Scaling Ethereum Securely: Exploring the Innovation of Optimistic Rollups and Fraud Proofs
 Emre Aslan
Emre Aslan
What happened the Ethereum?
With Bitcoin, people can send money to each other in a decentralized environment. They can also do that with Ethereum. In addition to sending money, can do lending, borrowing, staking process etc. (Dapps) with Ethereum. (DeFi - Decentralized Finance)
Users and developers loved Ethereum and developed and used millions of decentralized applications. Therefore, it would not be wrong to describe Ethereum as a world computer.
These complex transactions bring some huge problems. (Scalability)
Scalability refers to the ability of Ethereum to handle increased transaction volume and network growth without compromising its performance and efficiency. It involves implementing solutions and upgrades that enable the network to process a higher number of transactions per second, ensuring that Ethereum can effectively support a larger user base and accommodate future demands.
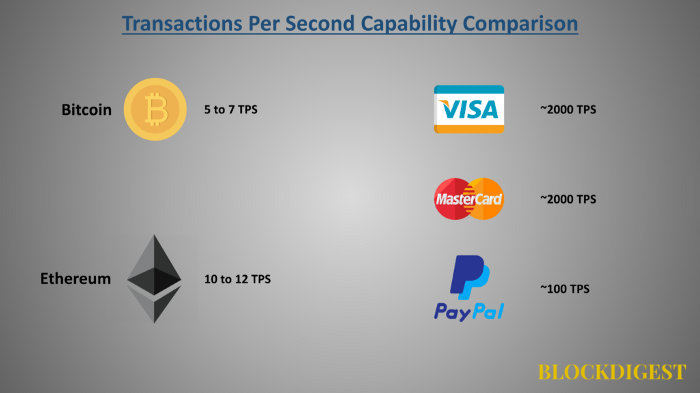
Bitcoin can do 5-7 transactions per second (TPS). When compared to centralized payment systems, blockchain systems provide lower tps. Furthermore, In owing to can be doing complex transactions, Ethereum must have the most TPS value. Since complex transactions are transactions that take up more space in blocks, it reduces the already low tps value.
Okay, I guess we understood what is the TPS and why need to increase it. Let's increase TPS in our blockchain now, shall we?
How can we increase TPS without not being centralized?
Blockchain technology, like its name, is based on the principle of creating a chain by arranging the blocks like a rope, and the information in this chain is downloaded and stored by everyone in the world, and the new blocks to be added to the chain are decided. Yes, that's what blockchain technology is all about.

Blocks store the transfer data. New transfers are written in new blocks. This is where the issue of transaction fees comes in.
Each block has a capacity. Blocks in Bitcoin have a size of 1MB. The transfer amount that 1MB of data can carry is 3,000 on average. Since each block spawns in 10 minutes:
3,000 transfers per block / 10 minutes block time = 300 minutes of transactions
If 300 transactions are made in 1 minute, 300/60=the number of transactions in 5 seconds.
Yes, TPS calculation is done this way. So just based on this information, we can say that two parameters limit:
the speed output time of blocks
the block size for blockchain
On the other hand, miners take transactions from the transaction pool called mempool and save them to the blockchain.
Let's start with basic questions. If the capacity of Ethereum is 5-7 TPS and I want to execute my tx immediately, I need to add to the blockchain quickly. My purpose is to be one of 5-7 transactions. If I can't be one of 5-7 transactions, the blockchain is slow.
So how do I become one of these 5-7 transactions right away? I said to the miner that I have a transaction and give extra ETH. The miner will add me to the front ranks and it will be added to the blockchain immediately. If everyone gives a lot of money and I have to give more. In such cases, blockchain is expensive.

Let's make almost every block 1GB and set the output time of the blocks to 1 second. Thus, very fast transactions can be made and can compete with traditional payment systems.
Unfortunately, no. It seems like suitable but lets think about it. I had said that blockchain nodes install all blockchain data and store it. As a result, in such a situation due to nodes need blockchain data, All nodes must have powerfull computer system, and fast internet speed. (DATA AVALIBILITY PROBLEM)
In addition, If some nodes have adequate hardware devices whereas some nodes have not enough equipment,blockchain's liveness is compromised. (LIVENESS)
I quess, we understood now. We can not increase block size or the speed output time of blocks. So, how we can create a scalable blockchain? Yes, we have a new topic: Scalability Solutions.
Rollups
In short, rollups say: "Give me complex transactions and I get things done on the outside of blockchain and give you back as a single transaction packet. Thus, we can fit millions tx into the small blocks."
For example, a user wants the create a complex transaction (any smart contract interaction) of 2,000,000 gas. Another user also wants the create a transaction of 1,000,000 gas. If these users execute their tx on rollup chains, they will not be stuck with the 15,000,000 gas block size limit in Ethereum and pay fewer transaction fees.
Rollups settle the transactions outside of the main Ethereum network but post the transaction data back to the Ethereum network and still derive its security from the Ethereum protocol. Each rollup has its specific contracts deployed on the main Ethereum network. Rollups executes the transaction off the chain mainly on a rollup specific chain and then batch the transaction data, compresses it, and sends it to the main Etheruem chain; this reduces the load on the main Ethereum network of actually processing those transactions.
So how exactly does a rollup work?
There is a smart contract on-chain which maintains a state root: the Merkle root of the state of the rollup (meaning, the account balances, contract code, etc, that are "inside" the rollup).
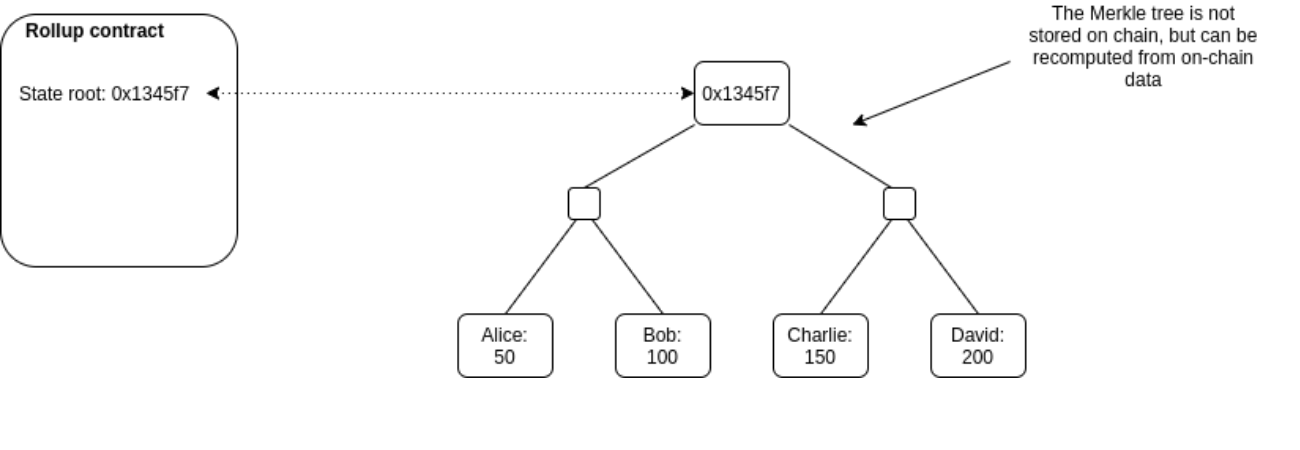
Anyone can publish a batch, a collection of transactions in a highly compressed form together with the previous state root and the new state root (the Merkle root after processing the transactions). The contract checks that the previous state root in the batch matches its current state root; if it does, it switches the state root to the new state root.
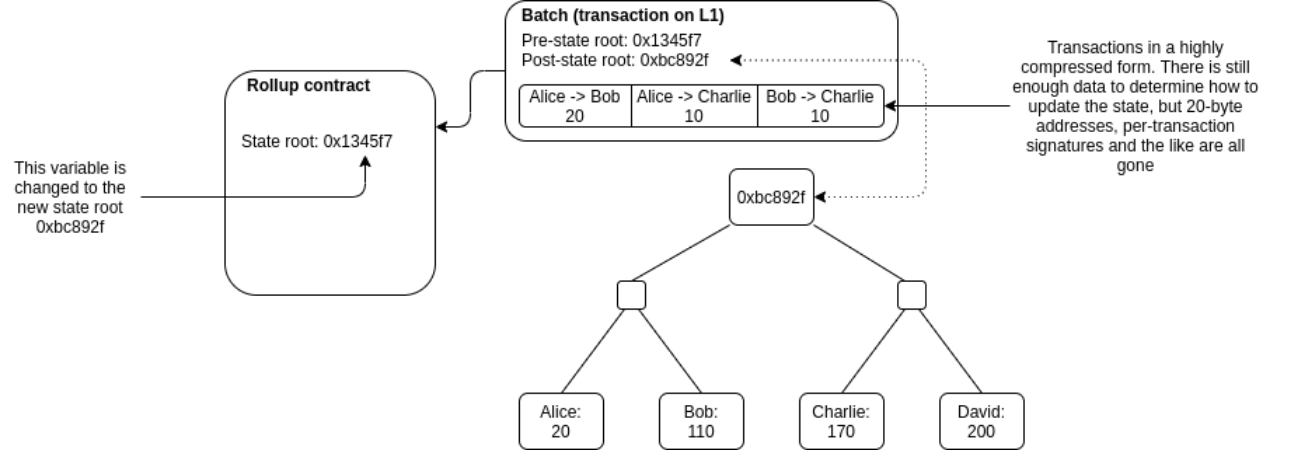
To support depositing and withdrawing, we add the ability to have transactions whose input or output is "outside" the rollup state. If a batch has inputs from the outside, the transaction submitting the batch needs to also transfer these assets to the rollup contract. If a batch has outputs to the outside, then upon processing the batch the smart contract initiates those withdrawals.
And that's it! Except for one major detail: how to do know that the post-state roots in the batches are correct? If someone can submit a batch with any post-state root with no consequences, they could just transfer all the coins inside the rollup to themselves. This question is key because there are two very different families of solutions to the problem, and these two families of solutions lead to the two flavors of rollups.
Types of Rollups
Rollups look like an up-and-coming solution to the Ethereum scalability problem, but how can we make sure that the transaction data posted on Ethereum by rollups is valid? Different rollup types handle this differently. There are two types of rollups based on this; Optimistic Rollups and ZK-rollups.
Optimistic rollups
Optimistic rollups, as the name suggests at first, assume that the transaction data submitted to the Ethereum network is correct and valid. Whenever there is an invalid transaction, there is a dispute resolution. A party submits a batch of transaction data to Ethereum, and whenever someone detects a fraudulent transaction, they can offer fraud proof against that transaction. Here both the parties, the one submitting the transaction data batch and the one submitting the fraud proof, have their ETH staked. This means that any misconduct from either party would result in loss of their ETH. Whenever a fraud proof is submitted, the suspicious transaction is executed again, this time on the main Ethereum network. To make sure the transaction is replayed with the exact state when it was originally performed on the rollup chain, a manager contract is created that replaces certain function calls with a state from the rollup.
Examples:
ZK-rollups
ZK-rollups or Zero-Knowledge rollups, unlike Optimistic rollups, don’t have any dispute resolution mechanism. It uses a clever piece of cryptography Zero-Knowledge proofs. In this model, every batch of transactions submitted to Ethereum includes a cryptographic proof called a SNARK ( Succinct Non-Interactive Argument of Knowledge ) verified by a contract that is deployed on the Ethereum main network. This contract maintains the state of all transfers on the rollups chain, and this state can be updated only with validity proof. This means that only the validity proof needs to be stored on the main Ethereum network instead of bulky transaction data, thus making zk-rollups quicker and cheaper comparatively.
Examples:
Since our topic is Optimistic Rollups, we will continue with Optimistic Rollups and Optimism, but please remember that the basic understanding is similar in all types of rollups.
Optimistic Rollups and Optimism
Firstly, since to explain Optimistic Rollups, I decided to talk about Optimism (OP). Optimism, Fuel and Arbitrum have different specific features but all optimistic rollups have the same infrastructure. So, we will talk about Optimism. Please don't worry about Fuel Network and Arbitrum.
Optimism currently has 2 types of nodes:
Sequencer
Verifier
The sequencer is responsible for collecting and ordering transactions within a batch. They create the batch of transactions and submit it to the Optimistic Rollup chain. The sequencer plays a key role in ensuring the efficiency and scalability of the system by bundling multiple transactions together.
On the other hand, the verifier is responsible for validating the transactions within the batch. They monitor the rollup chain and have the ability to submit a challenge if they suspect any fraudulent or incorrect transactions. The verifier acts as a watchdog, ensuring the accuracy and integrity of the transactions.
During the challenge period, the verifier can submit a fraud proof to dispute the validity of a transaction. If the fraud proof is valid and the transaction is found to be incorrect, the rollup protocol will rectify the error by re-executing the transaction and updating the block.
Both the sequencer and verifier play important roles in maintaining the security and efficiency of the Optimistic Rollup system. The sequencer ensures the smooth processing of transactions, while the verifier acts as a check to prevent fraudulent or incorrect transactions from being finalized. So, this two types of nodes are very important for continuing the article.
Let's look at basic general workflow:
Basic Workflow
The basic workflow is that users will send transactions to the sequencer, and the sequencer will process these transactions on its copy of the L2 chain.
Once processed, the sequencer will submit both the transaction data and the new L2 state root to L1.
Then, all other L2 nodes mentioned above will process the transaction on their copy of the L2 chain.
In order to ensure that the new state root submitted to L1 is correct, verifier nodes will compare their new state root to the one submitted by the sequencer.
If there is a difference, they will begin what’s called a fraud proof. The fraud proof will execute the L2 transaction but on L1 so that the resultant state root cannot be faked.
If the fraud proof’s resultant state root is different from the one submitted by the sequencer, the sequencer’s initial deposit (known as a bond) will be slashed. The state roots from that transaction onward will be erased and the sequencer will have to recompute those lost state roots correctly this time.
Once the sequencer role has been decentralized, if the sequencer’s bond gets slashed, a new sequencer will replace it.
The following diagram illustrates this basic workflow for steps 1–4.
Transactions
Transactions are divided into 2 parts:
Transactions on the L2 chain
Cross-chain transactions
L2 transactions occur between two addresses on the L2 chain and cross-chain transactions occur between the L1 and L2 chains.
Transactions on L2
Users will send transactions to the sequencer node and the sequencer will immediately add it to the L2 chain if it is a valid transaction (Note: at this point, only the sequencer node has added this transaction to its copy of the L2 chain). The block sizes for L2 are 1 transaction only, so immediately a new block is added to the chain with the new transaction. There are no miners competing for mining new blocks in L2 because the sequencer has replaced the miner functionality.
Then, after the sequencer has added a few transactions to the L2 chain, it will call a smart contract on L1 (deployed by the Optimism team before release) and send it the transaction data for all of those L2 transactions along with the new state roots of the L2 chain after applying each transaction.
The smart contract on L1 will store the transaction data and state roots in an efficient manner (rollups) in another smart contract designed for storage.
Once the transaction data has been stored on L1, the verifier nodes will include the transaction in their copies of the L2 chain.
If the sequencer is censoring a particular user, that user will be able to submit the transaction data and call the smart contract themself. The sequencer will then be forced to process that transaction within a certain time frame. If they don’t, their bond may be slashed.
Additionally, so far it has been mentioned that the verifier checks the transactions posted to L1 by the sequencer. However, verifiers can also choose to sync from L2, which means that they will get new transactions directly from the sequencer, possibly before they are posted to L1. This sync from L2 method reduces latency, but does not guarantee that the sequencer will post this transaction to L1.
Cross-Chain Transactions
Cross chain transactions are necessary in this system in order for users to be able to call contracts on other chains or to send ETH/tokens from one chain to another. These transactions have a slightly modified workflow than L2 transactions since they involve both chains.
L1 -> L2 Transactions
Transactions from L1 to L2 are quite fast and simply rely on the sequencer to relay the message to the L2 chain. User’s will send their transaction data to a bridge smart contract on L1 and this smart contract will add the transaction to the queue of transactions that the sequencer must add to L2 within a certain time frame. Therefore, the sequencer will eventually relay that transaction to the L2 chain.
For example, if a user wants to send 10 ETH to their address on L2 so that they can interact with smart contracts on L2, the following steps will happen:
The user sends 10 ETH to a bridge contract on L1.
The contract locks the ETH on L1.
The contract also adds the user’s transaction to the queue of transactions that the sequencer must add to L2.
The sequencer processes this transaction and the ETH is successfully deposited to the user’s L2 account.
Note: On L2, ETH has been replaced by a wrapped ERC20 token — WETH. This is to help the replayability of transactions on L1, which will be explained later. So, the transaction will deposit 10 WETH to the user’s L2 account.
L2 -> L1 Transactions
Transactions from L2 to L1 can be more complicated because in many cases the L1 chain must make sure that the L2 state root after the transaction (which originated on L2) is valid. Generally, the user will send the transaction to a specific smart contract on L2. Then a relayer will read it and send it to L1. Optimism has provided a javascript service that runs as the relayer. It uses the sequencer and verifier nodes to interact with L2.
To give an example of an L2 to L1 transaction, if a user wants to transfer their 10 WETH on L2 back to ETH on their L1 address, the following steps will happen:
The user sends 10 WETH to a bridge contract on L2.
The bridge contract burns the WETH and sends the transaction info to another smart contract known as the L2ToL1MessagePasser. This smart contract records the data for transactions that need to be sent from L2 to L1.
The relayer node reads this transaction data from the L2ToL1MessagePasser and waits for the fraud proof window (1-7 days) to complete before sending the transaction to L1.
The transaction is processed on L1 and the user can now withdraw their ETH. They will withdraw their ETH from the bridge contract that locked it when it was first sent to L2.
This fraud proof window gives verifier nodes enough time to identify if the state root posted by the sequencer is accurate for this transaction.
Fraud Proofs
Fraud proofs are a very important part of the Optimism system and they are what keep the sequencer honest. If the sequencer posts a fraudulent state root to L1, the verifier node can start a fraud-proof and execute the corresponding L2 transaction on L1. Then, the resultant state root from the fraud-proof can be compared to the state root the sequencer submitted to L1. If they are different, the sequencer’s bond will be slashed and the state roots from that transaction onward will be erased and re-computed.
Optimism Fraud Proofs types examine in two main headings:
Non-Interactive Fraud Proofs
Interactive Fraud Proofs
Non-Interactive Fraud Proofs
Non-interactive proofs are traditional proofs of optimism fraud. A user (verifier) catches assertions about the sequencer that sends a batch to L1. If the verifier thinks a party is wrong, it initiates a challenge. The batch is then recalculated at L1. This is the most basic explanation for non-interactive fraud proofs.
When a batch of transactions is submitted to the Ethereum mainnet through Optimism, there is a certain time window called the challenge period, during which anyone can challenge the validity of these transactions. If a transaction is suspected to be invalid, a non-interactive fraud proof can be used to prove its illegitimacy.
It's important to note that while Optimism relies on the Ethereum mainnet for security, the presence of non-interactive fraud proofs helps to mitigate the risk of fraud within the Optimistic rollup.
Interactive Fraud Proofs
The idea of interactive proving is that Alice and Bob will engage in a back-and-forth protocol, refereed by an L1 contract, to resolve their dispute with minimal work required from any L1 contract.
Arbitrum’s approach is based on dissection of the dispute. If Alice’s claim covers N steps of execution, she posts two claims of size N/2 which combine to yield her initial N-step claim, then Bob picks one of Alice’s N/2-step claims to challenge. Now the size of the dispute has been cut in half. This process continues, cutting the dispute in half at each stage, until they are disagreeing about a single step of execution. Note that so far the L1 referee hasn’t had to think about execution “on the merits”. It is only once the dispute is narrowed down to a single step that the L1 referee needs to resolve the dispute by looking at what the instruction actually does and whether Alice’s claim about it is correct.

The key principle behind interactive proving is that if Alice and Bob are in a dispute, Alice and Bob should do as much off-chain work as possible needed to resolve their dispute, rather than putting that work onto an L1 contract.
Conclusion
Thanks God. I guess, we achieve an increase in TPS a little more. Let's examine how much gas we have saved.
| Parameter | Ethereum | Rollup |
| Nonce | ~3 | 0 |
| Gasprice | ~8 | 0-0.5 |
| Gas | 3 | 0-0.5 |
| To | 21 | 4 |
| Value | 9 | ~3 |
| Signature | ~68 (2+33+33) | ~0.5 |
| From | 0 (recovered from sig) | 4 |
| Total : | ~112 | ~12 |
This is a fairly optimistic estimate, given that optimistic rollup transactions cannot possibly comprise an entire block on Ethereum. However, it can give a rough idea of how much scalability gains that optimistic rollups can afford Ethereum users (current implementations offer up to 2,000 TPS).
Important note: The main idea of the article is that I wanted to improve myself on recovery technologies and optimistic collections. In this post, I mixed a lot of optimistic rollup ingredients and made a delicious cake. That's why I read the articles of many developers, especially Ethereum resources, and hosted them in this article. Thanks to all developers and writers again.
Website: emreaslan.dev
Github: https://github.com/emreaslan7
Twitter: https://twitter.com/blockenddev
Linkedln: https://www.linkedin.com/in/emreaslan7/
Subscribe to my newsletter
Read articles from Emre Aslan directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Emre Aslan
Emre Aslan
Self Taught Dev and Content Writer