. This score is significantly higher compared to the scores of other students who attended the tutoring sessions, making it a conditional outlier within that subgroup.
Collective Outlier
A collective outlier, also known as a contextual outlier, is a group of observations that collectively deviate from the expected behavior or pattern in a dataset. It involves multiple data points that, when considered together, exhibit an unusual pattern. Here's an example:
Imagine a dataset representing daily temperature readings in a city over a year. Most of the temperatures range between 10°C and 30°C, which is typical for that location. However, during a heatwave, there is a week where the temperatures consistently reach 40°C or above. This collective increase in temperatures during that specific period stands out from the overall pattern, making it a collective outlier.
Short Note
I hope you good understanding of what are outliers, why even focus on them, reasons behind their introduction and also types of outliers so if you liked this blog or have any suggestion kindly like this blog or leave a comment below it would mean a to me.
Subscribe to my newsletter
Read articles from Yuvraj Singh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Yuvraj Singh
Yuvraj Singh
With hands-on experience from my internships at Samsung R&D and Wictronix, where I worked on innovative algorithms and AI solutions, as well as my role as a Microsoft Learn Student Ambassador teaching over 250 students globally, I bring a wealth of practical knowledge to my Hashnode blog. As a three-time award-winning blogger with over 2400 unique readers, my content spans data science, machine learning, and AI, offering detailed tutorials, practical insights, and the latest research. My goal is to share valuable knowledge, drive innovation, and enhance the understanding of complex technical concepts within the data science community.