Pre-Warming The Direct Lake Dataset For Warm Cache Import-Like Performance
 Sandeep Pawar
Sandeep PawarWhen using the Direct Lake dataset, query performance primarily depends on whether the columns are cached in memory. If the dataset has not been framed, there will be nothing in the cache, meaning you are encountering a cold cache. In this state, the AS engine sends the query to Delta Lake, transcodes the columns, and loads them into memory. Import mode with Large Dataset Format dataset has an on-demand caching behavior which also has cold and warm cache [1]. The query performance of Direct Lake dataset in a cold cache state can be same or worse than in import mode, depending on factors such as the delta table, dataset size, cardinality, and the specific query. Once the columns are in memory, subsequent query performance becomes significantly faster, similar to warm cache import mode. For instance, I recently published an article demonstrating that for a 600 million row TPCH_SF100 dataset, a cold cache query took around 40 seconds in Direct Lake mode, while the same query in warm-cache mode was completed in under a second.
The first user who queries the report connected to a Direct Lake dataset in a cold cache state may potentially experience a long wait time to obtain the results. This can possibly be improved by pre-warming the Direct Lake dataset, meaning we load the required columns into memory before the first user interacts with the report. I will use a single table (lineitem table from the TPCH_SF100 dataset) as my example. I will provide Direct Lake vs import cold cache performance results in a future blog.
It's important to note that Fabric is still in preview. The options and performance will most definitely change in the future. Neither Fabric nor Direct Lake are ready for production while in public preview so below is more of an academic investigation/discussion of what's possible. I will update the blog as and when new features/updates are available.
Cold Cache:
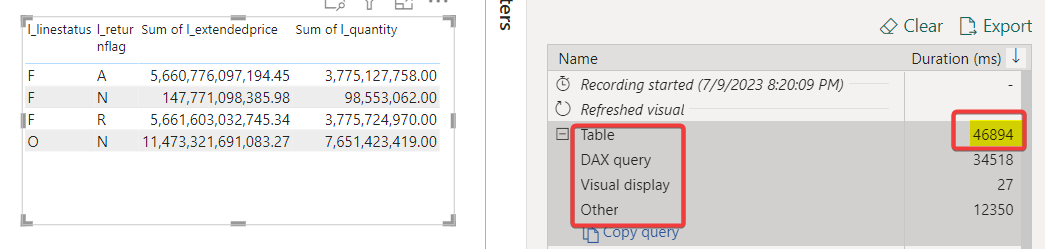
In cold state, the Direct Lake dataset only stores the metadata and not the data. I framed the dataset to drain any cache and refreshed the visual in Power BI Desktop. It took 47 s to get the results in Direct Lake mode.
Pre-Warming The Cache:
There are many ways to achieve this but I will be using the REST API to query the four columns I need. I queried the required columns using the ExecuteQueries REST API using Python in the Fabric notebook. To generate REST API tokens, I used the code Gerhard Brueckl shared on Twitter.
import requests
from notebookutils import mssparkutils
def execute_powerbi_query(dataset_id, query):
"""
Sandeep Pawar | Fabric.guru | July 9, 2023 | v1
Execute a DAX query against a Power BI dataset.
Args:
dataset_id (str): The ID of the dataset to query.
query (str): The DAX query to execute.
Returns:
dict: The JSON response from the Power BI API.
"""
# Obtain the Power BI API token
# source : https://twitter.com/GBrueckl/status/1673305659624833024?s=20
url = "https://analysis.windows.net/powerbi/api"
token = mssparkutils.credentials.getToken(url)
if not token:
raise ValueError("Could not obtain Power BI API token")
# JSON body for the API request
json_body = {
'queries': [
{
'Query': query,
'QueryType': 'Data'
},
]
}
# Headers for the API request
headers = {"Authorization": "Bearer " + token}
# API request
try:
response = requests.post(f"https://api.powerbi.com/v1.0/myorg/datasets/{dataset_id}/executeQueries",
headers=headers,
json=json_body)
# Raise an exception if the request was unsuccessful
response.raise_for_status()
except requests.exceptions.RequestException as e:
print(f"Request failed: {e}")
return None
# Parse the as JSON
content = response.json()
return content
I retrieved the count of string columns and the sum of numeric columns, loading these four columns into memory.
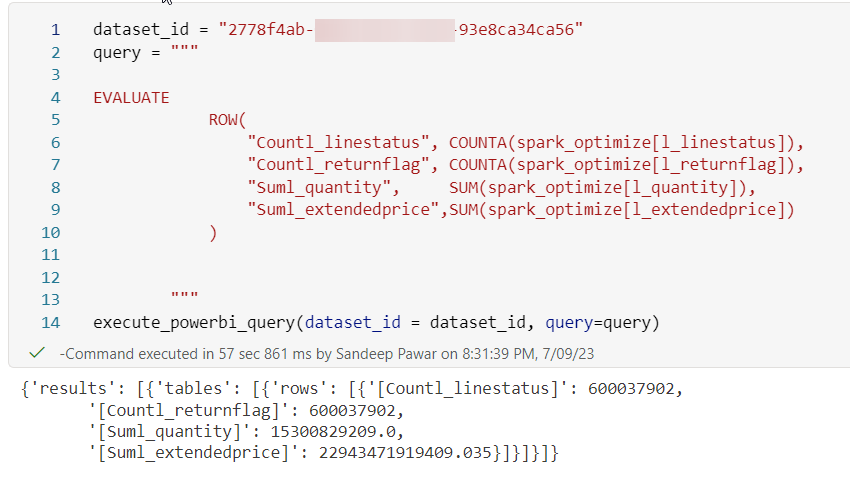
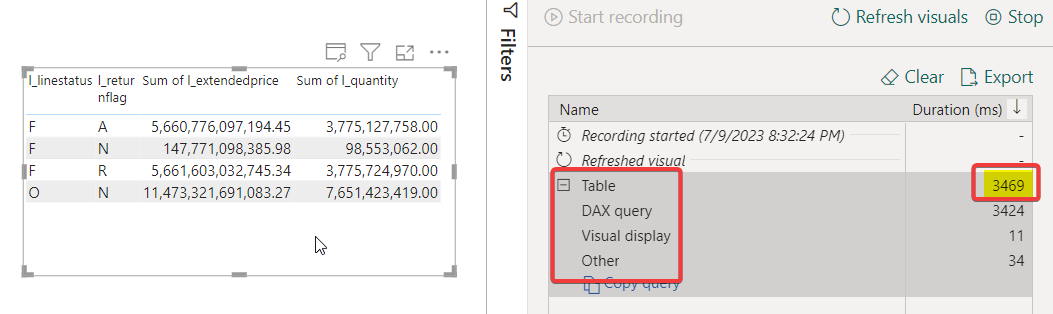
Upon executing the above query in the notebook, the column segments were cached in memory. As a result, querying the same visual in the Power BI report ran faster, taking only 3.4 seconds instead of the initial 47 seconds. This improvement was possible because the columns were already loaded in memory. Any user who interacts with the report after pre-warming the cache will experience lower query latency.
Which Columns To Cache?
I briefly mentioned this in my Direct Lake FAQ blog but Chris Webb has written about it in excellent detail. You can run the DMV to identify which columns are queried frequently using the temperature. You can also use this reportGilbert Quevauvilliers created to identify "hot" columns. You would cache the few most frequently used columns. Note that if you have two tables related to each other, you will have to cache the key columns as well.

You can also use fabric.list_columns(workspace, dataset, extended=True) to get columns cached in memory.
How To Use This?
For the custom Direct Lake dataset, if auto-sync is on, it will automatically fetch the latest data if the data or the schema changes. It is my understanding, I need to do more tests to confirm, the dataset will be framed and will be in a cold state after the auto-sync happens. If the delta lake is updated very frequently, it won't be practical to use this method. However, if you turn off auto-sync and refresh the dataset manually, you can run the above code in a notebook in the pipeline right after the delta lake has been loaded and the dataset has been refreshed. All we are doing is preemptively querying the dataset so that the user experiences import-like performance. Default dataset cannot be refreshed so this is only applicable to custom datasets.

Other Methods:
Dataflow
Instead of using the notebook, you can also query the dataset with the Analysis Services connector in a dataflow. You can opt for the standard Gen 1 dataflow instead of Gen 2, as we are not saving the data to OneLake. Mim has written a blog on how to accomplish this. You can add the dataflow to your pipeline following the dataset refresh step.
XMLA End point
The ExecuteQueries API has some limitations regarding the number of rows, data size, etc. In our case, we only need to query the columns and not run the actual DAX, so it should be fine. However, if you need to run a large query, you can use the XMLA endpoint, as I have described in my blog.
SemPy
SemPy, which is currently in private preview, will also be able to provide this functionality in Fabric notebooks seamlessly without using any API. I can't provide specifics while it's in private preview so I will update the blog post when it becomes available.
Michael Kovalsky (PM, Fabric CAT) shared a script in his repo to identify the columns cached in memory before the Direct Lake semantic model is refreshed and then caches them cack again after the refresh:
Summary
Hopefully, none of this will be necessary after the GA release - cold cache performance should improve significantly, Fabric will intelligently cache based on usage or do efficient memory swap/pinning etc. However, if it doesn't, you can pre-warm the Direct Lake cache according to usage, offering warm cache import-like performance to users. I presented a simple example based on a single table, but I understand that it will be more challenging for complex models, datasets with numerous live connected reports, and reports with multiple visuals; it's certainly not trivial. If you have better ideas or suggestions, please feel free to share them.
Thank you to Tamas Polner, Christian Wade at Microsoft for reviewing the blog.
References
Comprehensive Guide to Direct Lake Datasets in Microsoft Fabric
Share Data from a PowerBI Dataset using Dataflow – Project Controls blog (datamonkeysite.com)
Learn about Direct Lake in Power BI and Microsoft Fabric - Power BI | Microsoft Learn
Change Log:
- I updated the blog post because I was reminded that import also has cold and warm cache. For a fair comparison, the performance of a pre-warmed Direct Lake dataset should be compared with that of a warm cache import dataset. In a perfect scenario, cold/warm cache DL performance should match the cold/warm cache import dataset.
Subscribe to my newsletter
Read articles from Sandeep Pawar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Sandeep Pawar
Sandeep Pawar
Principal Program Manager, Microsoft Fabric CAT helping users and organizations build scalable, insightful, secure solutions. Blogs, opinions are my own and do not represent my employer.