Cross-Validation Using K-Fold With Scikit-Learn
 Isheunesu Tembo
Isheunesu TemboImagine that you are a medical research scientist and your task is to find a cure for a particular disease , you perform experiments and test the drug on animals before you administer it to humans .
The same happens with machine learning we train the models , test them , then deploy them for real world use.
Learning the performance of a prediction function and testing it on the same data is a methodological mistake. A model would just repeat the labels of the samples that it has just seen would have have a perfect score but would fail to predict anything useful on yet unseen data , this situation is what we call overfitting. To avoid it , it is common to hold out part of available data as test set.
When evaluating different hyparameters for estimators such as the C setting that must be manually set for an SVM classifier , there is still a high risk of overfitting on the test set because parameters can be tweaked until the estimator performs optimally. This way , knowledge about the test set can “leak” into the model and evaluation metrics will no longer report on the generalization performance.
To solve this problem , yet another part of the dataset can be held as a “validation set”.
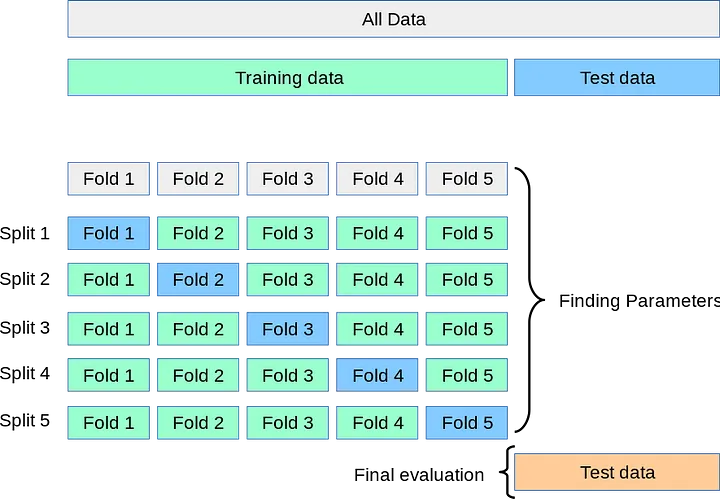
By partitioning data another problem arises which is we drastically reduce the number of samples which can be used for learning by the model , and the results can depend on a particular random choice for the pair (training , validation) sets.
A solution to this problem is a procedure called cross-validation , but the validation set is no longer needed when doing CV. Using an approach called K-fold , the training set is split into k smaller sets.
The following procedure is followed for each of the K-fold :
1 .A model is trained using K-1 of the folds as training data
2.The resulting model is validated on the remaining part of the data.
Let see a code example :
import numpy as np
import pandas as pd
import osfrom sklearn.datasets import load_iris
iris=load_iris()
X=iris.data
y=iris.targetX=(X-np.min(X))/(np.max(X)-np.min(X))
In [5]:
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test=train_test_split(X,y,test_size=0.3)
In [6]:
from sklearn.neighbors import KNeighborsClassifier
knn= KNeighborsClassifier(n_neighbors=3)
In [7]:
from sklearn.model_selection import cross_val_score
accuracies=cross_val_score(estimator=knn,X=x_train,y=y_train,cv=10)
accuraciesarray([0.83333333, 1. , 1. , 1. , 1. ,
1. , 1. , 1. , 1. , 1. ])print("average accuracy :",np.mean(accuracies))
print("average std :",np.std(accuracies))average accuracy : 0.9833333333333334
average std : 0.04999999999999999knn.fit(x_train,y_train)
print("test accuracy :",knn.score(x_test,y_test))test accuracy : 0.9555555555555556
GridSearch
from sklearn.model_selection import GridSearchCV
grid ={"n_neighbors":np.arange(1,50)}
knn= KNeighborsClassifier()
knn_cv=GridSearchCV(knn,grid,cv=10) #GridSearchCV
knn_cv.fit(X,y)rint("tuned hyperparameter K:",knn_cv.best_params_)
print("tuned parametreye göre en iyi accuracy (best score):",knn_cv.best_score_)tuned hyperparameter K: {'n_neighbors': 13}
tuned parametreye göre en iyi accuracy (best score): 0.98

What is K-Fold Cross Validation
K-Fold CV is where a given data set is split into a K number of sections/folds where each fold is used as a testing set at some point. Lets take the scenario of 5-Fold cross validation(K=5). Here, the data set is split into 5 folds. In the first iteration, the first fold is used to test the model and the rest are used to train the model. In the second iteration, 2nd fold is used as the testing set while the rest serve as the training set. This process is repeated until each fold of the 5 folds have been used as the testing set.
from sklearn.model_selection import KFold
scores=[]
kFold=KFold(n_splits=10,random_state=42,shuffle=False)
for train_index,test_index in kFold.split(X):
print("Train Index: ", train_index, "\n")
print("Test Index: ", test_index)
X_train, X_test, y_train, y_test = X[train_index], X[test_index], y[train_index], y[test_index]
knn.fit(X_train, y_train)
scores.append(knn.score(X_test, y_test))knn.fit(X_train,y_train)
scores.append(knn.score(X_test,y_test))print(np.mean(scores))0.9393939393939394cross_val_score(knn, X, y, cv=10)
You can watch my youtube tutorial on cross validation:
Thank you for reading the article , if you found it useful you can:
Buy me a coffee:https://www.buymeacoffee.com/isheunesu4Q
Follow me on:
Twitter:https://twitter.com/IsheunesuTembo
LinkedIn:https://www.linkedin.com/in/isheunesu-tembo-ab340b148/
Subscribe to my newsletter
Read articles from Isheunesu Tembo directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Isheunesu Tembo
Isheunesu Tembo
Hello my name is Ishe , l am a mobile application developer and machine learning developer .My passion is developing cutting edge tech that help the society and sharing the little knowledge that l have through blogging and making youtube tutorials