Understanding how dedicated & shared tool memory works in SuperAGI
 Akshat Jain
Akshat Jain
SuperAGI tools enable developers to extend agent capabilities, helping them accomplish specific tasks beyond the default LLM’s scope.
For example, the CodingTool is capable of writing, evaluating, and refactoring code, while the GoogleSearchTool allows agents to crawl Google search results and extract useful findings.
Tools can access the memory of other tools to implement the knowledge and learnings into their own working - Improving the quality of the agent’s output.
🧠 Dedicated and Shared Tool Memory
Having a dedicated memory for each tool allows them to access the memory of their own past iterations and apply the learnings accordingly in future runs.
Tools are also equipped with a larger Shared Memory (a Vector DB) which allows them to interact with other tools and access relevant information required to complete the goals.

⚙️ How does this work?
During every run, SuperAGI agents can access various tools to achieve their goals through multiple iterations.
Upon completion of each iteration, tools can either fetch the latest memory used by another tool or retrieve data points from its own dedicated memory across all previous iterations. This process is defined as a “Feed Memory” - where an agent can access the learnings of tools across all iterations within an agent run.
For instance, If an agent is created with access to SearchTool —> WriteToFile —> CodingTool to achieve a goal. Then during a run, the CodingTool can fetch the memory of the last search results performed by the ‘SearchTool’ directly to write the code. The “Feed Memory” also allows the SearchTool to fetch the memory of any former iterations of itself i.e., if there were 3 iterations of SearchTool then the memory of the first iteration can be fetched to help the agent perform better.
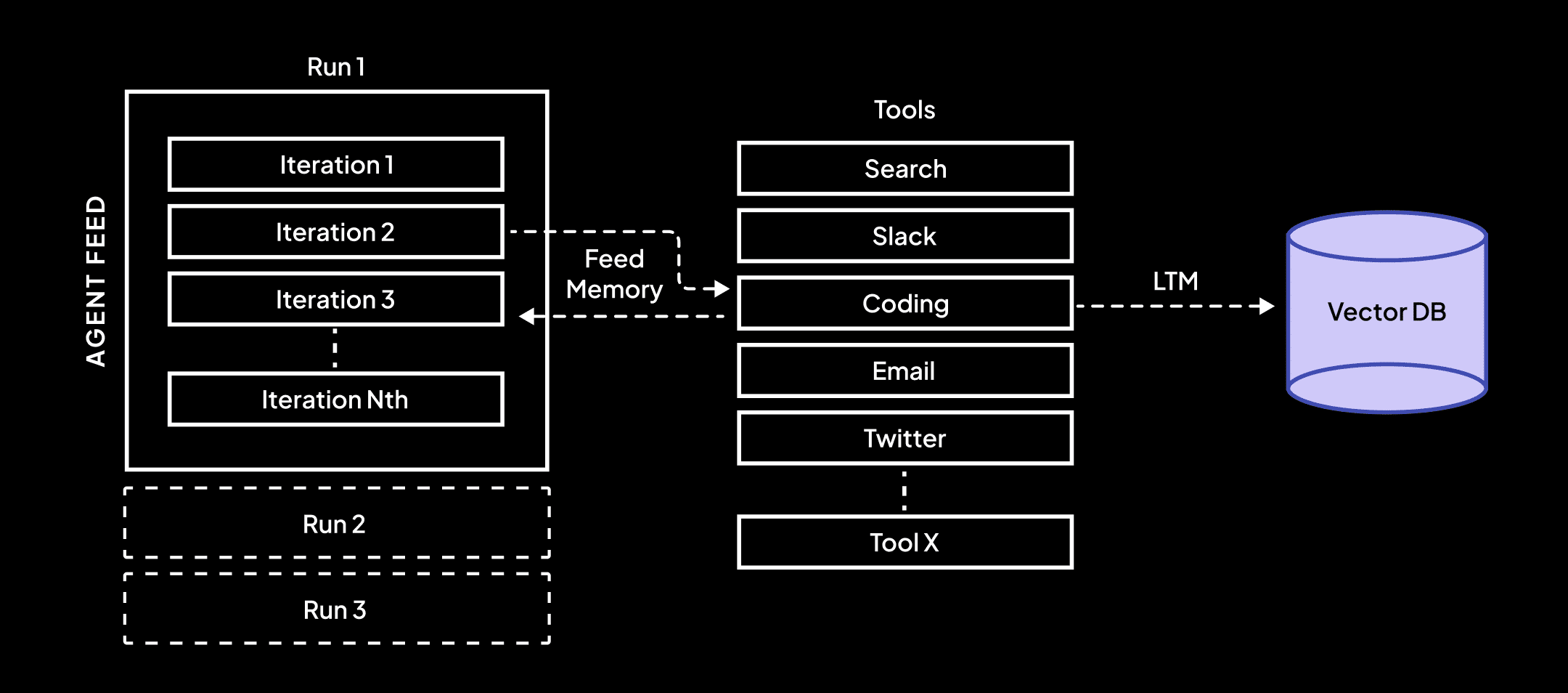
Tools can also query the Long-Term-Memory(LTM) of previously used tools both within and across runs providing output history from previous runs.
Long-term memory allows the tools to store the learnings of any other tool and itself throughout the whole agent workflow.
For instance, If an agent is created with access to CodingTool —> WriteToFile —> GitHubTool. The WriteToFile can access the memory of any iterations of the CodingTool. Once the initial agent run is completed, the overall learning of each tool used in the run including all previous iterations will be stored in LTM. And these learnings can later be accessed and utilized during future agent runs within an agent workflow.
✨ Conclusion
The traditional CoT (Chain of Thoughts) method passes very limited context to the next step between each agent iteration. However, when the requirement arises to pass the entire memory of a tool to the next iteration, the performance of CoT tends to be sub-optimal.
The latest advancements in SuperAGI tool architecture aim to eliminate these limitations, enhancing the memory interfacing capabilities of the tools while using SuperAGI.
Original Source: https://twitter.com/mukundns/status/1675928445170368512
Subscribe to my newsletter
Read articles from Akshat Jain directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by