Hadoop Architecture (Part 2)
 Anuj Kumar
Anuj Kumar
Hadoop Architecture (Part 1): Recap
In the world of big data processing, MapReduce is a powerful computing paradigm that enables distributed data processing. It consists of two phases - Map and Reduce - which provide parallelism and aggregation capabilities. The use of a consistent hash function ensures efficient data distribution, while the optional combiner component reduces data transfer time.
Introduction
Hadoop HDFS (Hadoop Distributed File System) is a distributed file storage system designed to handle large-scale data processing across clusters of commodity hardware. As a fundamental component of the Hadoop ecosystem, HDFS provides a reliable and scalable solution for storing and processing vast amounts of data.
The key principle of HDFS is its ability to store data in a distributed manner, spanning multiple machines or nodes in a cluster. This distributed storage approach offers several advantages, including fault tolerance, high availability, and efficient data processing.
In HDFS, data is divided into blocks and replicated across multiple nodes in the cluster. Each block is replicated to multiple nodes to ensure data durability and fault tolerance. The replication strategy allows for continuous data availability, even if some nodes fail or become unavailable.
HDFS follows a master-slave architecture, where the NameNode acts as the master and manages the file system namespace and metadata, while the DataNodes serve as slaves and store the actual data blocks. The NameNode keeps track of file locations, manages access permissions, and orchestrates the data read and write operations.
So, let's deep dive into it with the help of the below content.
Hadoop Distributed File System (HDFS)
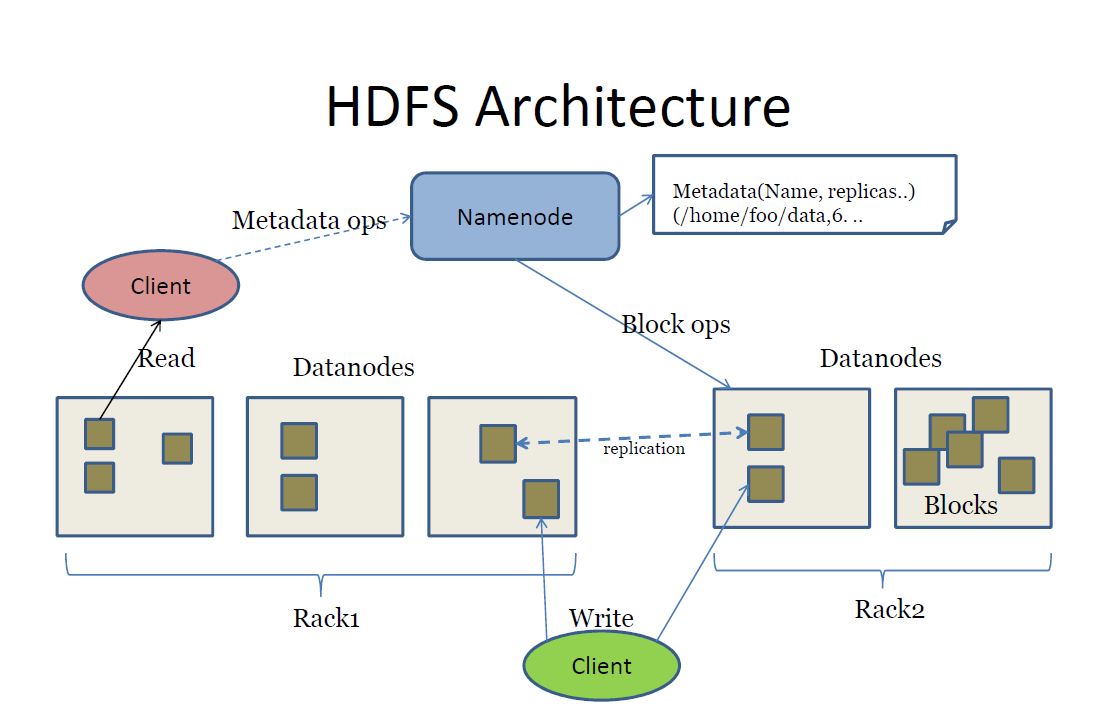
(I) Let's say we have a four-node cluster and suppose a very big file of 500MB.
(II) The file's size is bigger than the individual node's storage, even if it is possible to store it in one node then also we shouldn't do that will result in a monolithic system.
(III) We will divide the block into four parts and will be stored in nodes
Why only 4?
Ans. The number of blocks depends on the block size
Hadoop 1 had a block size of 65 MB
Hadoop 2 has a block size of 128 MB
(IV) Master nodes will have the records of all the block, Master nodes/name node stores the metadata of what is kept and where it is kept.
All the node where data is stored is named data node.
(V) Request made by client node will always go to name node as it has the metadata of all the DN's. Then the name nodes will check and give the info back to the client and then client nodes will have access to DN's (All these are background processes).
{ Data nodes are made of commodity hardware (cheap hardware) just to keep the cluster's price low }
(VI) Thus this machine can fail very frequently as the name node is made up of high-quality hardware thus chances of getting fail is very low.
Case 1: What if the Data node goes down?
If the data node (DN1) goes down then it will be lost, to recover this we have the Replication factor and default replication factor for Hadoop is 3.
All the replicas won't be kept on the same machine, we would be foolish if we store it on the same machine and lose the data again.
The name node table should have the details of the replica too and it should be updated every time the changes go in.
we can change the RF (done by the Hadoop admin)
How we will come to know that the data node is failed?
Ans. By Heartbeat
[A] Each data node sends heartbeats to the name node every 3 seconds.
[B] If the name node doesn't receive 10 consecutive heartbeats, it assumes that the data node is dead or running very slowly (30 seconds).
Then marks it for deletion (it has to be removed the entry from the metadata table)
Fault Tolerance
If the data node goes down, the replication factor comes down to <3 and then the name node will create one more copy to maintain the replication factor.
Failure management of a name node
In Hadoop version 1 the name node was a single point of failure (all communication will stop).
In Hadoop, version 2 the name node wasn't the single point of failure.
There was no down time, things will work like how it was earlier
Case 2: Name node failure
Name node fails means no access to the metadata table, which means "no access to cluster/data node"
Problem: We will loosen the blocks mapping info
If we have the latest block mapping information (metadata) then we can make sure there is no downtime involved
There are 2 imp metadata files
A. fsimage
For example, It is like a cricket scorecard which is a snapshot of the whole match(till 12 overs). Similarly, fsimage is a snapshot of the filesystem at a given moment
B. Edit logs
- All the new changes or transactions that happen after the snapshot is taken will come to the edit logs file (after 12 overs to 20 overs)
- To get the latest one we will merge these two fsimage+editlogs = latest fsimage. we need to merge it continuously (This process isn't easy, it is a very heavy computing process).
The name node shouldn't take the activity of merging these 2. As the name node is already busy doing a lot of things.
- Thus secondary name node comes into the picture.
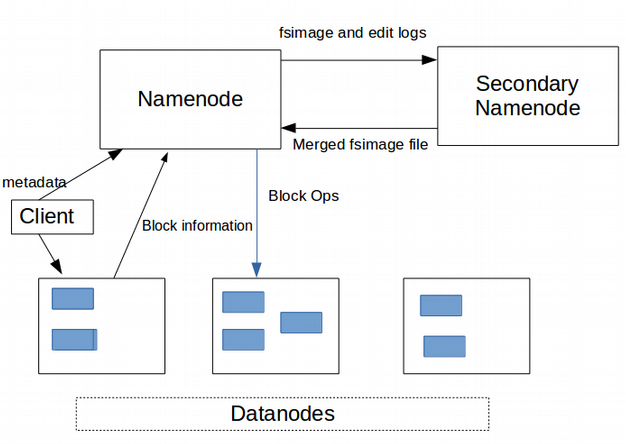
- The name node will put fsimage and edit lags continuously in a shared folder to which the secondary name node will have access.
- The new fsimage produced by SNN will overwrite the fsimage present in the shared folder.
The entire loop is known as checkpointing.
- SNN performs fsimage and edit logs merging to get newly updated fsimage and
this process repeats after every 30 seconds.
After the merging activity, fsimage and edit logs have to be empty otherwise same info/data will go into SNN twice or more no.of times.
At this point name node will fail then SNN will take the latest fsimage in memory and things will work normally.
At that time SNN --> NN (passive --> active)
Then Hadoop admin will have to create a new SNN
BLOCK
Block size 128 MB
Size can be changed
If we increase the block size
We will have less no.of blocks, resulting in lesser nodes.
Eg. a 500MB file, 4 nodes
Then it will use only 2 nodes and the remaining two will be of no use, which leads to the underutilisation of cluster
Decreasing blocks size
we will have more blocks
Eg. a 500MB file and a 4KB block size
It will lead to millions of blocks.
Huge amount of metadata that your name node has to handle, and this will overburden our name node.
So, the block size should neither be too high and should neither be too low.
- 128MB is a good size in most cases.
How replicas are placed?
Rack means the group of systems placed in different geographical locations.

Replica pipeline
Name nodes store data blocks in the data node of a rack.
The first copy goes to the nearest rack available to us.
The replicas of the data block are forwarded to new locations.
Forwarding data blocks within the same rack requires a small amount of n/w BW.
It Involves less i/p - o/p operations.
Rack failure: If we placed all replicas in single racks then there are high chances of data loss if the rack goes down.
Choosing multiple racks
- Each replica is placed in different racks is also not an ideal solution, as it will take a lot of time to get those blocks from different locations.
Rack awareness mechanism
The balanced approach is to place replicas in two different racks.
One replica in one rack and the other two in different racks or vice versa
(Adopted bec. to min write- B/W and max. redundancy)
Block report
Each data sends a block report to the name at a fixed frequency indicating if any blocks are corrupted.
Ways to achieve high availability of name node
(Availability + scalability)
High availability
The system is highly available, downtime is the least.
What will happen if we lose the edit logs as edit logs are kept at shared locations?
Journal node and Quorum come into place.
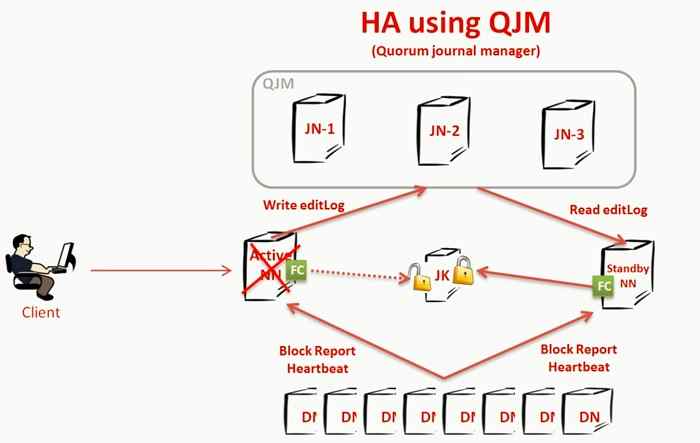
Journal node: Captures the edit logs from active NN.
Standby NN can check out.
- Whenever the active NN goes down it can build on the actual image with the help of edit logs.
- we can have multiple standby NN.
Let's say we have N no. of machines then the quorum can tolerate up to (N-1)/2.
Eg. 5 machines are there,
Tolerate: (5-1)/2 = 2 (upto to 2 machines)
- Scalability of name node
(A) If we have more DN then we have a lot of metadata thus our system will be bottlenecked by NN.
A single NN has to handle too much metadata.
(B) In the latest version of Hadoop we can have more than one name node.
(Not the passive NN, as it was for high availability)
There can be multiple NN that distribute or share the load.
Different NN can handle different namespace or different types of data
This concept is known as the "Name Node Federation".
Subscribe to my newsletter
Read articles from Anuj Kumar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Anuj Kumar
Anuj Kumar
Aspiring Big Data Engineer and enthusiastic tech blogger diving into the world of Big Data. Experienced in data integration and well-versed in the Big Data tech stack. Passionate about sharing insights and knowledge through blogging to empower others in the field. Excited to explore the endless possibilities of leveraging data to drive meaningful insights and create innovative solutions. Continuously learning and growing to stay at the forefront of the rapidly evolving Big Data landscape. Join me on this exciting journey as we unravel the power of data together.